在6月15日理想汽车软件与具身智能发布会上,创始人李想高举一枚芯片,并幽默地发出请求:“给我拍张照片吧,记得在旁边标注这是全世界性能最强的AI芯片,否则网上留下的都是我举桌子的画面。”

这枚芯片正是发布会上亮相的全球首款动态数据流AI芯片——马赫M100。虽然当时场面颇为有趣,但其披露的技术参数更值得深入探究。
马赫M100采用5nm车规级工艺,单芯片算力高达1280 TOPS,使其成为目前全球量产的最强车规级推理芯片。更关键的是,得益于数据流架构设计,其实际运行效率超过82%。在芯片领域,这一数字远非标称参数所能比较,它直接决定了算力能够转化为多少真实性能。

从芯片布局看,马赫M100超过一半面积用于神经网络处理器——1280 TOPS算力全部来源于此。该部分由56个计算单元及一个数据处理模块组成,采用网格总线与数据环形总线双互联架构,数据流动到哪里,计算就在哪里触发。这种“随流而动”的设计思路与传统的CPU取指执行模式截然不同,大幅提升了算力利用率。
CPU部分由24颗A78AE组成,主频2.3GHz,并配备8路LPDDR5X子系统,带宽高达273GB/s。更值得关注的是,与目前智驾领域最主流的英伟达Orin相比,在基于CNN的骨干网络、UniAD以及理想马赫VLM核心模型的测试中,马赫M100均取得了数倍的性能领先。
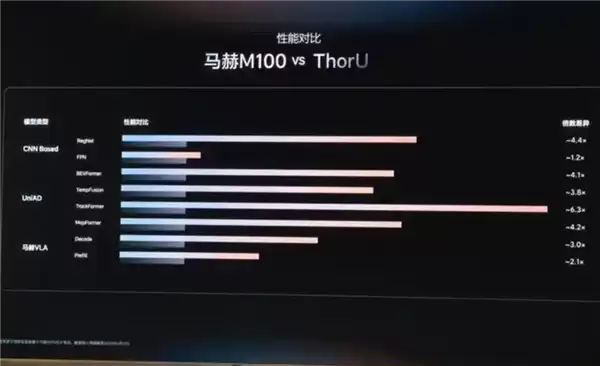
毋庸置疑,这组对比数据的含金量极高。它并非依赖堆料获得账面数字,而是凭借架构效率实现了真实的性能碾压。英伟达Orin在智驾领域的影响力不言而喻,马赫M100能在此级别对决中取得“数倍领先”的成绩,其背后的研发投入与架构创新,才是真正值得关注的重点。




