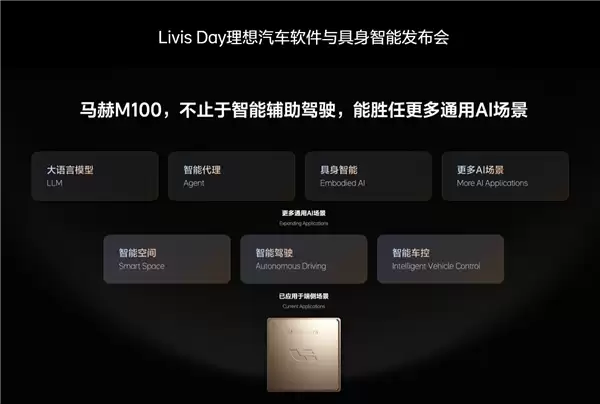
6月15日,理想汽车在Livis Day软件与具身智能发布会上,扔出了一枚重磅冲击波——全球首款数据流AI芯片马赫M100正式亮相。这颗芯片采用5nm车规级工艺,单芯算力达到1280 TOPS,实际运行效率超过82%,是目前全球量产最强的智驾级算力芯片。

说到这,得先聊聊背后的技术逻辑。冯·诺依曼架构统治计算行业整整70年,但它有个硬伤:指令队列虽然有序,却掩盖了计算本应有的并行度,大量晶体管被用来做管理开销,而非真正算力。而AI计算天然就是并行的——数据是张量、关系确定、流动路径清晰。既然路已经画好了,为什么还要在每一个路口设个红绿灯?理想的做法很直接:拆掉中央式指令队列,让数据流动来驱动计算发生,围绕AI计算形态原生设计数据流架构。
马赫M100就是这个思路的落地成果。它不只是一颗更快的芯片,更像是用完全不同的设计哲学,造了一座“完全不同的房子”。超过一半的芯片面积留给了神经网络处理器——1280 TOPS算力全在这里。具体由56个计算单元和一个数据处理模块构成,采用网格总线加数据环形总线双互联架构,数据流到哪里就在哪里触发计算。
CPU部分由24颗A78AE组成,主频2.3GHz,配备8路LPDDR5X子系统,带宽达273GB/s。把这些参数放到实际测试中,和全球智驾领域最主流的英伟达Orin直接对比:在CNN-based骨干网络、UniAD和理想马赫VLM核心模型测试中,马赫M100全部取得数倍性能领先。
但这不是全部。马赫M100的野心远不止智驾模型。理想在这颗芯片上部署了千问1.5B和3B通用大模型,然后和售价4万元的英伟达DGX Spark桌面超算进行了一场硬碰硬的对比:Prefill速度是后者的2.7倍,Decode速度是后者的1.5倍。一颗装在车里的芯片,硬是跑通了桌面级AI算力,这才叫真正的“降维打击”。
学术层面同样值得关注。马赫M100的架构论文已被ISCA 2026收录——这可是国际计算机体系结构领域最具影响力的顶级会议。理想汽车因此成为汽车行业第一家、历史上第一家在ISCA工业分会获得论文录取的企业。架构团队将于6月30日在会议现场进行主题分享。这片小小的芯片,不仅是工程上的突破,更是学术圈的一次正式认可。




