谷歌Gemini像素操控解析:DeepSeek-OCR2技术回应

新智元报道
编辑:定慧
【新智元导读】谷歌Google DeepMind刚刚推出新能力,用代码赋予Gemini 3 Flash「法眼」。
没想到吧,Google DeepMind刚刚为Gemini 3 Flash推出了一个重量级新能力:Agentic Vision(智能体视觉)。(难道是被DeepSeek-OCR2给刺激到了?)
可以看到,这项技术彻底改变了大语言模型理解世界的方式:
从过去的「猜」变成了如今的「深度调查」。

该能力由Google DeepMind团队推出,核心产品经理Rohan Doshi表示,传统的AI模型在处理图片时,往往只是静态地看一眼。
如果图片里的细节太小,比如微处理芯片上的序列号或者远处模糊的路牌,模型往往只能靠「猜」。
而Agentic Vision引入了一个「思考-行动-观察」(Think-Act-Observe)的闭环:
模型不再是被动接收像素,而是会根据用户的需求,主动编写Python代码来操纵图像。
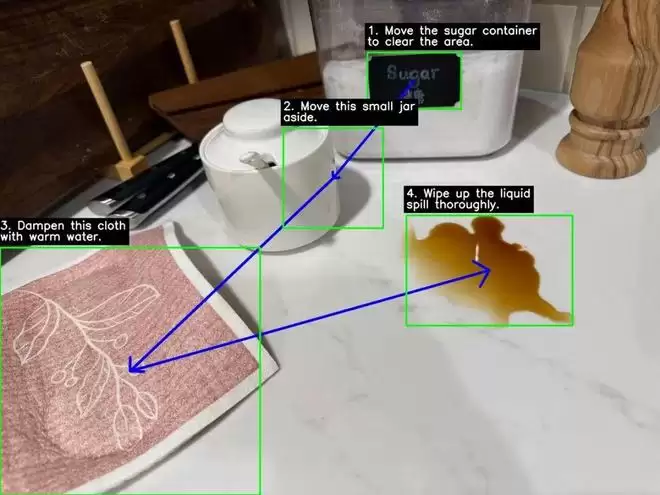
这一能力直接让Gemini 3 Flash在各类视觉基准测试中实现了5%到10%的性能跨越。
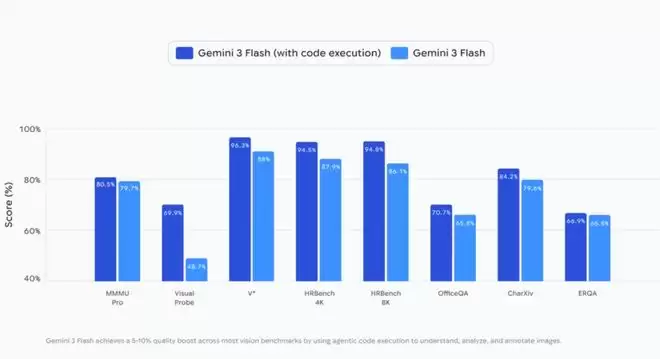
Agentic Vision:智能体视觉新前沿
DeepMind探索的方法概括起来就是:利用代码执行作为视觉推理的工具,将被动的视觉理解转化为主动的智能体过程。
什么意思呢?我们知道,目前的SOTA模型通常是一次性处理图像。
但Agentic Vision引入了一个循环:
1.思考(Think):模型分析用户查询和初始图像,制定多步计划。
2.行动(Act):模型生成并执行Python代码来主动操纵图像(如裁剪、旋转、标注)或分析图像(如运行计算、计数边界框等)。
3.观察(Observe):变换后的图像被追加到模型的上下文窗口中。这允许模型在生成最终响应之前,以更好的上下文检查新数据。
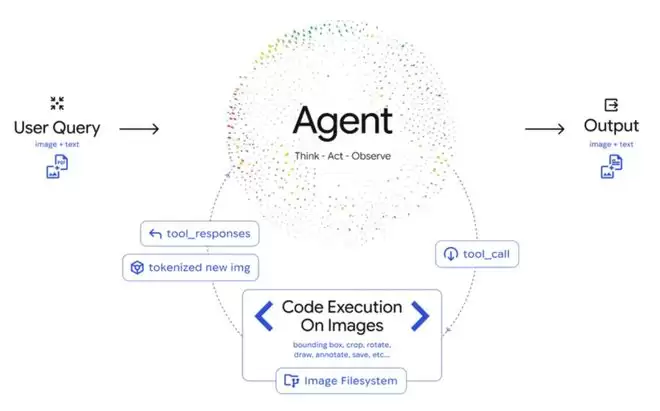
Agentic Vision实战
通过在API中启用代码执行,开发者可以解锁许多新行为。
Google AI Studio中的演示应用已经展示了这一点。
1. 缩放与检查(Zooming and inspecting)
Gemini 3 Flash被训练为在检测到细粒度细节时进行隐式缩放。
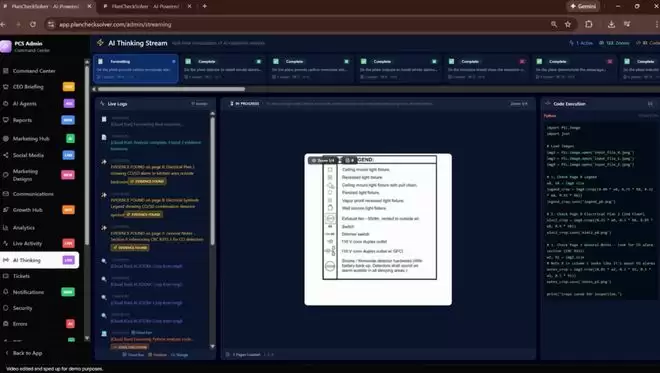
PlanCheckSolver.com是一个AI驱动的建筑计划验证平台,通过启用Gemini 3 Flash的代码执行功能来迭代检查高分辨率输入,将准确率提高了5%。
后台日志视频展示了这个智能体过程:Gemini 3 Flash生成Python代码来裁剪和分析特定的补丁(例如屋顶边缘或建筑部分)作为新图像。
通过将这些裁剪图追加回其上下文窗口,模型在视觉上确立其推理,以确认是否符合复杂的建筑规范。
2. 图像标注(Image annotation)
Agentic Vision允许模型通过标注图像与环境交互。
Gemini 3 Flash不仅仅是描述它看到的内容,还可以执行代码直接在画布上绘制以确立其推理。
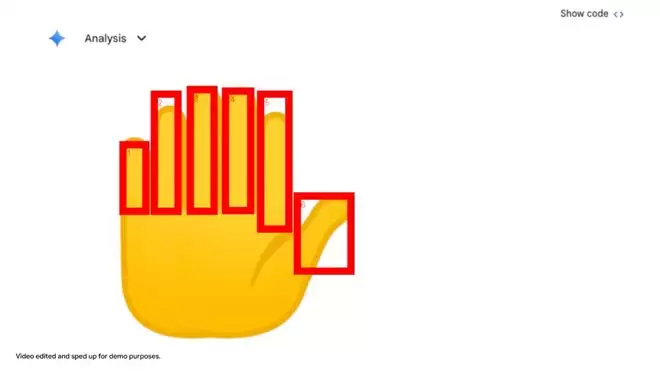
在下面的例子中,模型被要求数Gemini应用中一只手上的数字。
为了避免计数错误,它使用Python在它识别的每个手指上绘制边界框和数字标签。
这种「视觉草稿纸」确保其最终答案是基于像素级的完美理解。
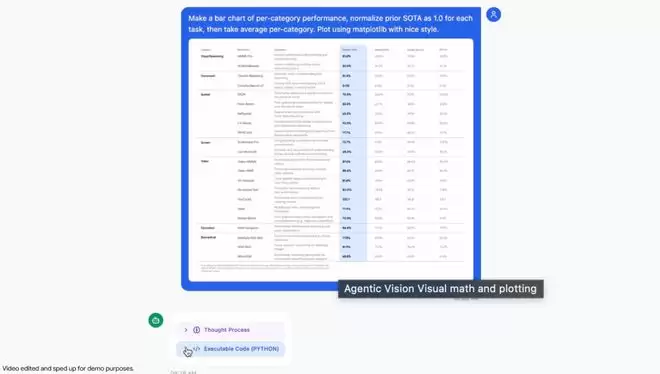
3. 视觉数学与绘图(Visual math and plotting)
Agentic Vision可以解析高密度表格并执行Python代码来可视化发现。
标准LLM在多步视觉算术中经常产生幻觉。
Gemini 3 Flash通过将计算放到到确定性的Python环境中来绕过这个问题。
在Google AI Studio的演示应用示例中,模型识别原始数据,编写代码将之前的SOTA归一化为1.0,并生成专业的Matplotlib条形图。这用可验证的执行取代了概率性猜测。
如何上手
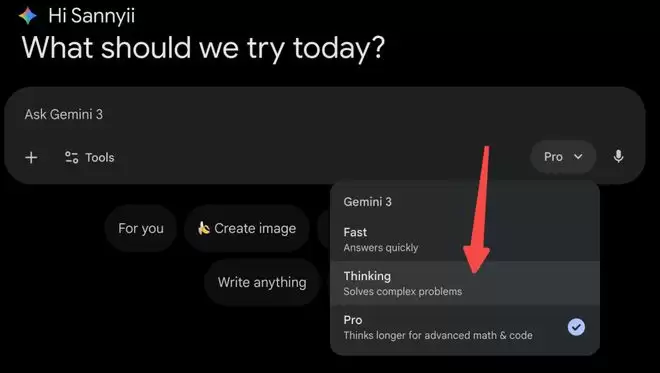
Agentic Vision今天已通过Google AI Studio和Vertex AI中的Gemini API提供。
它也开始在Gemini应用中推出(通过从模型下拉菜单中选择Thinking访问)。
以下是一个简单的Python代码示例,展示了如何调用这一能力:
print(response.text)
未来展望
Google表示,Agentic Vision才刚刚开始。
目前,Gemini 3 Flash擅长隐式决定何时放大微小细节。虽然其他功能(如旋转图像或执行视觉数学)目前需要显式的提示引导来触发,但Google正在努力在未来的更新中使这些行为完全隐式化。
此外,Google还在探索如何为Gemini模型通过更多工具(包括网络和反向图像搜索)来进一步确立其对世界的理解,并计划将此功能扩展到Flash以外的其他模型尺寸。
彩蛋:难道是因为DeepSeek?
这就很有意思了。
DeepSeek前脚刚开源了堪称「OCR 2.0」的DeepSeek-OCR,谷歌后脚就发布了Gemini 3的Agentic Vision。
这真的是巧合吗?
我们不妨大胆猜测,谷歌这次的「深夜炸场」,极有可能是被DeepSeek逼出来的。
理由有三:
1.时间点的惊人巧合
1月27日,DeepSeek刚刚发布了DeepSeek-OCR2,搭载核心黑科技DeepEncoder V2。它抛弃了传统的机械扫描,让AI学会了像人类一样「按逻辑顺序阅读」,仅用几百个Token就实现了对复杂排版和图表的完美理解。
谷歌同一天立马拿出Agentic Vision,仿佛在这场「视觉军备竞赛」中隔空喊话:「你们让AI看懂逻辑,我们直接让AI上手操作」。
2.技术路线的巅峰对决
DeepSeek-OCR2走的是「内功流」,通过DeepEncoder V2模拟人类的视觉注意力机制,动态重组图像信息,把「看」这个动作做到了极致的轻量化和逻辑化。
而谷歌的Agentic Vision走的是「外设流」,也就是「不光要看清,还要能动手」。DeepSeek在教AI怎么「用心看」,谷歌在教AI怎么「用手算」。
3.争夺视觉AI定义的终局
DeepSeek-OCR2证明了即便是3B的小模型,只要「视觉逻辑」对路,也能吊打大模型。谷歌则试图用「代码执行」来降维打击:你视觉再好也是「看」,我能写代码验证才是「真懂」。
这场仗,本质上是谁能重新定义「机器视觉」——是极致的感知,还是全能的交互?
不管是不是「应激反应」,这场神仙打架,最后爽的还是我们程序员。
参考资料:
https://blog.google/innovation-and-ai/technology/developers-tools/agentic-vision-gemini-3-flash/?linkId=43682412

相关攻略

2026年凯度BrandZ全球品牌价值百强榜发布,全球百强品牌总价值达13 1万亿美元,同比增长22%。谷歌品牌价值飙升57%,超越苹果重登榜首,微软、亚马逊紧随其后,首次出现四个品牌价值同时突破万亿美元。AI成为关键驱动力,ChatGPT品牌价值同比暴涨285%,成为增速最快品牌,Claude首次

近日,谷歌正式揭晓了2022年度博士奖学金(Google PhD Fellowship)的获奖名单。今年,众多华人学者再次表现亮眼,在获奖总人数中占比接近30%,展现出强大的科研实力。 仔细查阅获奖者的学术背景,可以发现多位学者在本科或硕士阶段均在中国顶尖高校打下坚实的学术基础。他们的母校包括清华大

谷歌同意支付1 35亿美元和解一桩集体诉讼。该诉讼指控安卓系统未经用户同意通过移动网络传输数据,甚至在设备闲置时仍持续收集。和解方案已获法院批准,符合条件的美国安卓用户可提交赔偿申请。赔偿总额在扣除相关费用后,将由最多约1亿名符合条件的用户分配。

谷歌健康应用将上线,整合并取代Fitbit。部分功能将移除或调整:睡眠档案、鼾声检测等将整合;有氧健身评分更名为VO2max,计算方式更新;每日目标改为个性化每周目标;勋章系统取消;社交功能简化,移除私信与群组,旧版社交将于2026年5月锁定。迁移后用户可管理好友并参与新排名。

谷歌推出全新笔记本电脑Googlebook,以Gemini为核心深度整合安卓与ChromeOS生态。产品与宏碁、华硕等五大厂商合作,配备标志性Glowbar发光条。其引入MagicPointer智能光标,能感知意图提升效率,并支持动态生成桌面小组件。设备可实现安卓应用在电脑端流式运行,并支持跨设备无缝访问手机文件。谷歌同时承诺现有Chromebook将继续获
热门专题







热门推荐

iCloud恢复卡在“估算剩余时间”时,可先尝试手动停止恢复进程并检查网络与账户状态,然后重新开始。若问题未解决,可使用专业第三方工具直接访问iCloud备份,在电脑上选择性预览和恢复所需文件,从而绕过设备端的恢复瓶颈,高效安全地取回数据。

WhatsApp备份可通过三种主要方式实现。应用内自动备份可设置频率,在后台定期保存数据。安卓用户可将数据备份至Google云端硬盘,支持自动或手动操作。如需精细筛选内容,可使用电脑端专业工具,选择性备份特定对话或附件,并导出为可读文件。三种方案分别满足便捷、集成与自主控制的不同需求。

iPad数据备份是数字生活的安全网,但原生备份机制不便直接查看和提取特定内容。专业恢复工具能直接读取iTunes或iCloud备份文件,支持选择性恢复多种数据类型,操作直观高效。用户可轻松预览备份内容,将所需文件单独还原到设备或电脑,从而实现对备份数据的灵活掌控。

忘记AppleID密码将影响iCloud、AppStore等服务使用。可通过专业工具在保留数据前提下移除ID,但需根据“查找我的iPhone”状态选择操作路径。或使用iTunes恢复出厂设置,此方法会清除所有数据。还可通过苹果官网重置密码,流程较复杂。若自助方法无效,可联系官方客服并提供购买凭证寻求协助。

iPadPro是苹果公司推出的专业平板电脑,现有11英寸和12 9英寸等型号。将旧iPhone或iPad的数据迁移到新iPadPro,主要有两种可靠方法。一是通过电脑使用iTunes备份恢复:连接旧设备后选择最近备份执行恢复,完成后数据即转移。二是利用iCloud无线传输:在新设备设置时选择从iCloud备份恢复,登录AppleID并选择对应备份即可。需注意