文生图参数量升至240亿,Playground v3发布:深度融合LLM,图形设计能力超越人类
过去一年多,文本到图像生成模型的技术路线发生了显著转变——从基于UNet的传统架构,逐步过渡到Transformer体系。近日,Playground Research发布了新一代模型Playground v3(简称PGv3),参数量直接拉到了240亿,在多个基准测试上都斩获了最先进的成绩,尤其是在图形设计方面的表现,甚至可以说超越了人类设计师。
PGv3的核心亮点,是完全摒弃了传统T5或CLIP文本编码器的做法,转而采用深度融合(Deep-Fusion)架构,直接把一个仅解码器的大型语言模型(Llama3-8B)嵌入到了整个生成流程中。这不仅让模型在文本提示遵循、复杂推理和文字渲染准确率上表现亮眼,还支持精确的RGB颜色控制以及多语言识别。

值得一提的是,研究团队还专门开发了一个内部描述生成器(in-house captioner),能够生成不同详细程度的图像描述,丰富文本结构的多样性。为了评估这一模块,团队又引入了全新的基准CapsBench。用户偏好研究数据显示,PGv3在常见的表情包、海报和Logo设计场景中,表现已经可以媲美甚至超越人类设计师。
01 PGv3模型架构
PGv3本质上是一个潜扩散模型(LDM),训练采用EDM公式。它与DALL·E 3、Imagen 2、Stable Diffusion 3一样,核心任务是文本到图像生成,但走得比它们更远——完全集成了Llama3-8B,强化了提示理解与遵循能力。
文本编码器
Transformer模型中,每一层捕捉到的信息都不相同,既有词级也有句级特征。传统做法通常是取T5或CLIP的最后一层输出,或者结合倒数第二层。但对于解码器风格的大型语言模型来说,究竟选用哪一层效果最好,其实相当棘手——模型内部表示相当复杂。
研究团队认为,LLM连续层之间的信息流才是生成能力的关键,而这些知识并非被某一层的输出所封装,而是横跨了所有层。基于这一判断,PGv3在设计时直接复制了LLM的所有Transformer块,从每一层对应块中提取隐藏嵌入输出。简单来说,就是让模型充分利用LLM完整的“思考链条”,从而实现更好的提示遵循能力与一致性。
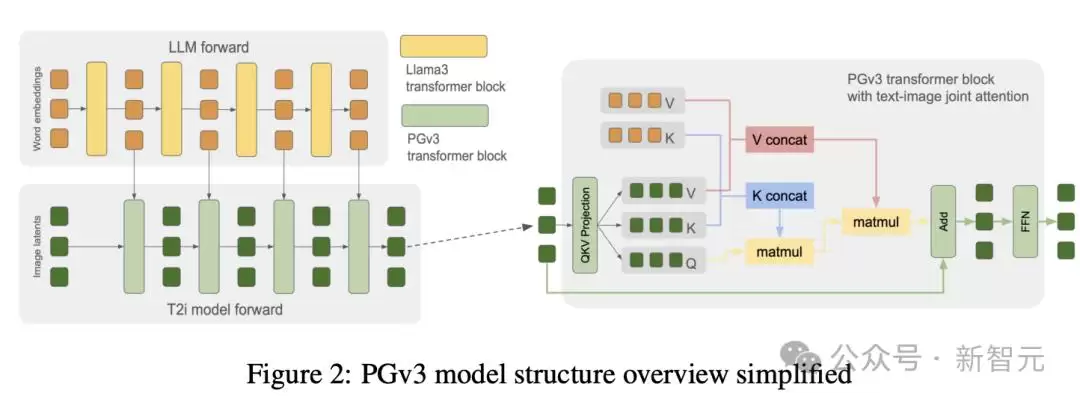
模型结构
PGv3采用DiT风格的结构。图像模型中的每个Transformer块和语言模型(Llama3-8B)中的对应块完全一致——只有一个注意力层和一个前馈层,参数也都相同(隐藏维度、注意力头数量和维度)。训练时只训练图像模型这部分。在扩散采样过程中,语言模型只需跑一次,就能生成所有中间隐藏嵌入。
相比传统基于CNN的扩散模型,这种结构将图像特征的自注意力与图文之间的交叉注意力分离开来,再做联合注意力操作。好处是可以从图像和文本值的组合池中提取特征,同时降低计算成本和推理时间。此外,还有几个对性能有帮助的小设计:
1. Transformer块之间增加了U-Net跳跃连接。
2. 中间层进行token下采样——在32层中,将中间几层的图像键和值的序列长度缩减至原来的四分之一。这使得整个网络变得更像一个只有一次下采样的传统卷积U-Net,训练和推理速度都有提升,而性能并未下降。
3. 位置嵌入沿用了Llama3的旋转位置嵌入(RoPE)。图像为二维特征,团队试验了2D版本的RoPE。其中,“插值-PE”方法(保持起始和结束位置ID固定、中间插值)在训练分辨率上过拟合严重,无法泛化到未见过的纵横比。反而是“扩展-PE”方法(按序列长度成比例增加位置ID,不使用任何技巧或归一化)表现更优,看不出分辨率过拟合的问题。
新的VAE
潜扩散模型中的变分自编码器(VAE),决定了细粒度图像质量的上限。团队将VAE的潜通道数从4增加到16,提升了合成细节能力——小的面部和文字都变得更加清晰。除了在256×256分辨率下训练,还扩展到了512×512分辨率,进一步改善了重建效果。
02 CapsBench描述基准
图像描述评估其实是一个相当棘手的问题。目前的评估指标主流分为两类:一类是基于参考的(如BLEU、CIDEr、METEOR、SPICE),但模型得分容易受到参考格式的限制;另一类是无参考指标(如CLIPScore、InfoMetIC、TIGEr),依赖参考图像的语义向量,对于密集图像和长描述来说,由于概念太多,语义向量代表性不足。
受DSG和DPG-bench启发,团队提出了一种反向评估方法——在17个图像类别中生成“是-否”问答对,覆盖通用、图像类型、文本、颜色、位置、关系、相对位置、实体、实体大小、实体形状、计数、情感、模糊、图像伪影、专有名词、调色板和色彩分级。评估时,语言模型仅基于候选描述回答问题,答案选项只有“是”“否”“不适用”。CapsBench包含200张图像和2471个问题,平均每张图像12个,覆盖了电影场景、卡通场景、电影海报、邀请函、广告、休闲摄影、街头摄影、风景摄影和室内摄影。
03 实验结果


研究人员对比了Ideogram-2(左上)、PGv3(右上)和Flux-pro(左下)。缩略图查看时,三个模型的图像差异不大。但放大检查细节和纹理时,区别就显现出来了:Flux-pro生成的皮肤纹理过于平滑,有点像3D渲染,不够真实;Ideogram-2纹理更真实,但提示词一长就容易丢失关键细节。相比之下,PGv3在提示遵循和真实感上均表现出色,并且明显具有更好的电影质感。
指令遵循

图中彩色文本部分代表模型未能捕捉到的细节。可以看到,PGv3始终能够把握住这些细节。当测试提示变长、包含更多详细信息时,PGv3的优势越发明显。这种提升主要归功于集成了LLM的模型结构,以及先进的视觉-语言模型图像描述系统。
文本渲染

模型能够生成海报、Logo、表情包、书籍封面和演示幻灯片等各类图像。PGv3还能复现带定制文本的表情包,凭借出色的文本渲染能力,创造出拥有无限角色和构图的新表情包。
RGB颜色控制

PGv3在颜色控制上达到了相当精细的程度,超越了标准调色板。用户可以使用精确的RGB值,精确控制图像中每个对象或区域的颜色。这对于需要精确颜色匹配的专业设计场景来说,非常实用。
多语言能力

得益于语言模型天然的多语言理解能力,PGv3能够自然地解释各种语言的提示。而且,仅需数万张多语言文本和图像对的数据集,就能实现这样的多语言能力,效率相当高。




