许多AI系统在设计之初运行良好,但在长期运行过程中,容易出现性能退化。常见的问题包括:请求入口缺乏统一治理、Agent功能被过度调用、会话状态管理混乱、推理层职责边界模糊,以及GPU资源利用率持续走低。
轻微情况下,系统响应延迟增加,用户体验明显下降;严重时,则会导致运营成本失控,甚至引发系统级崩溃。
设计这套架构基线,核心目标是在可控范围内,有效收敛系统复杂度,使整体架构能够实现真正的复用与规模化扩展。

AI系统架构中的常见陷阱
1. 请求入口缺乏统一管控
部分用户直接调用模型接口,部分自行集成工具,还有的团队另起一套独立的Agent流程。整个平台缺少统一的请求入口治理,导致限流、优先级调度和资源分配等机制形同虚设。同一批请求,有的通过平台路由,有的绕过平台直接访问GPU,使系统控制变得更加困难。
2. Agent功能的过度使用
很多任务仅需普通的直接推理即可高效完成。然而,为了追求技术展示效果,团队往往将复杂任务强行塞入Agent流程。结果造成推理延迟显著增加,运营成本直线上升,链路也变得冗长复杂。一个原本只需单次推理即可回答的问题,被拉拍成多步长流程,徒增不必要的环节。
3. 会话状态管理不当
如果将会话信息、中间计算结果和任务进度都存储在某一个服务实例的本地内存中,一旦服务重启或进行弹性扩容,原有的上下文就会全部丢失。例如,用户任务执行到一半,实例意外宕机,后续只能从头开始,这种体验极易造成用户流失。
4. 推理层职责边界模糊
将业务逻辑判断、外部工具调用和状态管理等功能一股脑地集成到模型推理服务中。短期内看似便捷,但长期来看,这会形成一个难以维护的“黑盒”。当需要更换推理引擎时,由于其中耦合了大量业务逻辑,迁移工作异常困难。进行性能优化或问题排查时,也需要付出巨大的精力。
5. GPU算力资源利用不均衡
请求未经过统一的调度层,难以实现有效的排队、批处理与负载均衡。最终的结果是:部分GPU卡负载过高,计算繁忙;而另一些则处于空闲状态,整体吞吐性能难以提升。当GPU利用率低至一定水平时,向公司申请采购新卡的理由也会变得不充分。
为应对上述挑战,我们设计了一套面向AI系统的基础架构基线方案。这是一套对GPU友好的分层架构,将调度、执行与推理三层职责清晰分离,同时将Agent、状态管理和工具调用等能力置于可控位置。这种设计既支持持续迭代,又能防止系统失控。
整个系统划分为三个核心层级:
第一层、Scheduling Layer(调度层)
该层负责所有请求的统一接收与分发治理。核心职责包括:请求的批处理(Batch)、排队(Queue)与GPU分配(GPU分配)。同时,它还管理限流、熔断和优先级控制,并决定是否将请求路由至Agent执行路径。
第二层、Execution Layer(执行层)
该层决定请求具体采用哪种执行路径。系统提供两条执行通道:
Direct Inference Path:针对普通请求,采用无状态、低延迟的直接推理路径,作为默认执行方式。
Agent Execution Path:处理需要多步执行、会话状态管理及外部工具调用的复杂任务。
第三层、Model Inference(推理层)
该层核心关注模型的实际运行。它部署了vLLM等推理引擎,负责GPU执行、KV Cache管理等纯推理能力。推理层只执行任务,不包含任何业务逻辑。
系统侧边包含两类外部依赖组件:
- State Layer:管理会话状态、中间计算结果、RAG知识库及KV库。
- Tools:提供外部API、数据库及其他服务接口。
系统底层遵循三条核心约束:
- 所有请求必须经过调度层。
- Agent默认状态下不启用。
- 所有状态必须外置存储。

为什么所有请求必须经过调度层?
与传统互联网系统相比,AI系统的单次请求成本更高,且请求的差异性也更大。请求长短不一,到达时间具有随机性——既有简单的问答类请求,也有需要复杂推理的任务。GPU天生不擅长处理大量零散的小任务,它更适应稳定连续的任务流、尽可能少的上下文切换与抖动、大规模并行处理以及可预测的显存占用。
缺少调度层,各种类型的请求会直接冲击GPU,导致其性能被严重碎片化。调度层的本质作用,就是将随机、零散、差异巨大的请求,重新整理成GPU更擅长的稳定并行任务流。从而提升资源利用率、减少浪费,并保护关键业务的稳定运行。

为什么Agent默认不启用?
基于Transformer的大语言模型本质上是概率模型,存在固有的幻觉和输出不稳定性。Agent的步骤越多,随着链路变长,出错概率也会被放大。此外,多次调用的代价更高——系统响应更慢,成本更贵。大量简单请求,通过直接推理就能高效完成,无需引入Agent。因此,默认不启用Agent,是为了精准控制复杂能力的应用范围,仅在确实需要多步执行时再启用。这种做法使系统更稳健,也更容易控制运营成本。
为什么状态必须外置存储?
系统每执行一步,都依赖当前状态与新的输入,并产出新的状态与输出结果。将状态外置,意味着把当前状态从进程内部抽离出来,转化为一个可存储、可读取、可恢复的显式变量。如果状态存储在服务自身的进程内存中,一旦服务重启、扩容或切换机器,状态就可能丢失,导致流程中断。将状态外置后,会话信息、中间计算结果和任务进度都能被可靠保存。系统因此更易于恢复、横向扩展和问题排查,多步任务也能在中断后继续执行。
为什么将系统治理能力部署在入口?
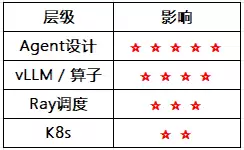
对于软硬一体化的AI系统而言,Agent设计是提升整体性能和GPU利用率最有效的环节之一。而在系统入口对所有请求进行统一调度,是Agent设计中效率最高的做法。限流、熔断、优先级、排队和资源分配等能力,本质上都属于平台级的治理能力。如果请求绕过了调度层,资源争抢、延迟抖动、线上不稳定以及问题难以定位等问题就会随之而来。

Batch / Queue / GPU 分配为何放在调度层?
Batch(批处理)是将多个请求打包在一起处理,目的是提升系统吞吐量。GPU更擅长一次性处理一批任务,将多个小请求合并处理通常比单独运行更节省算力。Queue(排队)是让请求先进入队列,按顺序或优先级等待执行,目的是稳定系统。当请求量激增时,通过排队可以避免系统过载,也便于控制优先级、限流和执行顺序。GPU分配是决定请求该交给哪张GPU卡或哪个推理实例去执行,从而避免某些卡繁忙、某些卡空闲,提升整体资源利用率。
这三项操作本质上都属于统一分配与统一治理范畴。将其放置在调度层,系统才能从全局视角有效协调请求与资源。

为什么限流、熔断与优先级控制要放在调度层?
限流是控制请求进入的速度或数量,防止系统因过载而崩溃,核心作用是保护系统稳定性。熔断是在下游服务响应缓慢、错误率高或濒临过载时,暂时拒绝或跳过这部分请求,防止问题蔓延。优先级控制则是确保关键业务请求优先被处理,普通请求后置,以保证核心业务能及时获取资源。
这三项操作本质上都是入口级别的治理措施。一旦请求进入推理服务内部再执行这些操作,就已经为时已晚。

为什么推理层设计为纯执行层?
推理层的职责是让模型高效运行——完成GPU计算,将输入转化为输出。它是一个纯粹的映射函数。这种设计优势明显:职责清晰,边界明确;更容易围绕GPU和推理引擎进行深度性能优化;更容易替换模型或推理框架;出问题时也更容易定位是哪一层出现了故障。
如果将业务判断、流程控制、状态管理、工具调用等功能也塞入推理层,这一层会变得越来越复杂,后续的优化、排障和替换工作将变得异常困难。

算力资源有限,因此调度优先;成本控制敏感,因此执行路径分流;系统稳定优先,因此状态管理采用显式外置。




