本体论驱动的人工智能数据底座实践解析
时间:2026-07-03 16:08
先分享一个核心观点:模型能力的天花板,往往由数据的质量与结构决定,而非模型本身的参数规模。在大模型的实际落地过程中,这一规律愈发明显——尤其在工业领域,大量数据以非结构化形式存在,例如各类PDF、操作手册、技术规范等,语义复杂、专业术语密集、上下文依赖性强,且同一概念常有多种不同表述。如果直接将这些
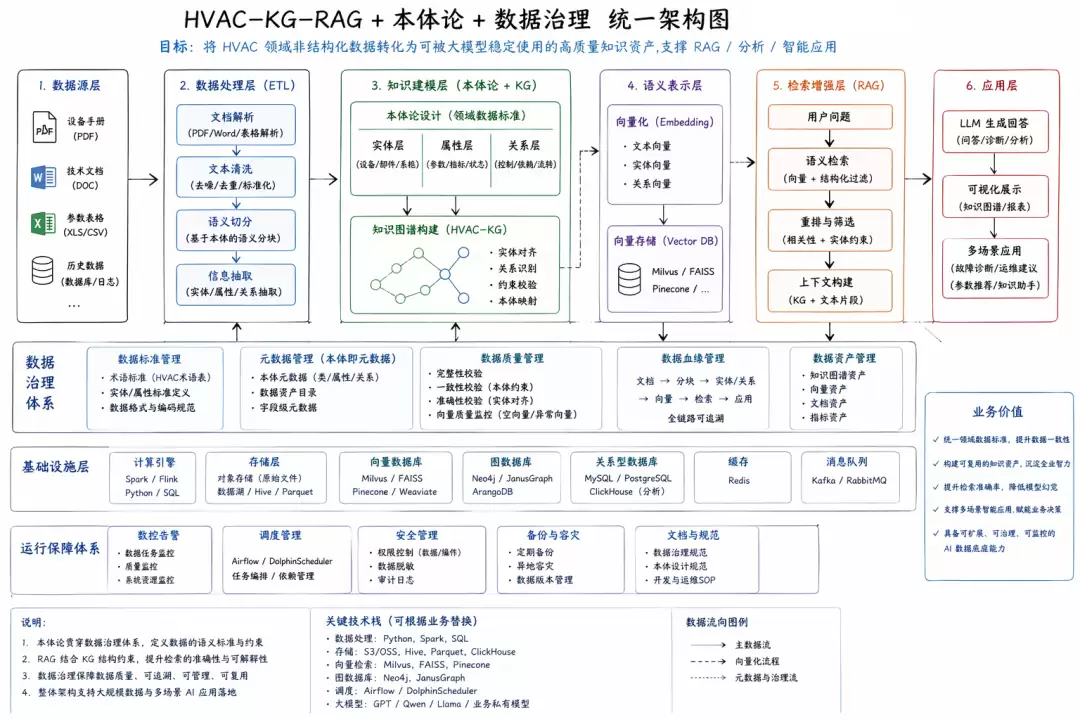
先分享一个核心观点:模型能力的天花板,往往由数据的质量与结构决定,而非模型本身的参数规模。在大模型的实际落地过程中,这一规律愈发明显——尤其在工业领域,大量数据以非结构化形式存在,例如各类PDF、操作手册、技术规范等,语义复杂、专业术语密集、上下文依赖性强,且同一概念常有多种不同表述。如果直接将这些数据送入大模型,RAG召回不稳定、上下文噪声高、幻觉频发几乎是必然的结果。
项目背景
因此,本项目的核心目标不仅是构建一个问答系统,更是要建立一套面向大模型的数据治理与数据供给体系。换言之,必须先把数据“伺候”到位,模型才能真正发挥其潜力。
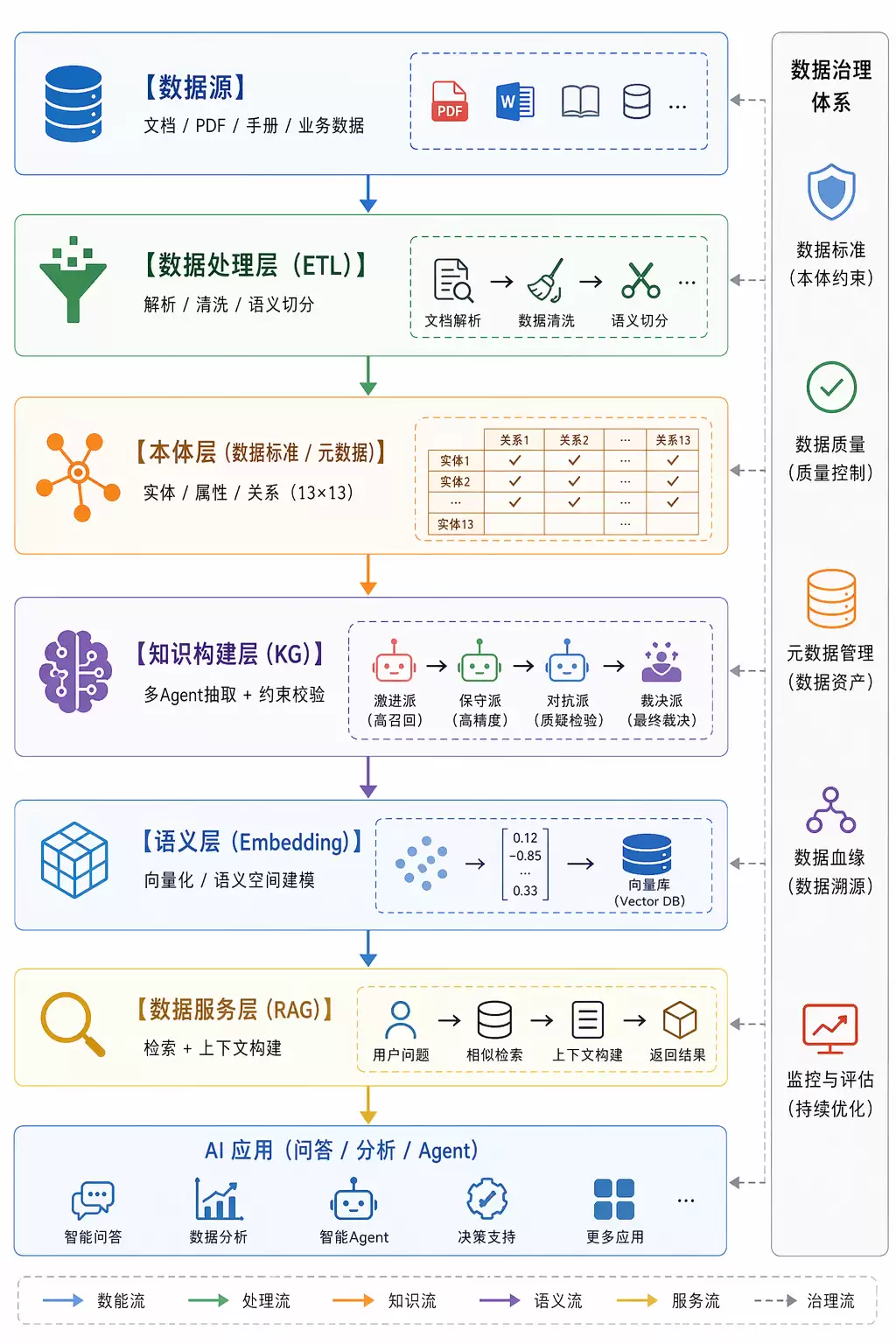
整体系统架构
整个系统可以抽象为一条完整链路:数据 → 知识 → 语义 → 应用。虽然听起来宏观,但每个环节都有具体而扎实的设计支撑。
核心设计一:本体论 = 数据标准体系
**1. 本体的本质**
在本项目中,本体论扮演的是领域数据标准与元数据模型的角色。它定义了一套HVAC领域的统一语义结构:13类实体(设备、参数、工艺、故障等),13类关系(包含、依赖、影响、控制等),共同构成一个13×13的语义约束体系。
**2. 本体解决的问题**
(1)术语统一。例如“空调机组/空调设备/空调系统”统一为标准实体,“制冷量/冷量/制冷能力”合并为统一表达。本质上实现了数据标准化。
(2)关系约束。如“空调机组 `contains` 压缩机”“温度 `affects` 制冷效果”——统一关系类型与方向,避免语义歧义。
(3)减少幻觉。通过规则限制仅允许13种关系,禁止过度推理,强制保持语义一致性。这本质上是数据质量控制的关键手段。

核心设计二:软本体驱动的AI数据治理
**1. 为什么选择软本体**
本项目采用Soft Ontology(基于LLM的本体),而非OWL/RDF的形式本体。原因很现实:软本体构建成本低、迭代速度快、对噪声容忍度高,尤其适合工业领域杂乱的非结构化数据场景。
**2. 本体注入机制(关键)**
本体以“宪法”的形式存在,通过Prompt注入到所有Agent中。概括来说:用本体作为数据治理的规则引擎。全局本体约束`{global_policy}`贯穿整个流程。
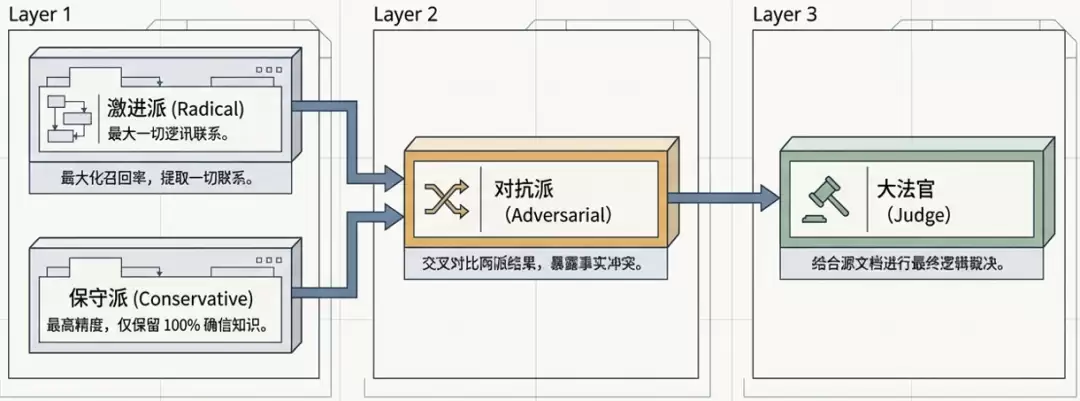
核心设计三:多Agent协同的数据质量控制
为提升数据质量,我们设计了一个四阶段协同机制。这本质上是在构建一套面向AI的数据质量治理机制——让数据从源头到产出始终处于可控状态。
核心设计四:知识图谱 = 数据资产沉淀
最终输出成果:节点478个、关系417条。这意味着原始文档已转化为结构化的知识资产。这一步的价值在于:数据可复用、可查询(通过Cypher)、可扩展、可跨场景使用。本质上是实现数据资产化。
核心设计五:RAG = 数据供给接口
许多人把RAG当作问答技术,但在本系统中,RAG扮演的是数据供给层——从知识资产中检索上下文、构建模型输入、提供稳定的语义支撑。RAG效果的问题,归根结底是数据问题。

升级路径
从软本体到企业级数据治理,当前方案属于“软本体 + AI驱动的数据治理”。未来可以逐步演进:
阶段1:增强型软本体
增加质量检测机制,引入置信度评分。
阶段2:混合本体
核心概念采用OWL化,引入推理引擎。
阶段3:形式本体
标准化建模(OWL/RDF),构建企业级知识体系。

总结与启示
本项目最大的收获并非技术本身,而是对AI、对数据认知的转变。起初以为只是做一个普通的RAG系统,最终却构建了一套面向大模型的数据治理与数据供给体系。目标是让数据可理解、可复用、可被AI稳定使用。在AI时代,数据不再只是被存储和分析,而是要成为模型消费的“燃料”;数据治理也从服务给人类看的BI,转向服务大模型与智能系统。这或许才是整个项目最核心的启示。




