先说几点判断。
端到端自动驾驶模型正面临一个关键挑战:“隐形的天花板”。模型参数不断膨胀,数据规模持续扩大,但在复杂场景下,规划轨迹仍会出现异常漂移。问题根源不在于规划头,而在于视觉信息传递的“咽喉要道”——场景 token 瓶颈。
今天解析的这项研究,通过一个巧妙的训练信号,迫使紧凑的场景 token 记住更多关键信息,直接在 Waymo 和 Na vSim 榜单上取得了突破性进展,并将该技术成功部署到了实车之上。
核心痛点:场景 Token 的无效编码问题
在感知无关的端到端自动驾驶方案中,主流做法是利用 ViT 将多视角图像处理为密集的 patch token,再压缩成少量“场景 token”供规划器使用。这是一个典型的“多对一”极限压缩过程:数百甚至上千个 patch token 被压缩进 16 个场景 token 中,最后规划器仅凭这些有限信息输出未来轨迹。
关键问题在于:谁来有效监督这个压缩过程?
现有方法仅依赖轨迹回归损失和候选评分损失进行间接约束。这就好比只告诉快递分拣员“最终包裹要按时送达”,却不告知哪些包裹内是易碎品、哪些需要冷链运输。分拣员自然会选择“偷懒”——将所有包裹混放,只要最终能送达即可。
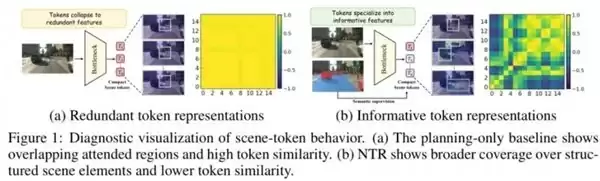
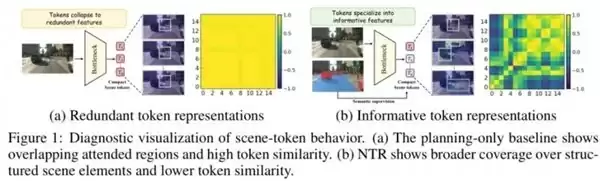
这是该项工作最精彩的开场展示。左侧是 baseline,多个场景 token 的注意力分布高度重叠,相似度矩阵呈现大片“全黄”区域。换言之,16 个 token 中可能仅有 2-3 个真正发挥作用,其余都在输出冗余信息。右侧是 NTR 方法,每个 token 开始“术业有专攻”:有的聚焦车道线,有的关注前车,有的识别交通标志。相似度矩阵从“黄色暧昧”转变为“蓝绿黄交织的清晰距离感”——表征的多样性显著提升。
这并非架构本身的问题,而是训练信号的不足。由于缺少对压缩过程的直接约束,token 自然趋向于坍缩为最简单的冗余编码形式。
原理拆解:NTR 如何打破 Token 冗余?
NTR 的核心思路其实很直接:既然规划损失过于稀疏,就为场景 token 增加一个密集的重建监督任务。注意,它并非重建原始图像,而是重建被 mask 掉的教师模型特征——这是一种在潜在空间进行的自蒸馏。而且,整个重建分支仅在训练阶段生效,推理时完全移除,不带来任何额外开销。
看看架构图就一目了然了。
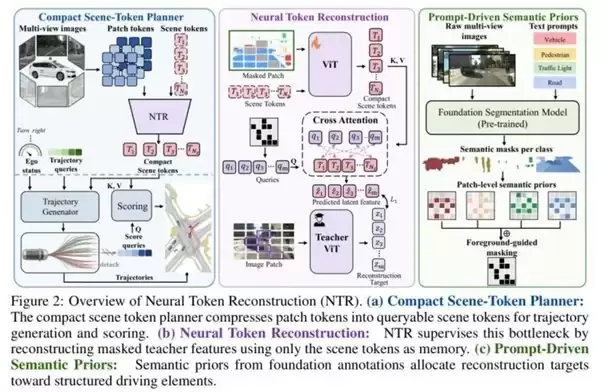
整个框架分为三个模块:
(a) 标准规划器基底: 多视图 → patch token → 场景 token → 轨迹生成 + 评分。这就是不变的基准线。
(b) NTR 核心插入: 一个仅在训练时激活的重建解码器。它的输入仅限于场景 token 和 mask 位置的位置编码,必须仅凭这些信息重建对应位置的教师模型特征。
(c) 语义先验模块: 利用预训练的 SAM3 处理图像,获取车辆、行人、车道、交通灯等驾驶关键区域的 mask,用以指导重建位置的选择。
这里有一个精妙的设计:重建解码器只能通过交叉注意力机制访问场景 token,无法直接查看在线编码器的密集 patch 输出。这意味着,重建损失的回传梯度必须经过场景 token 这个瓶颈,相当于给瓶颈安装了一个“信息审计系统”:如果 token 没有保留足够的细节信息,就无法完成重建。
潜变量重建:为何不选择原始像素?
这是一个经过深思熟虑的设计选择。NTR 不重建 RGB 像素,而是重建教师 ViT 输出的潜变量特征。
教师模型是在线编码器的 EMA(指数移动平均)副本,其参数缓慢跟随在线模型,能够提供稳定、高质量的“参考答案”。
为什么选择潜变量而非像素?主要有两个原因:
- 像素重建属于低级视觉任务,大量监督信号会浪费在背景纹理、天空渐变等细节上。而潜变量特征已经过 ViT 编码,更侧重于语义和结构信息。
- EMA 教师提供的是自适应的学习目标。冻结的教师模型可能会被在线模型快速超越,而 EMA 教师始终保持在“略微领先”的状态,如同一位不断进步的教练。
重建损失采用 L1 范数,具体公式如下。
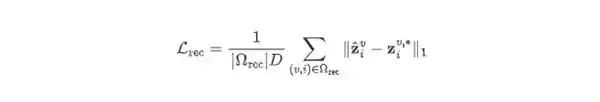

语义先验:将有限资源用于关键信息
均匀 mask 重建存在一个问题:自动驾驶图像中,大面积的天空、远处模糊的背景占据了许多 patch。重建这些区域既浪费计算资源,也可能引入不必要的噪声。
NTR 的解决方案非常聪明:利用预训练的 SAM3 对图像进行弱语义标注,生成前景 mask,优先选择包含车辆、行人、可行驶区域、交通灯等元素的 patch 作为重建目标。这并非引入显式的感知头——SAM3 是冻结的,仅在预处理阶段运行一次的基础模型,既不参与端到端训练,也不部署到实车上。
具体操作步骤如下:
- 使用文本 prompt 集(如“vehicle”、“pedestrian”、“traffic light”、“road”等)驱动 SAM3 生成逐类别的 mask
- 将 mask 池化到规划器的 patch 网格上
- 按类别权重进行加权,并加入少量高斯噪声(τ=0.4)以增加探索性
- 按重建比例 ρ_rec=0.3,选择得分最高的 Top-m 位置作为重建目标
这种“聚焦前景”的策略,本质上是利用弱语义信号来引导信息保留的优先级。直接告知模型“人和车最为关键”,效率会高出许多。
实验验证:数据揭示真实效果
SOTA 对比:三项基准全面领先
首先关注 Waymo 端到端驾驶排行榜——这是不容忽视的测试基准。
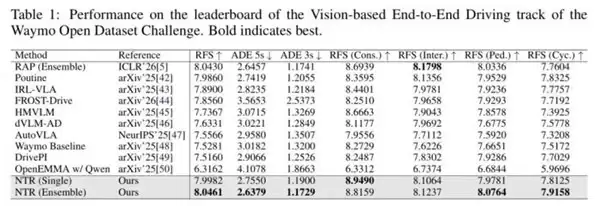
NTR 不仅在 RFS(人类评分反馈,越高越好)指标上取得了最优表现,在 ADE(平均位移误差,越低越好)指标上也有同步提升。单模型 7.998 分相比之前的方法,差距清晰可见。这意味着改进不仅体现在“人类感觉更好”,更在于轨迹精度的实质性提升。
再看看 Na vSim V1 的 na vtest 测试集表现。
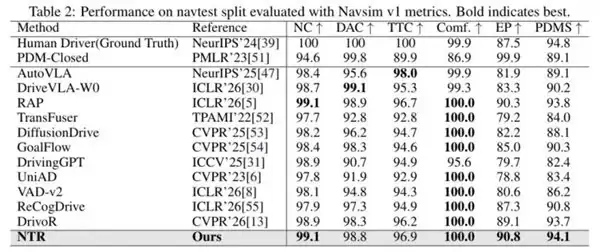
PDMS、EP 等是基于驾驶规则的闭环指标,更像“考官打分”。NTR 在这些指标上的一致性领先,说明它学到的并非特定场景的取巧策略,而是更泛化的驾驶能力。
以及在 Na vSim V2 扩展指标下的表现。
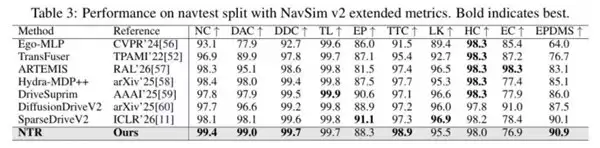
三张表格的结果互不矛盾,趋势高度一致:NTR 带来的提升具有系统性,而非某个指标上的偶然波动。
定性分析:极端场景下的真实表现
数值好看,实际路况中是否能有效应对?来看两个极具挑战性的场景。

上图展示的是白天施工区,左前方有锥桶和施工车辆。Baseline 的轨迹偏于保守,向右侧漂移;而 NTR 的轨迹更贴近真值,绕行意图更为清晰。下图则是夜晚雨天场景,视线不佳、路面反光——这是感知极易失效的环境。Baseline 的轨迹明显偏左,几乎要压到对向车道线;而 NTR 则稳定地保持在车道中央。
这些图表明:NTR 学到的不仅仅是“看得更清楚”,更是“记住更有价值的信息”。施工区的锥桶、雨夜的车道线,这些结构化元素正是语义先验所强调的重建目标。
消融实验:逐一验证各组件贡献
技术文章不进行组件拆解就会缺乏说服力。NTR 进行了精细的消融实验。

- 仅增加随机 mask 潜变量重建:RFS 从 7.652 提升至 7.754。仅凭密度更高的监督信号,就已经产生效果。
- 替换为 EMA 教师:RFS 继续提升至 7.817。自适应更新的教师比冻结版本更有效。
- 加入语义先验引导选择:EMA+语义先验的组合达到 7.974,ADE@5s 降至 2.146。信息选择的位置确实至关重要。
- 完整 NTR:所有组件协同作用,改进幅度约 0.32 个 RFS,误差降低约 16%。
消融表的结果清晰明了,没有“鸡肋组件”——每增加一项都有正向贡献,其中语义先验在 EMA 教师支持下的边际收益最大。
Token 诊断:用数据证明 Token 不再“冗余”
这是整篇论文中最精彩的实验设计之一。如何量化 token 的“活跃程度”?论文使用了两个指标:相似度(越低越好)和有效秩(越高越好)。
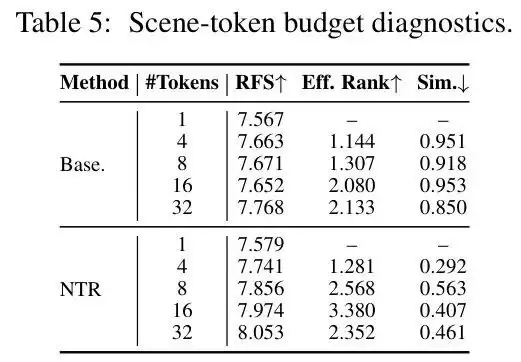
在 token 数量从 1 到 32 的变化过程中,NTR 的相似度始终显著低于 Baseline,意味着 token 之间的信息重叠更少。有效秩方面,NTR 则全面领先,尤其在 16 个 token 时接近饱和——再增加 token 收益递减,说明 16 是一个良好的预算平衡点。而 Baseline 方法增加 token 反而可能出现性能波动,说明冗余的 token 有时会引入混乱。
这套诊断方法直接将“token 冗余”从感觉转化为可测量的数据。相似度下降加上有效秩上升,意味着 token 开始各自承担不同的信息角色,这正是 NTR 设计目标的直接验证。
局限性:坦诚比完美更重要
作者诚实地指出了 NTR 方法的边界:
- 作用于瓶颈而非 Backbone。 NTR 优化的是“压缩 → 规划”阶段的信息传递效率,并不改变 ViT 本身的特征提取质量。它与 MAE、iBOT 这类 Backbone 预训练方法属于互补关系。
- 依赖基础模型生成语义先验。 SAM3 虽然强大,但在域外场景(如极端天气、罕见的国家街道)中可能产生不准确的 mask。不过,它仅在训练时使用,不部署到实车上,影响可控。
- 训练开销有所增加。 额外的教师模型前向传播、重建解码器、语义先验预处理都会增加训练成本。在公开基准上,这是可接受的代价,但大规模量产场景可能需要优化管线。
价值升华
这项工作解决了一个被多数人忽略但极其关键的问题:信息压缩的质量,决定了自动驾驶规划能力的上限。过去,业界热衷于增加 token 数量、更换更大的 backbone、设计更复杂的规划头,却很少有人直接追问——压缩过程中究竟丢失了什么信息?
NTR 的价值不仅在于一个 SOTA 分数,更在于提供了一种可插拔、零推理开销、具有理论直觉的瓶颈监督范式。
如果你正在研究端到端自动驾驶:这个框架可以应用于大多数 token 压缩规划器,训练时额外运行一个重建分支,推理时则完全不干扰部署流程。
如果你关注表征学习:它展示了一种“利用重建梯度约束信息瓶颈”的通用思路,其应用范围不限于自动驾驶。
如果你追求落地部署:NTR 已经在真实车辆规划栈中集成并得到验证,论文附录中提供了实车部署视频和私有大规模数据集实验——这比单纯的刷分多了一层说服力。
下一次设计信息压缩模块时,别忘了问自己一句:压缩过程是否得到了有效监督?




