图解强化学习:手算MADDPG算法原理与步骤
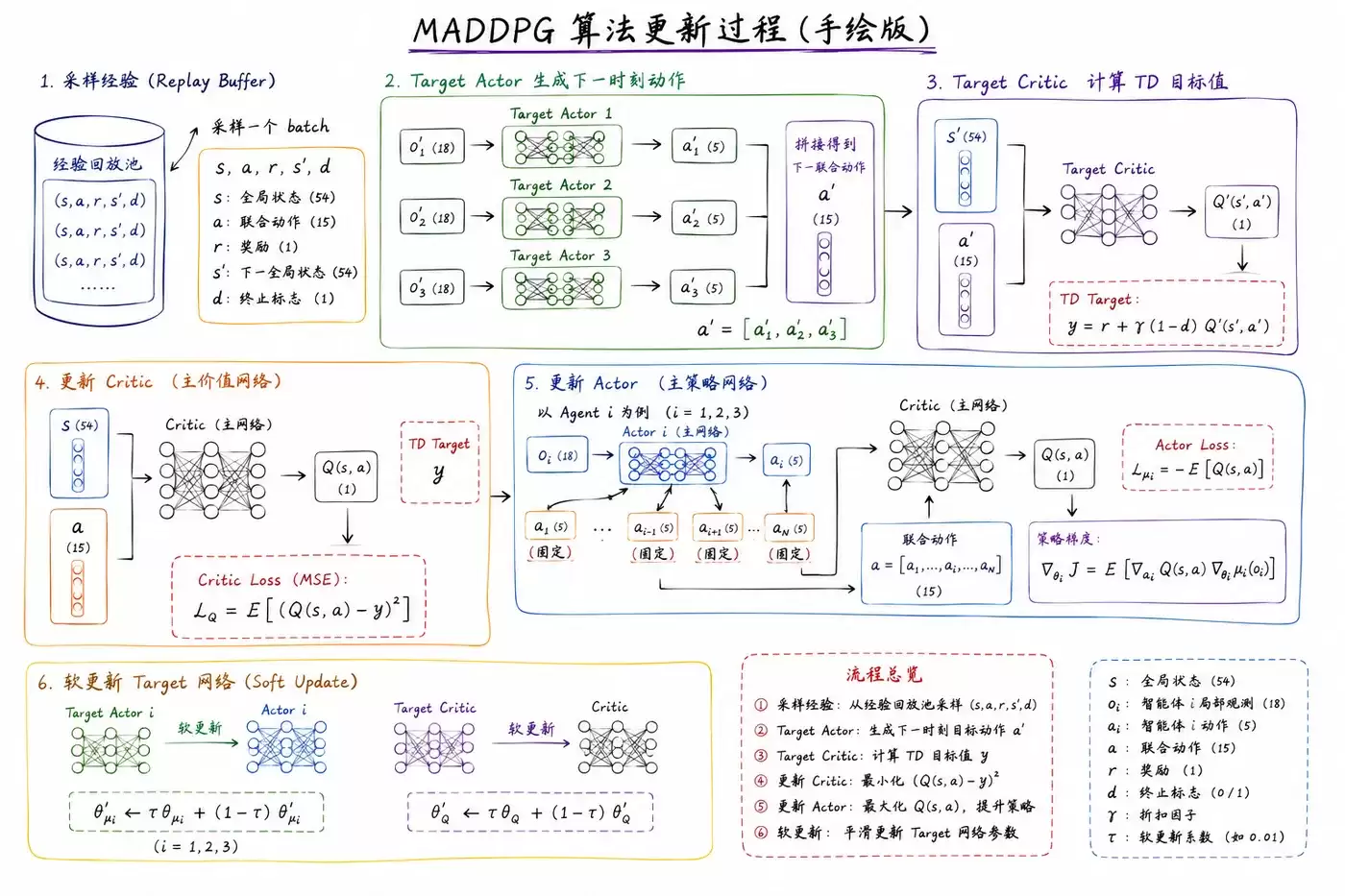
在多智能体强化学习(MARL)领域,MADDPG算法是一个里程碑式的经典框架。它核心解决了多智能体环境中的“非平稳性”挑战——即当所有智能体同时学习时,每个智能体所面对的环境都在因其他智能体的策略变化而持续变动,这使得传统的单智能体强化学习方法难以稳定收敛。MADDPG提出的“集中式训练,分布式执行”范式,为这一难题提供了优雅的解决方案。
该框架的核心思想在于:在训练阶段,每个智能体拥有自己独立的策略网络(Actor),用于生成动作;但同时,所有智能体共享一个具备全局视野的中央价值网络(Critic)。这个Critic在训练时可以访问所有智能体的状态和动作信息,从而能做出更精准的全局价值评估。而在实际部署和执行阶段,每个智能体仅依据自身的局部观测独立决策,实现了高效的分布式运行。该方法继承了深度确定性策略梯度(DDPG)的确定性策略输出和双网络软更新机制,确保了训练过程的稳定性与可靠性。

MADDPG算法网络结构详解
要深入掌握MADDPG,必须透彻理解其四大核心网络组件。它们分工明确,协同工作,构成了算法的坚实基础。
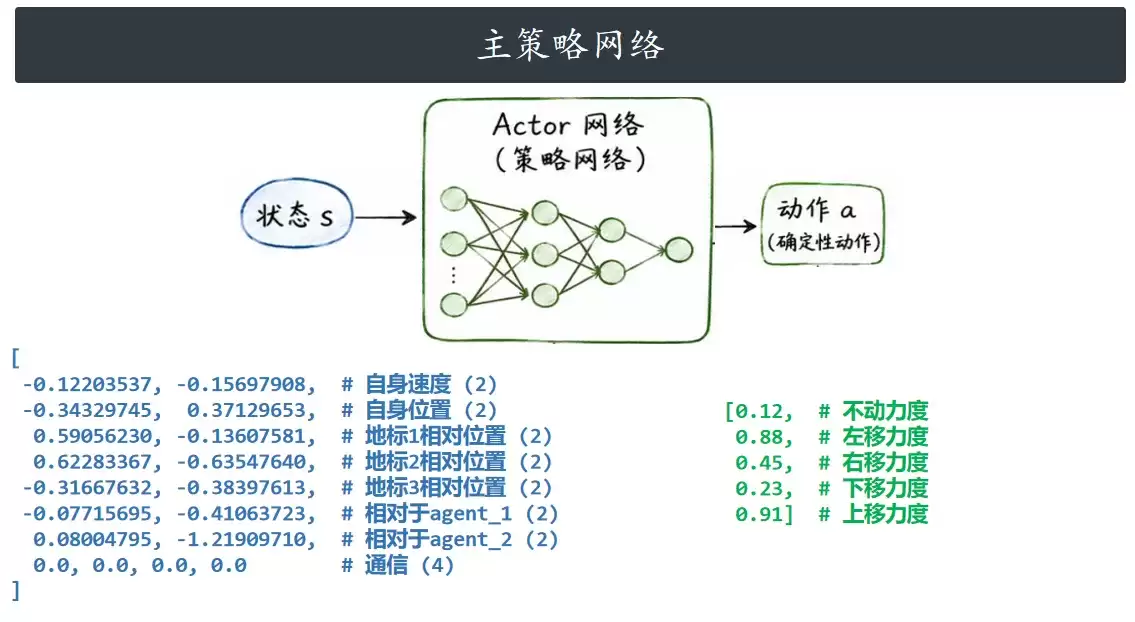
策略网络:Actor(主策略网络)
这是每个智能体独立决策的“大脑”。在我们的示例场景中,设有三个智能体(Agent0, Agent1, Agent2),因此对应三个参数独立的Actor网络。
每个Actor都是一个采用确定性策略的全连接神经网络。这意味着它不输出动作的概率分布,而是直接输出一个确定的连续动作向量。其输入维度为18,对应单个智能体的局部观测空间,通常包括自身速度、位置、相对于环境地标及其他智能体的方位信息,以及可能的通信向量。输出维度为5,对应五个基本动作(例如:无动作、向左、向右、向下、向上)的连续控制量,数值范围通常约束在[0,1]区间。
其工作流程主要分为两个阶段:
- 环境交互阶段:接收自身的18维观测向量,直接输出5维动作。为了促进探索,在训练阶段会在输出的动作上叠加一个高斯噪声,随后将结果截断到合法的动作值域内。
- 网络参数更新阶段:在训练时,会将全局的54维状态向量进行拆分,提取出属于每个智能体的那部分18维观测,分别送入其对应的Actor网络,生成新的动作,这些动作随后用于计算Actor的损失函数。
最关键的设计在于,Actor在执行(部署)时仅依赖于自身的局部观测,无需感知全局信息,这从根本上保证了算法能够实现真正的分布式执行。
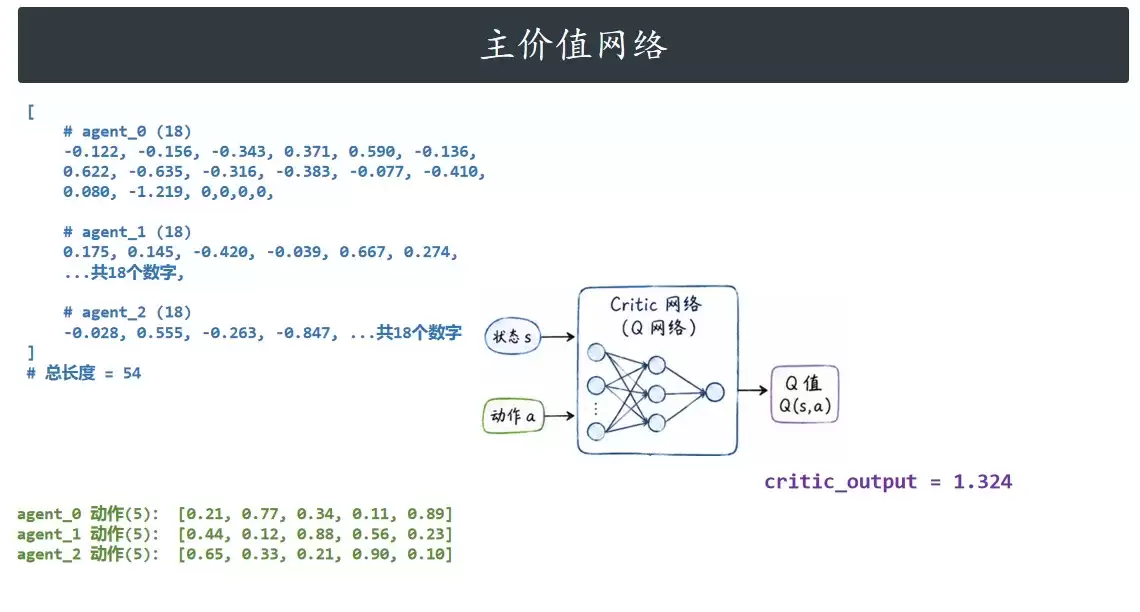
价值网络:Critic(主价值网络)
如果说Actor是独立的“执行者”,那么Critic就是统揽全局的“评估者”或“教练”。整个系统共享一个Critic网络。
它的输入信息是全局性的:
- 全局联合状态(54维):由三个智能体的18维观测直接拼接而成,囊括了所有智能体的位置、速度、相对关系等完整环境信息。
- 全局联合动作(15维):由三个智能体的5维动作直接拼接而成。
其输出是一个标量Q值。这个数值评估了“在当前全局状态下,所有智能体执行当前这组联合动作”所能获得的长期期望累积回报。Q值越高,表明当前的整体行为策略越优。
Critic是整个MADDPG训练过程的枢纽与桥梁。它主要承担两项核心任务:一是通过计算自身损失来更准确地预测状态-动作对的真实价值;二是利用其预测的Q值作为指导信号,反向传播至各个Actor网络,引导它们朝着最大化全局回报的方向优化策略。正是凭借其全局视角,Critic能够理解智能体之间复杂的协作或竞争关系,从而有效克服了多智能体环境的非平稳性问题。
目标策略网络与目标价值网络
目标网络(Target Actor 和 Target Critic)是主网络的“延迟副本”,它们的存在是为了提升深度强化学习训练的稳定性。其网络结构与对应的主网络完全相同,但不参与即时的梯度更新。
- 目标策略网络(Target Actor):共3个,与3个主Actor一一对应。它们仅在训练阶段使用,负责根据下一时刻的状态生成“目标动作”。
- 目标价值网络(Target Critic):共1个,与主Critic配对。它专门用于计算时序差分(TD)目标中的未来价值估计部分。
目标网络的参数通过“软更新”机制,缓慢地从其对应的主网络同步过来。这个机制如同为训练过程安装了缓冲器,能有效防止单步更新过大导致的策略震荡和价值估计发散,使得学习曲线更加平滑稳定。
为了更直观地进行对比,我们将这四类网络的关键特性汇总如下:
| 网络名称 | 数量 | 输入维度 | 输出维度 | 训练 / 更新方式 | 运行阶段 |
| Actor(主) | 3 | 18(局部观测) | 5(动作) | 反向传播梯度更新 | 交互 + 训练 |
| Target Actor | 3 | 18(局部观测) | 5(动作) | 软更新(跟随主 Actor) | 仅训练 |
| Critic(主) | 1 | 69(全局拼接) | 1(Q 值) | 反向传播梯度更新 | 仅训练 |
| Target Critic | 1 | 69(全局拼接) | 1(Q 值) | 软更新(跟随主 Critic) | 仅训练 |
MADDPG网络更新机制
理解了网络结构后,我们进一步剖析它们是如何通过学习和优化来实现收敛的。这个过程是MADDPG算法效能的核心。
主策略网络(Actor)的更新
Actor的优化目标非常明确:调整自身策略,使得其选择的动作能获得Critic网络更高的价值评分。因此,其损失函数直接定义为负的Q值平均值。换言之,Actor的训练过程就是最大化Critic对其当前动作组合的评估。
用公式表示为:actor_loss = -torch.mean( Q )。通过对此损失进行反向传播,Actor网络的参数得以调整,使其在未来更倾向于选择能够带来更高全局回报的动作。
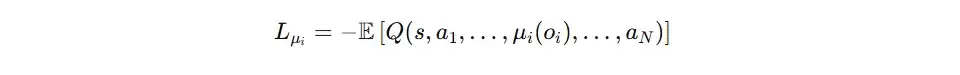
主价值网络(Critic)的更新
Critic的更新目标是使其预测的Q值尽可能接近真实的回报。它学习的目标是基于时序差分(TD)的目标值,即当前即时奖励加上经过折扣的未来状态价值估计。
具体步骤为:将下一时刻的全局状态,以及由所有Target Actor根据该状态生成的下一时刻联合动作,一同输入Target Critic网络,得到对未来回报的估计值q_。若当前回合终止,则q_设为0。最终的目标值计算公式为:target = rewards + gamma * q_(其中gamma为折扣因子,例如0.99)。
随后,Critic的损失函数即为其预测值q与目标值target之间的均方误差(MSE):critic_loss = F.mse_loss(q, target)。通过最小化此损失,Critic网络逐步学会更精确地评估任意给定全局状态和联合动作对的长期价值。
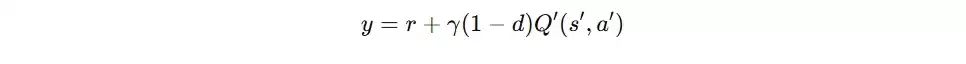
目标网络的软更新策略
为确保训练稳定性,目标网络的参数不会在每一步都硬性替换为主网络的参数,而是采用缓慢混合的软更新方式:
target_params = tau * main_params + (1 - tau) * target_params
其中,tau是一个很小的混合系数(例如0.01或0.005)。这意味着目标网络的参数在每次更新时,只会向主网络参数的方向移动一小步,从而平滑了价值目标的更新过程,有效避免了训练发散。
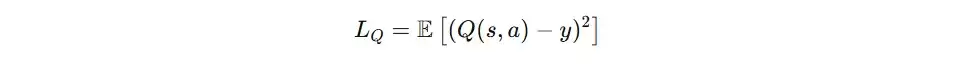
MADDPG计算流程实例演示
为了更具体地理解MADDPG的数据流,我们通过一个简化的计算示例来感受其运作过程。以Agent 0的主Actor为例:
输入观测向量(18维):
[ -0.122, -0.156, -0.343, 0.371, 0.590, -0.136,
0.622, -0.635, -0.316, -0.383, -0.077, -0.410,
0.080, -1.219, 0,0,0,0 ]
Actor网络生成原始动作:
[0.21, 0.77, 0.34, 0.11, 0.89]
在训练阶段,为了探索,会在此动作上添加噪声,并截断至合法范围,假设得到:
最终与环境交互的执行动作:
[0.23, 0.74, 0.35, 0.09, 0.93]
接下来,主Critic网络开始工作。它需要接收全局信息:
全局状态 states (54维): 由三个智能体的观测拼接而成。
states = [
# agent_0 (18维)
-0.122, -0.156, -0.343, 0.371, 0.590, -0.136,
0.622, -0.635, -0.316, -0.383, -0.077, -0.410,
0.080, -1.219, 0, 0, 0, 0,
# agent_1 (18维)
0.175, 0.145, -0.420, -0.039, 0.667, 0.274,
0.699, -0.224, -0.239, 0.026, 0.077, 0.410,
0.157, -0.808, 0, 0, 0, 0,
# agent_2 (18维)
-0.028, 0.555, -0.263, -0.847, 0.510, 1.083,
0.542, 0.583, -0.396, 0.835, -0.080, 1.219,
-0.157, 0.808, 0, 0, 0, 0
]
全局动作 actions (15维): 由三个智能体的动作拼接而成。
actions = [
# agent_0 (5维)
0.23, 0.74, 0.35, 0.09, 0.93,
# agent_1 (5维)
0.44, 0.12, 0.88, 0.56, 0.23,
# agent_2 (5维)
0.65, 0.33, 0.21, 0.90, 0.10
]
环境执行这组联合动作后,反馈一个全局奖励:
rewards = [-0.791]
随后进入损失计算环节。首先,需要利用目标网络计算未来奖励的估计。假设我们已获得下一时刻的全局状态,并由所有Target Actor生成了下一时刻的联合动作,然后将它们输入Target Critic。
假设Target Critic输出的未来Q值估计q_ = 0.0(可能因为回合结束)。那么,TD目标值计算如下:
target = rewards + gamma * q_
target = -0.791 + 0.99 * 0.0
target = -0.791
同时,假设主Critic对当前状态动作对的预测值q为-0.75。那么,Critic的损失为:
critic_loss = F.mse_loss(q, target)
# 计算过程:( -0.75 - (-0.791) )^2 = (0.041)^2 = 0.001681
对于Actor的损失,假设在训练更新时,主Critic对当前Actor新生成的动作(基于拆分后的全局状态计算)给出的平均Q值为0.9,那么Actor的损失为:
actor_loss = -torch.mean(Q) = -0.9
通过这样一轮轮持续的前向计算、奖励反馈和反向传播优化,Actor和Critic网络不断迭代改进,最终引导多个智能体学会协同行为,共同完成复杂任务目标。
相关攻略

MADDPG算法通过“集中式训练,分布式执行”解决多智能体环境非平稳性问题。训练时,每个智能体拥有独立的策略网络,但共享一个能获取全局信息进行准确评估的价值网络。执行时则仅依赖局部观测。算法包含主网络与目标网络,采用确定性策略与软更新机制确保训练稳定。

Cursor发布Composer2模型,性能接近ClaudeOpus但成本显著降低。其训练结合中期训练与强化学习,使模型能察觉环境差异并专注于生成正确代码。针对浮点运算非确定性对MoE训练的挑战,需通过技术确保计算一致性。算力分配上,约三分之一用于推理可达效率最优。该模型专为编程任务优化,较小规模即可实现高性能。

在强化学习领域,如果要评选一款“通用型”算法,PPO(近端策略优化)无疑是首选。它之所以能广泛应用于游戏AI、机器人控制乃至大语言模型对齐任务,关键在于其卓越的稳定性——易于实现、训练过程可靠,并能同时处理离散与连续动作空间。 简而言之,PPO属于策略梯度算法系列,但它引入了一个关键约束:严格限制新

GRPO是PPO算法的简化版本,旨在降低计算成本与调参难度。它仅训练一个Actor网络,通过比较同一提示词下多个回答的组内相对奖励来替代优势函数估计,并保留了PPO的裁剪机制与KL散度正则项。这种设计显著减少了显存占用,提升了训练稳定性,同时防止模型能力退化。

在生命科学全面迈入空间组学的今天,科学家们拥有了前所未有的能力——在细胞甚至亚细胞分辨率下,同时观测成百上千种RNA和蛋白质。然而,这项碘伏性技术的背后,却横亘着一个让所有研究者都头疼的经典难题:面对一张组织切片,宝贵的视场角(FOV)究竟应该选在哪里? 2026年5月25日,来自复旦大学和北京理工
热门专题







热门推荐

《Paralives》开发商承诺所有后续更新永久免费,拒绝付费DLC模式。15人小团队依靠首发销售额即可支撑多年运营,无需依赖额外内容包维持开发,展现了与《模拟人生》系列不同的差异化竞争思路。

2025年5月28日,比亚迪王朝网全新力作——宋Ultra DM-i正式推向市场,共推出5款配置车型,官方售价区间为12 99万至15 99万元。此次定价策略极具突破性:一款拥有310公里纯电续航能力的中型插电混动SUV,直接下探至13万元级别市场。作为王朝网络的新旗舰,该车明确瞄准高频出行需求场景

先来关注一个有趣的细节:苹果首款折叠屏手机,传闻将于今年秋季正式亮相。产品命名可能为iPhone Ultra,也有媒体称之为iPhone Fold——无论最终叫什么,这都将标志着苹果在折叠形态领域首次“出手”。 近日,配件厂商iFunSmart已率先上架iPhone Ultra的首批保护壳——这绝非

山寨币ETF迎来批量上市潮,首批项目市场表现如何?一文分析 Binance币安 欧易OKX ️ Huobi火币️ 最近,市场出现了一个不容忽视的新动向:XRP、DOGE、LTC、HBAR等现货ETF已经悄然登陆美国市场。与此同时,A VAX、LINK等资产的同类产品也正在审批流程中。进入11月以来,

近日,公司对SteamDeck1TBOLED版涨价300美元至949美元,上架短短不到24小时便再度售罄。据外界分析,该公司从中国大量补货并分批投放库存,高溢价未影响众多玩家的抢购热情与速度,其人气极其旺盛无比足以支撑快速清空。