PPO算法详解 图解近端策略优化原理与计算步骤
在强化学习领域,如果要评选一款“通用型”算法,PPO(近端策略优化)无疑是首选。它之所以能广泛应用于游戏AI、机器人控制乃至大语言模型对齐任务,关键在于其卓越的稳定性——易于实现、训练过程可靠,并能同时处理离散与连续动作空间。
简而言之,PPO属于策略梯度算法系列,但它引入了一个关键约束:严格限制新旧策略之间的更新幅度。这种设计既保证了策略性能的稳步提升,又避免了因更新过大导致的训练振荡或策略崩溃。此外,PPO支持样本复用,显著提升了数据利用效率。

PPO 算法的网络结构
PPO的核心架构通常由两个神经网络组成,它们各司其职,协同完成学习任务。
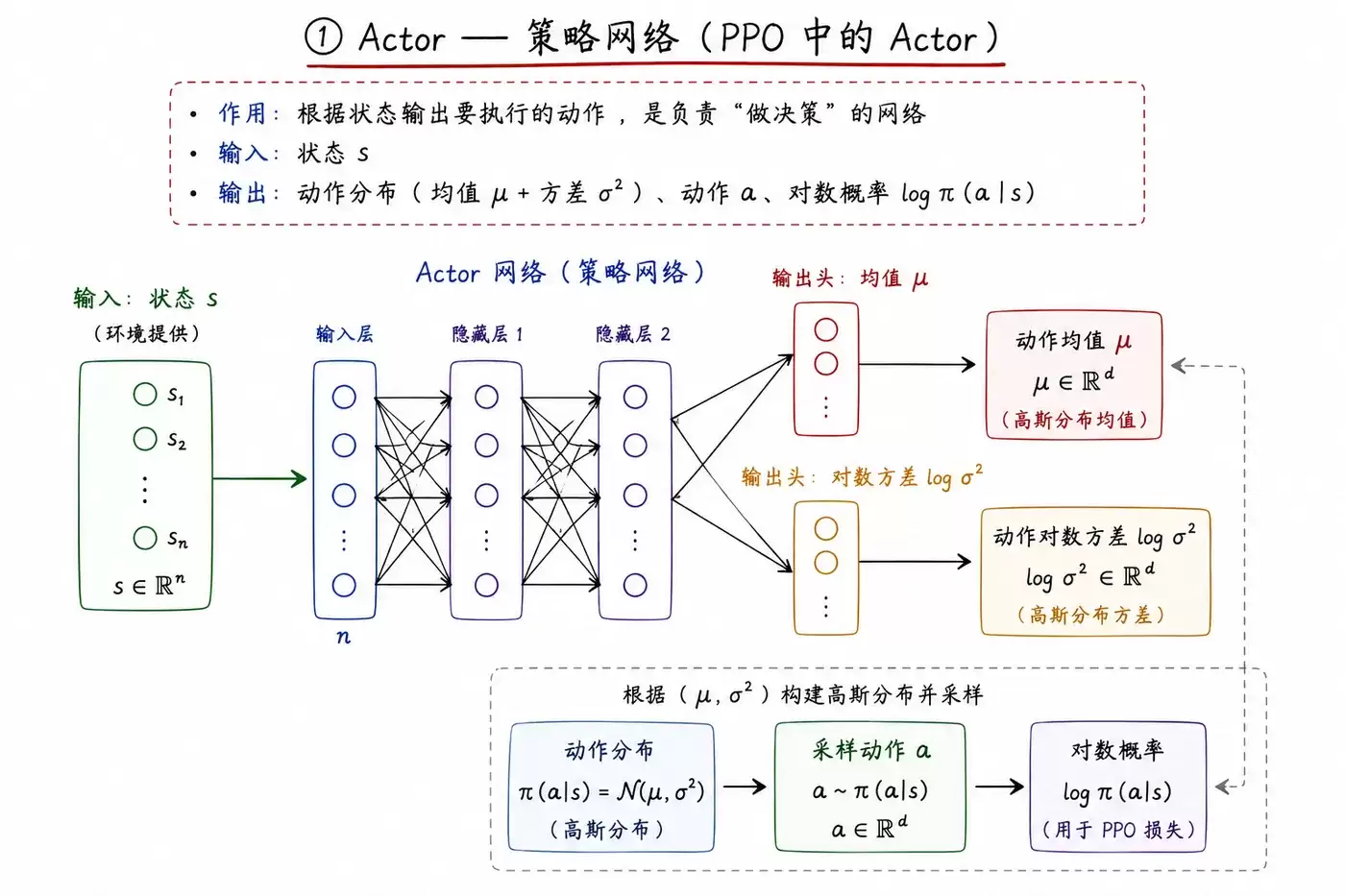
① Actor —— 策略网络
你可以将Actor网络视为系统的“决策中枢”。
- 输入: 当前的环境状态(State s)。
- 输出: 动作的概率分布(对于连续动作,输出均值和方差)、最终执行的动作a,以及该动作的对数概率 log π(a|s)。
- 核心作用: 根据当前感知的状态,决定智能体应采取的具体行为。它负责“执行”。
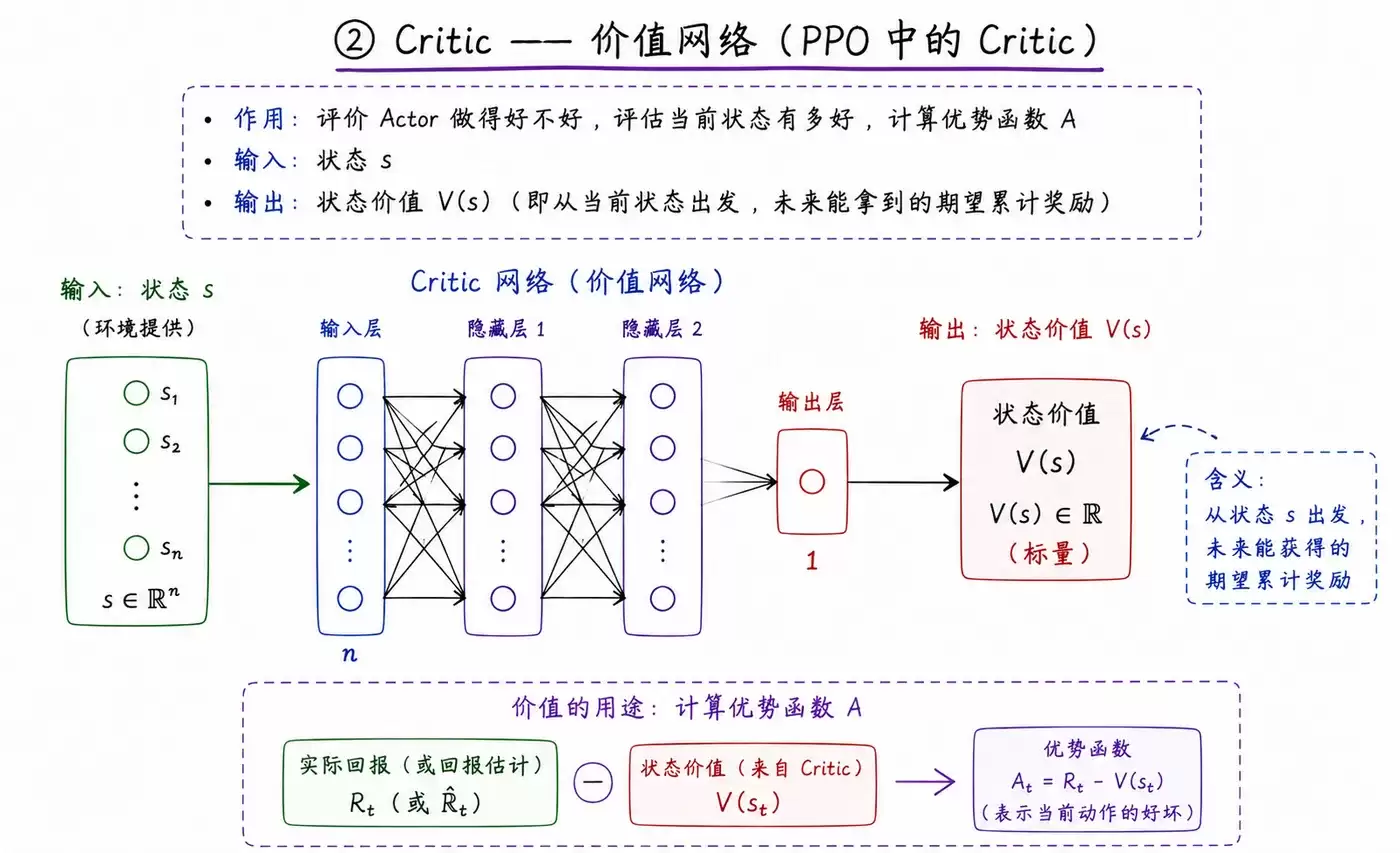
② Critic —— 价值网络
而Critic网络,则扮演着“评估专家”的角色。
- 输入: 同样是状态 s。
- 输出: 当前状态的价值估计 V(s)。这个数值评估了处于该状态的长期收益预期,即未来可能获得的累积奖励。
- 核心作用: 评估Actor决策的优劣,并计算出关键的“优势函数”(Advantage),用以指示特定动作相对于平均表现的优势或劣势程度。
网络更新
训练过程是这两个网络持续优化的循环。PPO遵循一个重要原则:采样时使用旧策略执行动作,网络更新时则用新策略计算旧动作的概率。新策略生成的动作需等到下一轮数据采集时才会被执行,这确保了训练数据的一致性。
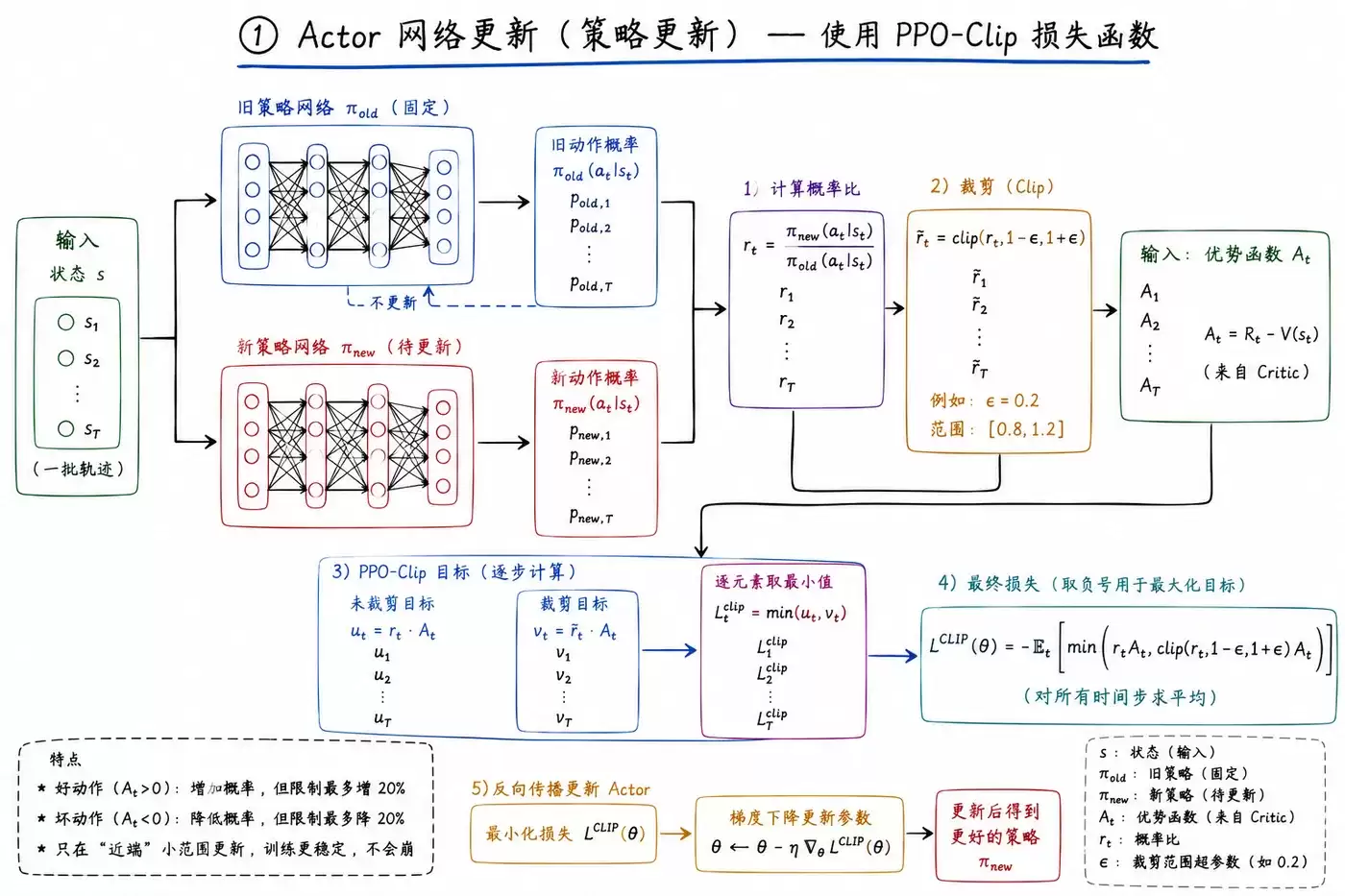
① Actor 网络更新(策略更新)
Actor的更新是PPO算法的核心,其目标是:增加高回报动作的概率,降低低回报动作的概率,同时将所有更新约束在一个安全的阈值内。
- 使用损失函数: PPO-Clip。
- 输入要素: 状态s、旧策略下动作的概率(π_old)、新策略下同一动作的概率(π_new)、以及Critic网络提供的优势函数A。
- 计算步骤:
- 计算新旧策略的概率比率 r = π_new / π_old。
- 将该比率r裁剪(clip)到预设的区间内,例如 [1-ε, 1+ε],当ε=0.2时,区间为[0.8, 1.2]。
- 计算最终损失:取 min( r * A, clip(r) * A )。这一步有效防止了因优势估计异常而导致的更新幅度失控。
- 通过反向传播算法更新Actor网络参数。
- 核心特点: 更新被限制在“近端”的小范围内,训练过程极其稳定,从根本上解决了传统策略梯度方法中常见的策略“崩溃”问题。
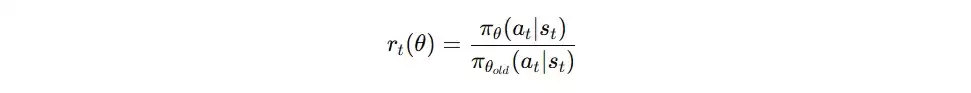
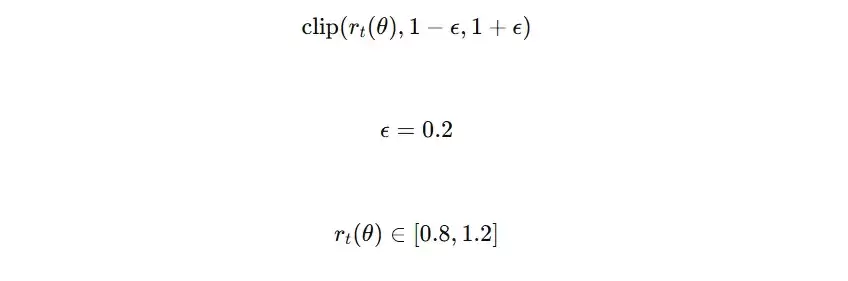
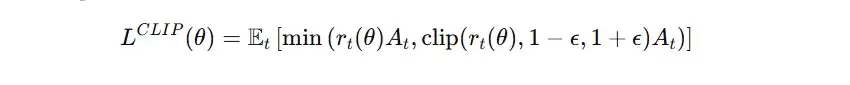
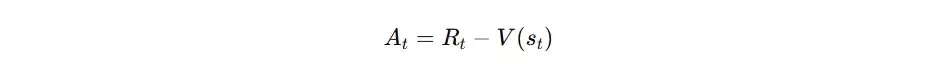
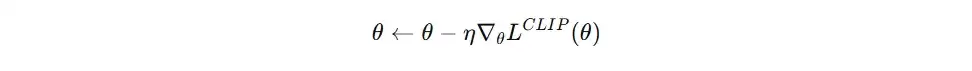
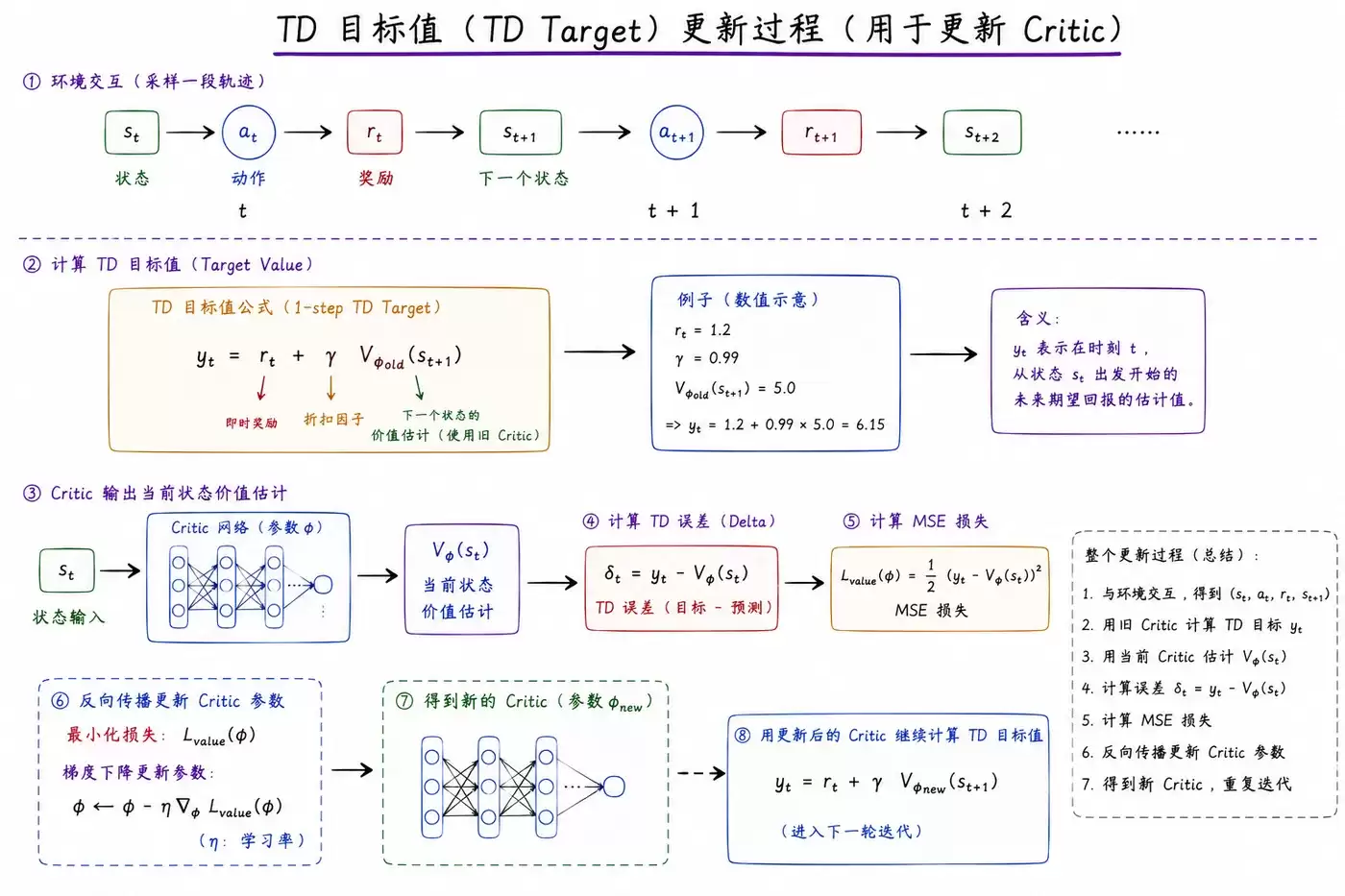
② Critic 网络更新(价值评估更新)
Critic网络的更新相对直接,目标是使其对状态价值的预测越来越精准。
- 使用损失函数: 均方误差(MSE)。
- 输入要素: 状态s,以及实际回报G或时序差分(TD)目标值。
- 计算过程: Critic网络输出对当前状态的估值V(s),计算该估值与目标回报之间的误差,然后使用MSE损失进行反向传播,从而更新Critic网络参数。
- 核心作用: 通过提供更准确的优势信号,来更有效地指导Actor网络的策略优化方向。
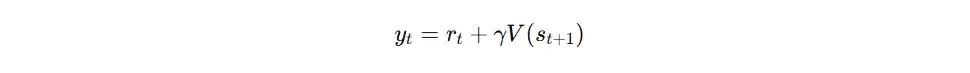
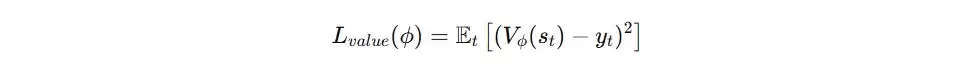
手动计算
要深入理解PPO算法,动手计算是关键。我们聚焦于两个核心环节:广义优势估计(GAE)和模型更新过程。
广义优势估计
优势函数A用于衡量特定动作相对于策略平均表现的优劣。GAE是一种高效的方法,它通过融合多步时序差分(TD)误差,得到更平滑、方差更低的优势估计值。
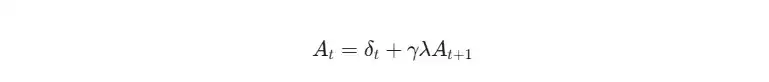
TD误差(td_delta)是计算基础:
td_delta = 即时奖励 + 折扣因子×下一个状态价值 - 当前状态价值GAE优势(advantage)通过递归方式计算:
advantage = 当前TD误差 + 衰减系数 × 下一步的advantage举例说明,假设我们有三步的TD误差序列:`[10, 5, -10]`,设定衰减系数(γ * λ)为0.81。我们从最后一步开始向前递推计算:
t=2: advantage = -10 + 0.81×0 = -10
t=1: advantage = 5 + 0.81×(-10) = -3.1
t=0: advantage = 10 + 0.81×(-3.1) = 7.489
最终得到的GAE优势序列为:[7.489, -3.1, -10]模型更新(update)
下面我们模拟一个简化的更新流程。假设参数设置如下:折扣因子γ=0.9,GAE参数λ=0.9,裁剪范围ε=0.2(对应区间[0.8, 1.2])。
我们拥有两条样本数据:
state0 = [1.0, 0.0, 1.0, 0.0, 0.0, 0.0], action0 = 0
state1 = [0.9, 0.1, 0.8, 0.2, 0.5, 0.1], action1 = 2
对应的优势函数值为:advantage = [-0.82, -2.0]1. 计算新旧概率比(ratio)
首先,需要获取旧策略和新策略分别产生这些动作的概率。假设通过模型前向传播得到对数概率:
旧策略:old_log_prob0 ≈ -0.357, old_log_prob1 ≈ -2.303
新策略:new_log_prob0 ≈ -0.094, new_log_prob1 ≈ -3.000计算概率比(通过对数概率差取指数得到):
ratio0 = exp( (-0.094) - (-0.357) ) = exp(0.263) ≈ 1.30
ratio1 = exp( (-3.000) - (-2.303) ) = exp(-0.697) ≈ 0.50可见,ratio0=1.30超出了裁剪上限1.2,ratio1=0.50则低于裁剪下限0.8。
2. 计算PPO Clip策略损失(policy_loss)
针对第一条样本(ratio0=1.30, adv0=-0.82):
未裁剪部分:1.30 * (-0.82) = -1.066
裁剪后部分:clip(1.30→1.2) * (-0.82) = -0.984
取两者中较小的:min(-1.066, -0.984) = -1.066针对第二条样本(ratio1=0.50, adv1=-2.0):
未裁剪部分:0.50 * (-2.0) = -1.0
裁剪后部分:clip(0.50→0.8) * (-2.0) = -1.6
取两者中较小的:min(-1.0, -1.6) = -1.6策略损失是这些值的负平均值(因为优化器通常以最小化损失为目标):
policy_loss = - [ (-1.066) + (-1.6) ] / 2 = - [ -2.666 / 2 ] = 1.3333. 计算价值损失(value_loss)
假设Critic网络对两个状态的估值为:V(s0) = -3.18, V(s1) = 0.0。目标回报(TD目标)假设为:td_target0 = -1.0, td_target1 = 0.0。
使用均方误差计算价值损失:
loss0 = (-3.18 - (-1.0))^2 = (-2.18)^2 = 4.75
loss1 = (0.0 - 0.0)^2 = 0
value_loss = (4.75 + 0) / 2 = 2.375手算最终结果
ratio0 = 1.30, ratio1 = 0.50
policy_loss = 1.333
value_loss = 2.375
通过这样一个从理论推导到手动计算的全过程,PPO如何通过裁剪机制实现稳定更新,以及Actor和Critic网络如何协同优化,便一目了然。这正是PPO算法能够成为工业级强化学习首选方案的深层原因。
相关攻略

在强化学习领域,如果要评选一款“通用型”算法,PPO(近端策略优化)无疑是首选。它之所以能广泛应用于游戏AI、机器人控制乃至大语言模型对齐任务,关键在于其卓越的稳定性——易于实现、训练过程可靠,并能同时处理离散与连续动作空间。 简而言之,PPO属于策略梯度算法系列,但它引入了一个关键约束:严格限制新

GRPO是PPO算法的简化版本,旨在降低计算成本与调参难度。它仅训练一个Actor网络,通过比较同一提示词下多个回答的组内相对奖励来替代优势函数估计,并保留了PPO的裁剪机制与KL散度正则项。这种设计显著减少了显存占用,提升了训练稳定性,同时防止模型能力退化。

在生命科学全面迈入空间组学的今天,科学家们拥有了前所未有的能力——在细胞甚至亚细胞分辨率下,同时观测成百上千种RNA和蛋白质。然而,这项碘伏性技术的背后,却横亘着一个让所有研究者都头疼的经典难题:面对一张组织切片,宝贵的视场角(FOV)究竟应该选在哪里? 2026年5月25日,来自复旦大学和北京理工

强化学习训练需找到智能体能力边界附近的“最近发展区”。研究提出PACE方法,直接利用策略参数变化衡量关卡诱导的学习进展,动态生成高价值训练课程。实验表明,PACE在迷宫和开放式任务中显著提升了智能体的零样本泛化能力和持续学习性能。

阿里通义实验室推出强化学习框架EAPO,专注于提升长文本推理的准确性。该框架通过结构化证据推理和多粒度奖励机制,将监督重点转向证据提取过程。基于300亿参数模型训练的EAPO在多项测试中表现优异,综合得分超越更大规模闭源模型,有效降低了证据与推理错误率。
热门专题







热门推荐

如果你在使用QoderWake数字员工时,经常重复执行“查日志、过滤ERROR、导出最近1小时”这类固定流程,却尚未掌握宏指令功能,那么你的工作效率仍有巨大提升空间。效率瓶颈通常源于未能将指令组合有效绑定,或未正确触发宏录制机制。实现重复操作的一键自动化其实很简单,只需掌握五个核心步骤:启用宏录制、

一、AI如何快速预览画板内容:原理与价值解析 人工智能技术正深度融入各行各业,其应用场景持续拓展。其中,利用AI对画板内容进行智能预览与分析,已成为提升工作效率的重要实践。这项功能看似基础,却能切实帮助设计师、项目管理者及广大用户节省时间、优化决策流程。 AI预览技术在各行业的具体应用场景 AI技术

在《时空猎人觉醒》中,角色养成需系统化推进:通过主线任务升级解锁技能,强化装备、镶嵌宝石以提升战力。合理分配技能点,培养宠物获得加成,利用强化与符文系统增强属性。参与活动获取稀有资源,组队副本学习技巧,完成日常积累资源。养成需随版本动态调整,多维度投入方能打造强力角色。

币安与Web3 0的深度融合 当区块链技术以惊人的速度迭代,下一代互联网——Web3 0的轮廓也日益清晰。它描绘的,是一个去中心化、用户真正掌控数据、价值自由流动的新世界。在这场深刻的变革中,币安交易所凭借其前瞻性的布局和强大的执行力,已然成为探索与实践Web3 0理念的先锋。那么,币安究竟是如何借

工信部批复6GHz频段用于6G试验,为关键技术攻关提供支撑。该频段在覆盖与带宽间取得更好平衡,利于降低部署成本。6G研发聚焦超大规模MIMO、子带全双工及通感一体化等方向,旨在提升频谱效率并融合通信感知能力。目前3GPP已启动6G系统研究,首个标准版本计划于Release21发布,预计2030年前后实现商用。