图解强化学习GRPO算法原理与手算步骤详解
在强化学习与大语言模型对齐的研究中,PPO算法以其出色的训练稳定性与效果而备受推崇。然而,其经典的Actor-Critic双网络设计也伴随着较高的计算资源消耗与复杂的超参数调优挑战。本文将深入解析一种旨在克服这些挑战的创新算法——GRPO(分组相对策略优化),探讨其如何以更精简的架构实现高效对齐。
GRPO 算法的基础认识
GRPO,全称为分组相对策略优化,可被视为PPO算法的一种高效简化版本。其核心理念非常直接:摒弃独立的价值网络评估,转而利用同一提示词下生成的多组回答进行内部奖励比较,以此替代PPO中复杂的优势函数估计过程。
具体而言,针对给定的提示,模型会并行生成多个候选回答,并获取每个回答的奖励评分。GRPO算法并不关注奖励的绝对数值,而是聚焦于这些评分在组内的相对排序与分布(例如通过归一化处理),从而判断哪些回答更优,并据此指导策略网络的更新。同时,它完整继承了PPO的核心稳定机制——策略更新裁剪,确保每次迭代的调整幅度可控。此外,算法引入了KL散度正则项,有效约束优化过程中的策略偏移,保障模型的基础能力与知识不会在微调中退化。
因此,GRPO的设计目标清晰明确:在维持甚至提升长文本推理与训练稳定性的前提下,大幅降低大语言模型进行人类反馈强化学习所需的显存开销与计算成本。
GRPO 算法的网络结构
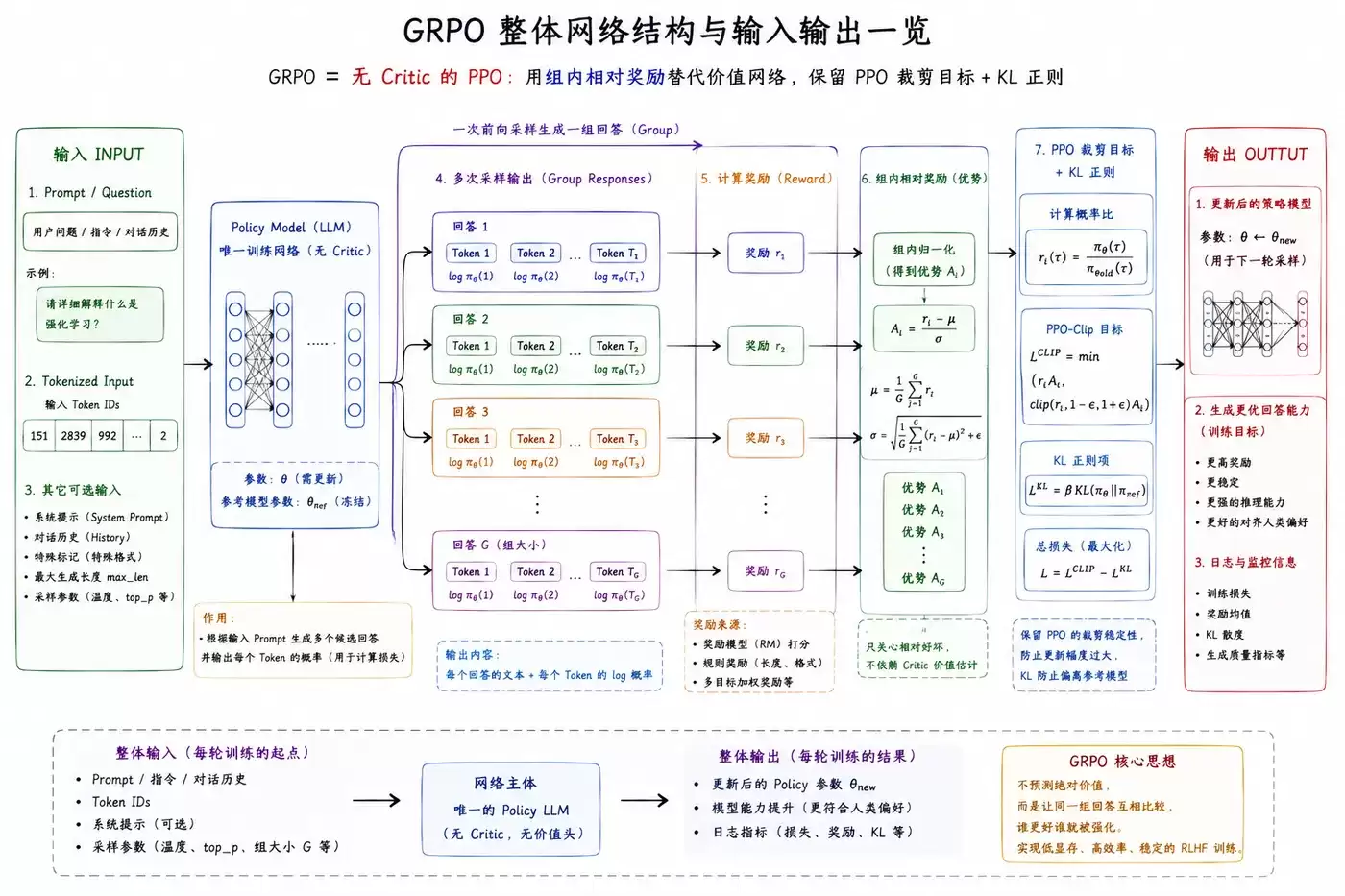
GRPO的网络结构是其“极简”设计哲学的直接体现。
Actor网络
唯一的可训练网络: 在GRPO框架中,需要被训练的网络有且仅有一个,即作为策略网络的Actor模型。
输入与输出: 它接收文本状态(提示词),并输出对应的动作(文本序列)、该动作的生成概率对数,以及与参考模型之间的KL散度值。
核心职能: 该网络承担了内容生成与提供训练信号的双重任务。整个训练流程,包括策略的迭代优化,都围绕这单一网络展开。
关于其架构,有几点关键说明:
首先,GRPO的结构极为精简。它移除了传统的Q网络、价值网络、目标网络,甚至无需学习温度参数,架构干净利落。
其次,训练过程中会固定一个参考模型(通常为初始的监督微调模型)。该模型参数冻结,不参与梯度更新,其唯一作用是作为计算KL散度正则项的基准锚点,防止当前策略过度偏离。因此,它不被计入可训练网络。
网络更新
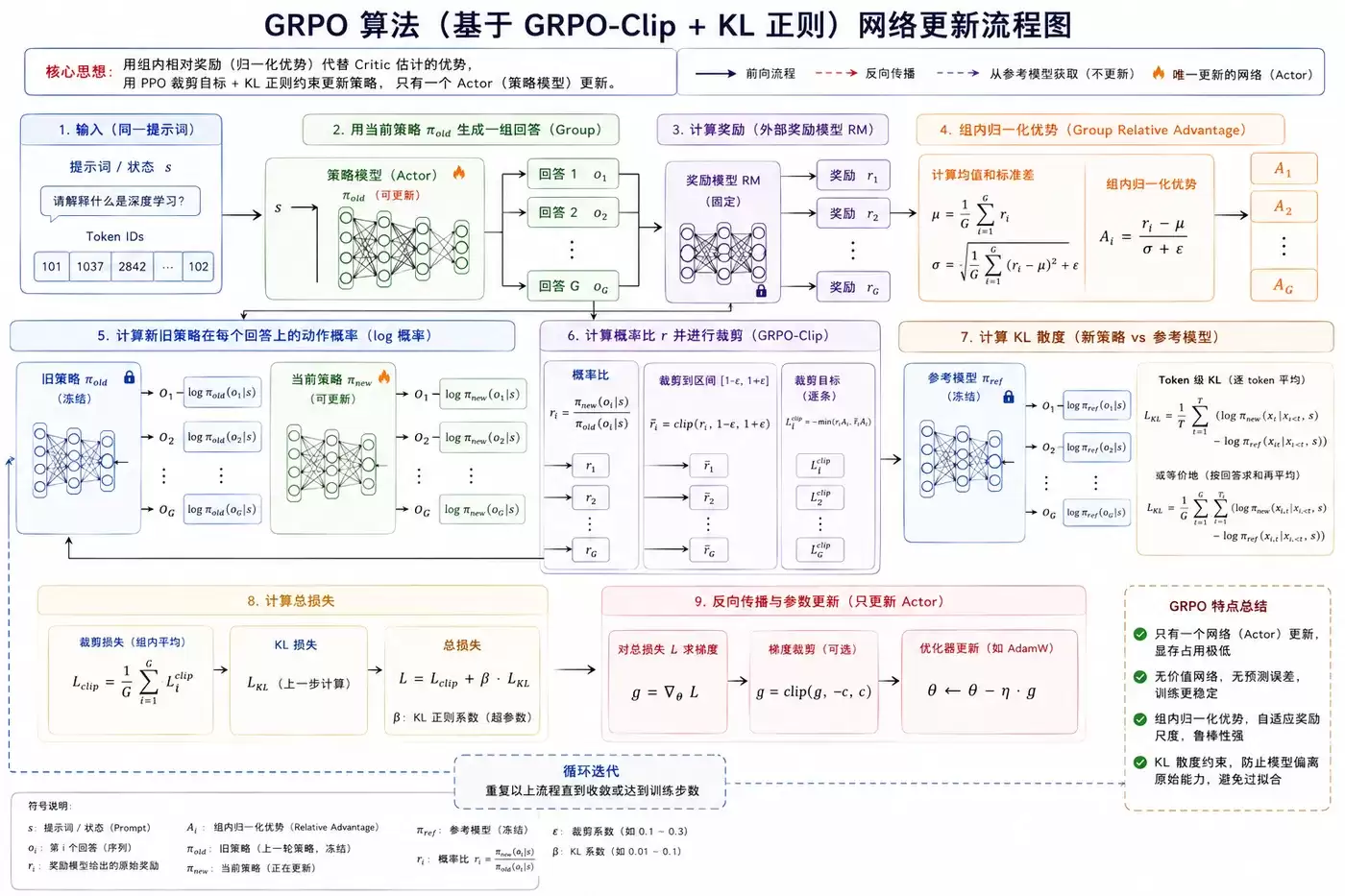
GRPO的更新机制融合了PPO的精华并进行了关键创新。
核心损失函数: GRPO-Clip裁剪损失 + KL散度正则损失。
根本目标: 通过策略更新,使同一组回答中质量更高的输出拥有更高的生成概率,同时严格限制更新步长,确保训练过程稳定,避免模型性能崩溃或严重偏离原始分布。
更新流程与输入:
每次策略更新需要准备以下输入数据:
- 状态/提示词 (s)
- 旧策略下的动作概率 (π_old)
- 新策略下的动作概率 (π_new)
- 组内归一化优势 (A),该值来源于对同一提示词下多个回答的奖励进行组内计算与归一化处理。
- 参考模型的概率分布 (π_ref),用于计算KL散度。
计算步骤可概括如下:
- 计算新旧策略的概率比率:r = π_new / π_old。
- 将该比率裁剪至预设的安全区间,例如 [1-ε, 1+ε]。
- 通过公式 min(r*A, clip(r)*A) 计算得到裁剪损失项。
- 计算当前策略与参考模型之间的KL散度。
- 总损失 = 裁剪损失 + β * KL散度(其中β为正则化系数)。
- 最后,通过反向传播算法,更新唯一的Actor网络参数。

这种设计带来了若干显著优势:
- 显存占用大幅降低: 仅需维护和更新一个网络,极大节约了GPU显存资源。
- 训练过程高度稳定: 由于无需估计价值函数,彻底避免了因价值网络估计偏差带来的训练波动与不稳定性。
- 有效防止模型退化: KL散度约束如同“安全绳”,确保模型在优化特定目标时,其原有的语言理解与生成能力得以保留。
- 降低奖励尺度敏感度: 基于组内归一化的优势计算方式,使得算法对奖励函数的绝对数值范围不敏感,减轻了超参数调整的负担。

相关攻略

GRPO是PPO算法的简化版本,旨在降低计算成本与调参难度。它仅训练一个Actor网络,通过比较同一提示词下多个回答的组内相对奖励来替代优势函数估计,并保留了PPO的裁剪机制与KL散度正则项。这种设计显著减少了显存占用,提升了训练稳定性,同时防止模型能力退化。

在生命科学全面迈入空间组学的今天,科学家们拥有了前所未有的能力——在细胞甚至亚细胞分辨率下,同时观测成百上千种RNA和蛋白质。然而,这项碘伏性技术的背后,却横亘着一个让所有研究者都头疼的经典难题:面对一张组织切片,宝贵的视场角(FOV)究竟应该选在哪里? 2026年5月25日,来自复旦大学和北京理工

强化学习训练需找到智能体能力边界附近的“最近发展区”。研究提出PACE方法,直接利用策略参数变化衡量关卡诱导的学习进展,动态生成高价值训练课程。实验表明,PACE在迷宫和开放式任务中显著提升了智能体的零样本泛化能力和持续学习性能。

阿里通义实验室推出强化学习框架EAPO,专注于提升长文本推理的准确性。该框架通过结构化证据推理和多粒度奖励机制,将监督重点转向证据提取过程。基于300亿参数模型训练的EAPO在多项测试中表现优异,综合得分超越更大规模闭源模型,有效降低了证据与推理错误率。

强化学习是一种让智能体通过与环境交互、从试错中学习最优决策策略的人工智能技术。其核心机制类似于训练宠物:做出正确行为给予奖励,错误行为则没有。智能体在模拟或真实环境中不断尝试,根据反馈调整策略,最终找到获得最高累积回报的行动序列。然而,传统强化学习的样本效率低下是公认的难题——智能体往往需要数百万甚
热门专题







热门推荐

当一家头部量化私募机构,凭借自主研发的AI Agent智能体矩阵,仅耗时7天就高效完成了以往需要长达90天甚至180天才能走完的完整研究流程时,一个明确的行业信号已然显现:人工智能在量化投资领域的应用深度,已从初期锦上添花的辅助角色,全面升级为足以重构整个行业生产力底层逻辑的核心基础设施。 然而,这

思维导图能有效梳理思路并提升信息传递效率。在PPT中可通过三种方法制作:一是利用SmartArt图形快速插入并编辑层次结构;二是手动绘制形状和连接线以实现高度自定义;三是借助专业软件制作后以图片形式插入。这些方法均旨在通过视觉化工具使幻灯片内容更清晰有条理。

港股AI大模型板块持续走强,MiniMax与智谱被视为“双子星”引领板块。MiniMax被纳入相关指数带来资金支撑,智谱凭借GLM架构占据核心地位。板块驱动因素包括监管趋于明确、商业化进展不断兑现以及被动资金持续流入。市场正从概念炒作转向验证真实技术与商业落地能力,推动相关标的价值重估。

在《饼干人联盟》的冒险旅程中,欢乐果冻森林的1-10关卡是许多玩家遇到的第一个重要挑战。这一关不仅是前期资源积累的关键节点,也是检验队伍配置与操作技巧的绝佳机会。为了帮助大家顺利攻克难关并获取丰厚奖励,我们准备了这份详细的通关攻略。 一、关卡BOSS解析:幸福花 本关的守关首领是幸福花。虽然名字听起

伊朗电信基础设施迎来重要升级。该国于26日正式宣布,其国际互联网带宽与连接已实现稳定、全面的恢复。 此次恢复意味着,伊朗境内的固定宽带用户现已能够顺畅访问全球网络,正常使用国际网站、在线应用及各类数字服务。此前,伊朗通信部门已多次表明,正在有序推进国际互联网接入的修复与优化工作。官方强调,此举旨在从