神译局是旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:当AI能在瞬间完乘人类200小时的工作,谁会成为新的“瓶颈”?一场来自METR的桌面演练揭示:未来的竞争格局正在发生根本性转变——纯粹的执行力将急速贬值,而人类的判断力与反馈效率,将成为唯一的决胜关键。文章来自编译。

引言
METR的目标很明确:让公众能及时、清晰地了解AI的真实能力及其潜在风险。从某些衡量标准看,AI堪称有史以来发展最迅猛的技术。更值得关注的是,随着AI开始将自身的研发过程自动化,这一进程还可能进一步加速。可以预见,到明年年底,新模型的发布频率以及所需的新评估数量,很可能会达到一个临界点——如果没有高效AI的辅助,仅靠人类自身,连有效获取信息都可能变得困难重重。我们绝不能等到这类AI增强型工作流变得不可或缺时,才手忙脚乱地去适应;理解并驾驭它们,必须从现在开始。
基于这个紧迫的背景,我们设计并运行了一场为期2小时的桌面演练:三位METR的研究员扮演现实中的自己,处理真实的工作重点,但设定他们可以使用能连续工作约200小时的AI——这大致是对未来12到18个月后技术水平的预期。演练的核心目的,是探究在这种条件下会产生哪些新型工作流、瓶颈会出现在哪里,以及我们的实际工作效率究竟能提升多少。
演练过程
场景
模拟世界
- METR独家拥有时间跨度达200小时的AI来自动化工作;而世界其他部分使用的仍是2026年2月的真实技术(即时间跨度约12小时的AI)。
- 我们配备了适用于200小时跨度AI的Codex/Claude Code版本,以及一套基础的项目管理工作流。
- 但演练的“当前时间”设定在2026年2月,因此我们评估的是2026年的AI模型,使用2026年版本的Inspect工具,并通过电子邮件等常规方式与人沟通。
AI 能力
- AI拥有约200个人类小时的时间跨度,但其相对能力特征与2026年初的AI相似。
- 它们在可验证的任务上表现惊人,在复杂、凌乱的任务上表现尚可。
- AI的运行速度是Claude 4.6 Opus快速模式的两倍,并且我们负担得起以此速度运行模型的成本。
- 对于与HCAST任务平均“复杂程度”相当的可验证任务,200个人类小时的工作量对应50%的成功率,而40个人类小时则对应80%的成功率。
- 对于较难验证的任务,其成功程度由游戏主持人(GM)裁定。
- 在写作方面,如果AI具备相关上下文,其水平相当于METR的入职级员工。
游戏玩法
- 一名经理和两名研究员扮演现实中的自己及其当前工作重点。Thomas Kwa担任游戏主持人。
- 每个回合代表半天,每天进行两次站会。现实中每个回合占用15分钟:其中5分钟用于站会,10分钟用于模拟5小时的工作。最终,我们完成了4个回合(模拟了2天的工作时间)。[1]
- 所有参与者同时在电子表格中记录,每小时填写自己和智能体的操作,并在必要时咨询主持人。下图展示了电子表格的截图。

图1:Nate Rush正疯狂地向未来版本的Claude发送提示词,以改进人类数据基础设施。到了第二天,他会意识到,仅仅是理解Joel和Tom的智能体所构建的内容,就已经让他应接不暇了。
Thomas Kwa 的观察
我们的效率提升了多少?
大多数参与者的估计是,与仅使用2026年2月技术相比,效率提升了大约3到5倍(意味着在这模拟的2天内,完成了相当于1到2周的工作量)。不过,这个数字不宜过度解读,因为它可能受到对实际完成量乐观评估的影响,而且不同团队之间的差异会非常巨大。相比之下,定性结论往往更有趣。
在此前提下,一个有趣的发现是:如果时间跨度是2026年2月模型的17倍,却只带来了3倍的效率提升,那么时间跨度与加速比之间的关系大致符合($加速比 \propto TH^{0.39}$)的规律。这暗示着,效率的提升并非与AI能力线性增长。
实际体感如何?
在这次3人演练以及之前进行的两次单人Alpha测试中,几个共同的主题浮现出来:
- 想法跟不上执行速度:一旦你产生一个想法,智能体几乎立刻就能开始实施。结果就是,你不再需要连续几天构思,而是在几个小时内就能做出一个最小可行产品(MVP)并进行迭代修正。如果任务难度没有接近智能体的能力极限,你会把所有时间都花在理解它们产出的结果上;如果任务极具挑战性,那么所有时间则会被用于检查智能体的工作。
- 让智能体“彻夜工作”:在夜间,智能体可以完成约200个人类小时的工作,但这仅限于那些特别适合智能体的任务。因此,研究人员需要有意识地安排项目顺序,确保那些适合智能体的、定义明确的超长任务(例如优化某个指标)被安排在夜间进行。
- 优先级排序与组织管理成为新瓶颈:如果智能体执行想法的速度几乎和你输入提示词的速度一样快,那么只实现“最好”的那个想法就失去了意义。并行实现前三个想法可能效益更高,但这无疑大大增加了保持项目条理性的难度。即便有AI编写的仪表板来辅助人类理解,项目的复杂程度也可能以某种方式飙升,使得项目管理变得异常困难。
工作流
基于这次演练,可以预见未来工作流将呈现以下趋势(当然,预测未来向来是件极其困难的事):
- 声明式工作流:我已经开始通过编写设计文档,然后让智能体去实施来完成大部分工作,这能让我和智能体保持进度同步。在未来一年,这可能会演变成Tom Cunningham在下文提到的“写下你的局部效用函数”工作流。
- 投机性执行:为了防止出现串行瓶颈(见下一节),研究人员可能会采用两种形式的投机性执行:一是启动大量不确定是否真正需要的长期实验;二是预测实验结果和反馈(见Tom Cunningham的“智能体可以缓解瓶颈”部分)。
- “正确性证明”:如果智能体还无法做到百分之百可靠,那么它们生成的最有价值的输出形式,可能就是向人类证明其代码或方案符合规范。这可能包括详尽的测试、为提高可复现性而撰写的说明、记录设计文档中每一行的具体实施位置,甚至在极端情况下包括形式化验证。
瓶颈
如果执行任务变得近乎瞬时,会发生什么?那些原本可以与执行并行进行的、需要串行时间的任务,将无法再被隐藏,转而成为显性的串行瓶颈。项目总时长的大部分,很可能将被人类数据收集、机器学习实验运行,以及来自同行、经理,尤其是外部顾问的反馈等环节所占据。
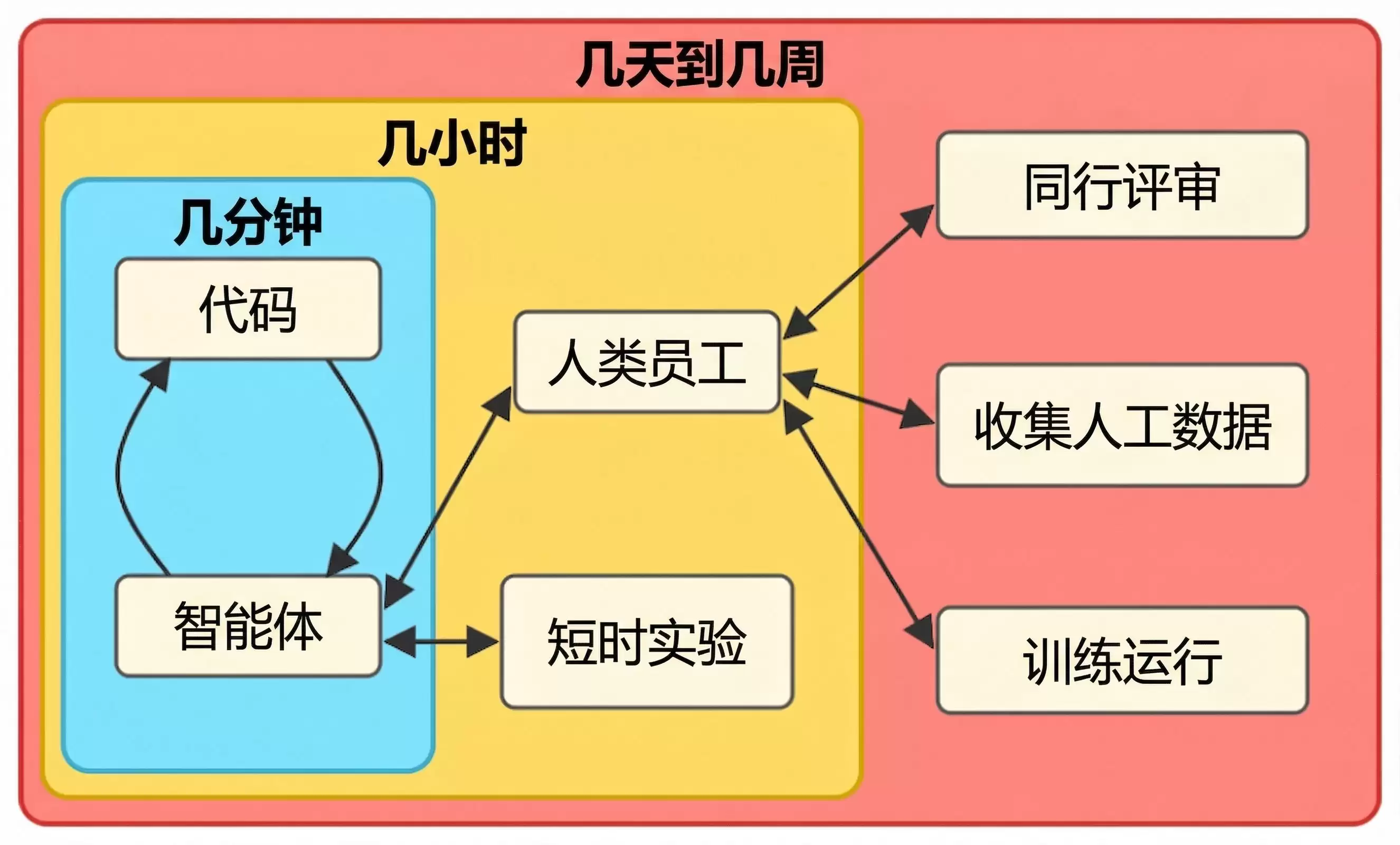
图2:我们可能会面临嵌套的迭代循环,其中执行的“内环”速度远快于“外环”,而项目进度会被那些需要一定串行时间的步骤卡住。对于智能体擅长的任务,这已是现实,并且可能会扩展到几乎所有类型的项目。
可以想象未来一个METR典型项目(例如一篇关于多智能体破坏能力的论文)的时间线将如下表所示(文字描述见脚注[2])。它可能需要六周的自然时间,其中仅包含约8小时的智能体实际工作量(不计算运行评估的时间),这意味着瓶颈耗时与智能体工作量的比例远超100:1。
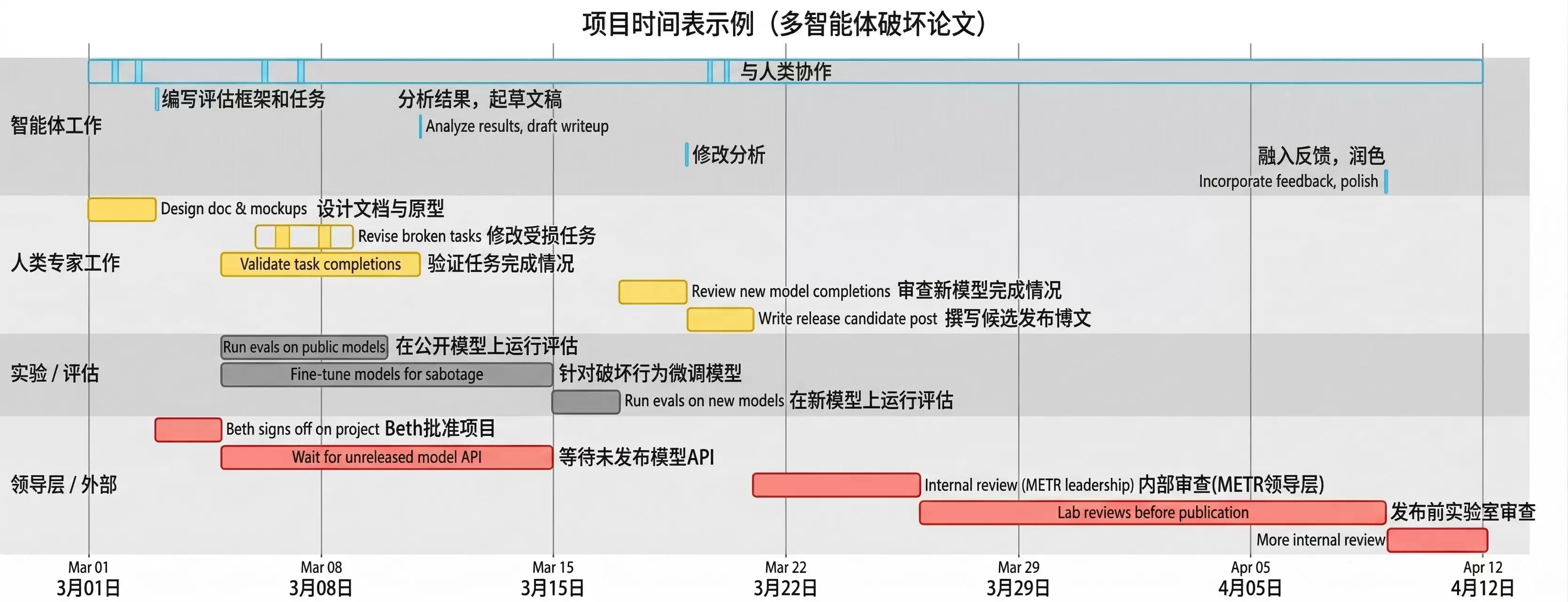
图3:未来的项目可能需要约42个自然日,包含约8小时的智能体工作量(不计评估运行),以及长达1000小时的人类独立贡献者工作、评估执行和评审等串行时间。当然在现实中,人类可能会适应新的限制,因此项目时间线不会完全长成这样。
- 人们可能会并行开展多个项目,由智能体向他们简报每个项目的状态。当项目多到任务切换成本过高时,人类个体贡献者可能会通过额外工作来略微提升每个项目的质量。
- 某些组织将面临巨大的竞争压力,不得不精简评审流程并提高实验的串行速度。
后续迭代
参与者普遍很享受这次演练:两名参与者给出了9/10的评分,一名甚至给出了“11/10”。希望这能成为METR的常规演练——例如每月举办一次,在倾向性团队、能力团队、运营团队乃至全公司范围内轮换进行。
如果再次运行,会尝试一些其他变体:
- 一个时间跨度为50小时的版本,用以指导METR下个季度的实际运营。这需要确保在运行前设定不至于过时。
- 想象我们拥有能充分利用200小时跨度AI基础设施的版本。这需要参与者发挥更多的想象力。
- 一个专门针对AI研发研究的版本。了解当研究工作接近自动化时的瓶颈所在,并粗略估计未来的效率提升,可以为研发时间线和起飞模型提供重要参考。
- 一个能更好模拟研究员在多个并行项目上产出的版本。当前版本允许以小时为单位进行任务切换,但要模拟每隔几分钟切换一次任务,则需要更高的时间分辨率。
Tom Cunningham 的观察
我们花了2小时进行Thomas Kwa设计的这场演练:假定我们拥有极强的AI(200小时时间跨度),但其他一切保持不变——我们的工作仍然是研究2026年2月模型的各种能力,且全球其他所有人仍在使用2026年2月的技术。
我的时间花在:(1)写下我想实现的目标;(2)对产出提供反馈。
我一直在思考,如果仍然由我来做数据分析和撰写报告,将如何利用强大的AI。我构思的工作流是:(1)写下我的总体目标;(2)智能体根据这些目标草拟产出;(3)我对产出提供反馈;(4)带着更新后的目标回到第2步。
目标示例可以是:“给我生成一张优化后的基准测试表,列内容需要与选择第三方风险评估基准相关。我希望能够区分哪些信息是确定的,哪些是推测性的。要让它具有自验证功能,比方说根据独立智能体对每项声明的审计结果显示勾选或叉号。”
其实,我已经在利用智能体做类似的事情,但在这种设定下,我期望的可靠性能再提高几个层次。与其具体指示“我希望这张图表可以点击”,不如提出更高阶的要求:“我希望这份报告具有可读性、全面性、量化性且可验证”。
我们将受困于人类反馈的瓶颈。
但深入思考后,很快遇到了其他瓶颈:(1)启动新的运行任务;(2)获取他人的反馈。
瓶颈可以通过智能体来缓解。
一旦你能用智能体自动化掉大部分工作,感觉你就会在非自动化部分遇到瓶颈。但有趣的是,这些非自动化部分通常是可以预测的,而这恰恰缓解了瓶颈。
想象一下,如果每份报告都自动包含以下内容:
- 智能体对Beth、Hjalmar、Ajeya等同事可能给出评论的最优预测。
- 智能体对(如果你发起)调查结果的最优预测。
- 智能体对基准测试结果的最优预测。
- 智能体对报告在Twitter等平台反响的最优预测。
此外,你还可以点击查看智能体做出每项预测的原因。感觉这些功能会显著缓解瓶颈,我可以不断迭代报告,直到从外界接收到的信息(人类反馈、新数据、调查结果)具有最大的信息量时,再正式发送进行评审。
我感觉自己像个首席研究员(PI)。
这让我想到了两个类比:研究实验室的首席研究员(PI),或者麦肯锡的合伙人。
两者都把大量时间花在审查他人的产出、提供战略性建议,以及等待下一轮评审上。
这种设定非常高效,但也存在病理性的弊端。值得注意的是,许多PI并没有时间去深入理解详细的统计或概念论证,进而导致博士生和博士后也缺乏动力去仔细检查这些论证,最终整个实验室可能会产出一些流于表面的论文。
然而,对于智能体而言,这种担忧似乎减轻了,因为你总能进行低成本的验证。
只有资深人士能生存。
在这个AI能力极强的世界里,感觉在该领域经验较少的初级人员,相对于经验丰富的资深人员,将很难做出独特的贡献。
寻找正确的 DAG(有向无环图)结构是一项精细活。
从概念上讲,智能体应该构建一个图,或者说一个从输入到输出的函数。输出是最终报告,输入是(i)我的偏好,(ii)数据源,(iii)外部参考资料;在它们之间是所有处理和集成的阶段。然而,弄清楚DAG的实际细节是很困难的:
- 对于那些随意的惯例(比方说使用哪个库、什么字体、什么布局),决策是如何做出的?通常有很多同样好的选择,但保证整个项目中决策的一致性至关重要。
- 当我对产出提供反馈时,智能体应该如何存储这些反馈以供将来使用,并且如何保持正确的泛化水平,避免过度拟合或欠拟合?
- 如果我的反馈本身是错误的(例如基于误解),该如何将其整合进系统中?
感觉在寻找正确的图结构以使工作最高效方面,还有巨大的探索和进步空间。
译者:boxi。




