一、早期融合范式
我们先从数据处理的“入口”聊起。早期融合,顾名思义,就是在信息进入模型核心之前,先想办法让不同模态的数据“对上话”。这里主要有两种打法,各具特色。
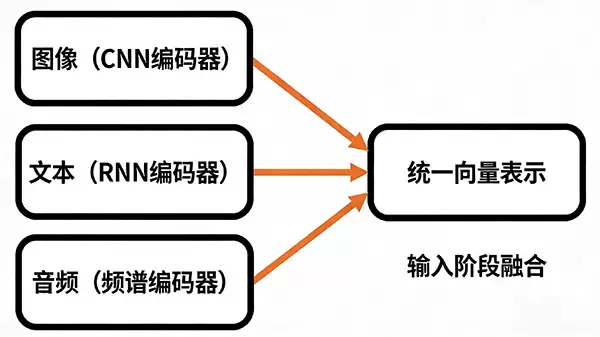
Type C:模态特定的编码器融合
这种思路很直观:不同的菜,用不同的锅来预处理。具体来说,它会为图像、文本、音频等不同模态分别配备专门的编码器——比如用CNN处理图像,用RNN或Transformer处理文本。这些编码器就像翻译官,先把各自领域的数据转换成一种统一的“向量语言”,然后再一并送入下游模型进行决策。
这么做的优势很明显:架构清晰,扩展性强。每种模态的特征提取可以独立、并行进行,哪天想新增一种传感器数据(比如红外或点云),加一个对应的编码器模块就行,整体框架几乎不用大动。对于追求部署效率和系统简洁性的场景,这是个稳妥的起点。
不过,它的局限也由此而生。这种“先翻译,后开会”的模式,可能导致模态间的细粒度交互在早期就丢失了。毕竟,各个编码器是各自为政训练的,它们产出的特征向量,其语义空间未必对齐得好。这就像几位翻译各自翻了一段话,虽然都成了中文,但用词和语境可能微妙地不同,放到一起分析时,总会有些隔阂,最终可能影响模型理解的深度和精度。
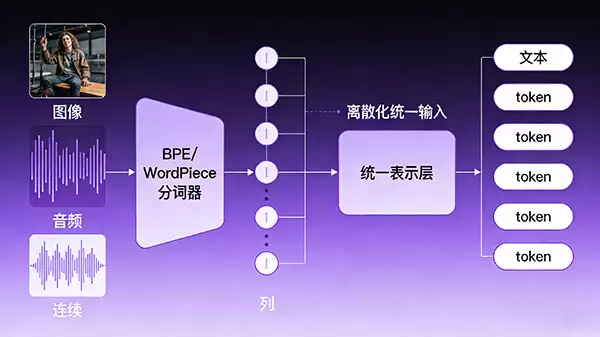
Type D:分词器统一表示融合
如果说Type C是“多语种翻译后开会”,那么Type D的理念就更激进一些:为何不创造一种“世界语”,让所有模态的数据从一开始就用同一种“方言”说话呢?这就是分词器统一表示融合的核心。
它的做法是,引入类似BPE、WordPiece的分词器,将图像块、音频帧这些连续信号,也离散化成一个个的token序列。如此一来,无论原本是图片、声音还是文字,在模型眼里都变成了一串类似的“词汇”,输入接口被极大简化。
这个方向的潜力巨大。它显著减少了模态转换间的信息损失,为实现真正的“任意模态到任意模态”(any-to-any)的统一大模型奠定了基石。想象一下,同一个模型骨架,既能看图说话,也能听音辨物,架构上的优雅和效率提升是显而易见的。
当然,挑战也同样具体。关键就在于如何设计出高效且精准的分词与量化策略。这就像在为图像和声音设计“字母表”,字母太少(量化粗糙)会丢失细节,字母太多(词汇表庞大)又会拖垮计算效率。如何取得最佳平衡,是当前研究的关键攻坚点。
二、内部融合范式
与早期融合不同,内部融合不急于在入口处统一数据,而是让原始或初步处理后的多模态数据直接进入模型“黑箱”,在深层计算过程中动态地、精细地完成交互。这更贴近人类大脑处理多感官信息的方式。
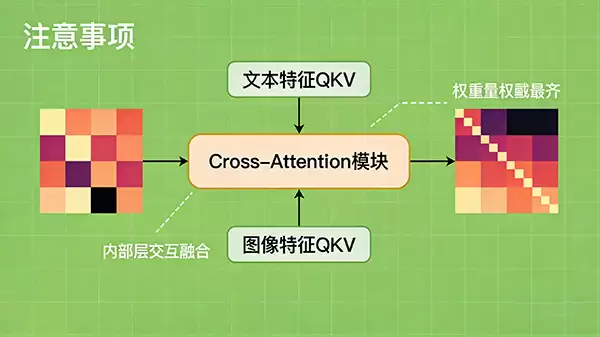
Type A:标准交叉注意力机制融合
这是目前内部融合的主流技术,尤其随着Transformer架构的普及而大放异彩。它的核心武器是标准的交叉注意力(Cross-Attention)机制。
简单来说,它让一种模态的特征(例如文本的Query)去“询问”另一种模态的特征(例如图像的Key和Value),从而在模型内部层层递进地实现特征对齐与信息萃取。这个过程是动态且数据驱动的,模型能自行学习到“图像中的这块区域对应文本里的哪个词”这类精细关联。
优势正在于此:它能实现非常细腻的、上下文相关的融合,对于需要深度理解模态间关系的任务(如图文问答、视频描述)效果突出。但天下没有免费的午餐,这种强大的能力需要“喂养”大量高质量、对齐好的多模态训练数据。同时,注意力机制带来的计算复杂度,也对算力提出了更高要求。
Type B:自定义融合层深度融合
如果说Type A使用的是“标准武器”,那么Type B就是为特定任务定制“特种装备”。它不满足于现成的交叉注意力,而是在模型内部设计专用的、结构更复杂的融合层,例如定制化的多模态Transformer块或更复杂的多路注意力网络。
这种方法的目的是进行更深层次、更显式的高阶交互建模。比如,除了特征对齐,它可能还想同时建模模态间的时序依赖、因果推理,甚至对抗性关系。通过精心设计的融合结构,模型有望捕捉到那些隐藏在简单关联背后的复杂模式。
显然,这是一条更具探索性和挑战性的路。自定义融合层的设计没有银弹,需要大量的架构实验、细致的调参以及深厚的领域知识来验证和优化。而且,它对原生模型架构的侵入性较强,往往会增加模型的复杂度和训练难度。但一旦在某类特定任务上取得突破,其性能天花板也可能更高。

聊到这里,这四种多模态融合范式的面貌就比较清晰了。它们从“早”到“晚”,从“统一”到“交互”,构成了一个丰富的技术光谱。
那么,到底该选哪一种?答案永远是:看情况。早期融合(C,D)在效率、扩展性上常有优势,适合对实时性要求高或模态数量易变的场景。而内部融合(A,B)则在需要深度理解与精细对齐的任务上表现更佳,但代价是更高的数据和算力成本。
实际应用中,没有绝对的优劣,只有是否契合。关键在于仔细权衡你的具体任务目标、数据特点以及所能投入的资源,从中做出最合适的选择。




