告别向量盲搜:PageIndex重新定义无向量推理式RAG范式
深入解析PageIndex:新一代无向量推理式RAG如何革新长文档问答
随着大模型上下文窗口的持续扩大,一个根本性问题——“上下文稀释”效应——依然存在。与此同时,向量检索增强生成(RAG)虽已成为标准方案,但其底层缺陷,即“语义相似不等于真实相关”的矛盾,始终未被根除。尤其在处理财报、法律合同、技术白皮书等结构严谨的长文档时,传统向量RAG的局限性暴露无遗。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
延续对BookRAG的探讨,本文将聚焦另一个极具前瞻性的技术框架:PageIndex。这是一个彻底摒弃向量数据库、完全依靠大模型推理驱动的新一代RAG方案。其核心理念在于,不依赖静态的语义嵌入向量,而是引导大语言模型模拟人类的阅读逻辑:先理解目录结构,再导航至相关章节,最后通过推理定位答案。这实现了从“文本匹配”到“文档理解”的本质跨越,为复杂长文档的智能问答提供了一种全新的、无需向量的解决方案。

项目官方文档地址:https://docs.pageindex.ai/
01、研究背景与问题根源
RAG技术的初衷是明确的:突破大模型上下文长度的限制,通过检索外部知识库来提升回答的准确性与事实性。然而,传统向量RAG的底层工作流程,从根本上决定了它在处理专业长文档时的效能瓶颈。
传统向量RAG的流程高度标准化:将文档硬性切分为固定长度的文本块;将每个文本块转换为向量,存入外部向量数据库;用户提问时,将问题向量化并进行相似度匹配;召回最相似的Top-K个文本块;最后将这些块拼接后输入大模型以生成答案。
这套方案在处理短文本和通用知识时简单有效。但面对长篇、结构化、高专业度的文档时,其五大固有缺陷便无法回避:
查询意图与知识空间错配:向量检索基于“语义相似”,但用户查询表达的是“问题意图”。两者之间常常存在鸿沟,语义相近的段落未必是逻辑上正确的答案。
语义相似度不等于真实相关性:专业文档中常存在大量语义近似的描述,但核心答案往往只存在于特定章节。向量检索无法有效区分这种关键性的逻辑相关度。
硬分块破坏语义连贯性:固定长度的文本切割如同一把钝刀,极易切断句子、段落乃至章节间的逻辑联系,导致信息碎片化,上下文严重丢失。
无法有效整合多轮对话历史:每次检索都是独立进行的,检索器无法感知到对话的上下文连贯性,难以处理复杂的连续追问。
无法解析文档内部交叉引用:对于文档中常见的“参见附录A”、“如表5-1所示”这类引用,向量检索完全无能为力,因为引用文本与目标内容之间缺乏直接的语义相似性。
正是这些瓶颈,促使Claude Code等先进系统转向推理式检索。而PageIndex,正是将这一前沿思想系统化、并落地到通用文档处理领域的标志性框架。
02、核心要点速览
如果您时间有限,可先掌握以下核心亮点:
彻底抛弃向量数据库:无需文本切块、不生成向量、不依赖任何外部向量库,实现真正的“无向量RAG”。
构建LLM友好的层级目录树:将整个文档转换为一个JSON格式的层级索引树,完美保留原始章节结构,并直接置于大模型的上下文窗口内。
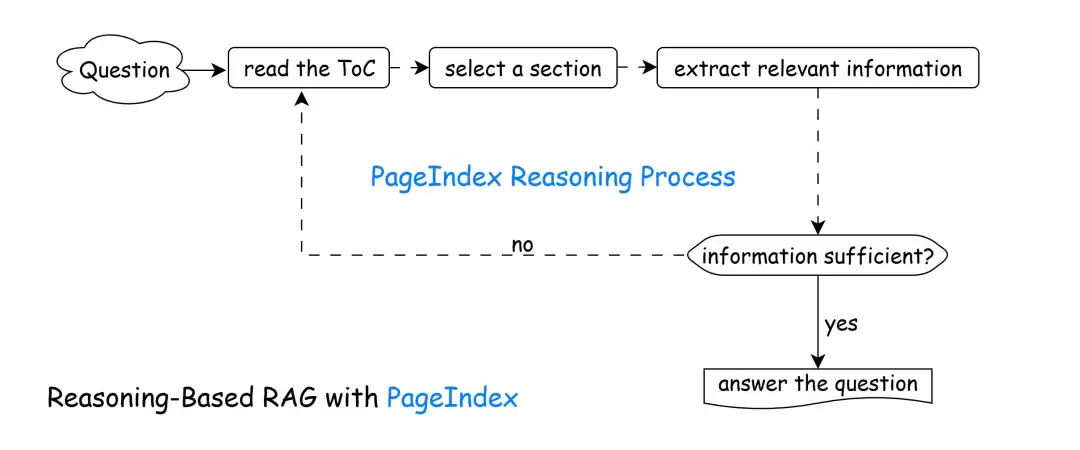
模拟人类推理式检索:引导大模型模仿人类的阅读逻辑:浏览目录→选择潜在相关章节→提取内容→判断信息是否充分→若不足则循环补充→最终合成答案。整个过程依赖推理导航,而非简单的相似度匹配。
原生解决五大核心痛点:该机制天生支持对话上下文、能处理交叉引用、保持语义完整性,并能精准对齐用户的查询意图。
03、核心问题定义
那么,PageIndex旨在解决何种具体问题?它面向的是长篇幅、强结构化复杂文档的精准问答任务。
具体而言,给定一份远超大模型上下文窗口的专业长文档(例如一份数百页的上市公司年报或产品技术手册),在不使用向量数据库、也不进行机械文本分块的前提下,如何让大模型通过主动推理来导航文档结构,精准定位相关信息,并生成有据可依的可靠答案?
其设计哲学非常清晰:检索不应是一种静态的相似度匹配操作,而应是一种动态的推理式导航过程——让大模型主动思考“答案最可能位于文档的哪个部分”,而非被动接收“这些文本块与你的问题在字面上有些相似”。
04、PageIndex核心方法解析
PageIndex的核心创新可概括为“上下文内层级树索引”结合“迭代式推理检索”。全程无需向量,纯靠推理,完美复现了人类查阅长文档的思维过程。
核心底座:上下文内层级树索引
PageIndex的第一步,是将目标文档构建成一个JSON格式的层级目录树。关键在于,这个索引并非存储于外部数据库,而是直接放置在大模型的上下文窗口之中,成为一个可被实时查阅和推理的“智能导航地图”。
1. 索引树结构设计
树中的每个节点对应一个逻辑章节(如章、节、段落或页面),包含以下核心字段:
node_id:节点的唯一标识符,用于精准映射回原始内容。
title:该章节的标题。
start_index / end_index:该章节内容在原文中的起止字符位置。
summary:该章节的概要总结,供大模型快速评估相关性。
sub_nodes:子节点列表,以此递归形成完整的树状结构。
{
"node_id": "0006",
"title": "Financial Stability",
"start_index": 21,
"end_index": 22,
"summary": "The Federal Reserve ...",
"sub_nodes": [
{
"node_id": "0007",
"title": "Monitoring Financial Vulnerabilities",
"start_index": 22,
"end_index": 28,
"summary": "The Federal Reserve's monitoring ..."
},
{
"node_id": "0008",
"title": "Domestic and International Cooperation and Coordination",
"start_index": 28,
"end_index": 31,
"summary": "In 2024, the Federal Reserve collaborated ..."
}
]
}
...2. 索引的核心优势
保留文档原生结构:绝不破坏原有的章节、段落逻辑,索引树与文档原始层级完全对应。
上下文内驻留:索引存在于大模型的推理上下文中,模型可以像查阅手册一样实时进行导航与逻辑推理。
精准的内容映射:每个node_id都直接关联着原始文本、表格或图片等内容,实现零误差的精准定位。
核心流程:迭代式推理检索
拥有这张“智能地图”后,检索过程便完全模拟了人类翻阅长文档的行为,通过以下五步进行迭代:
第一步,概览目录结构:大模型首先通览整个层级索引树,建立对文档整体框架和脉络的理解。
第二步,推理选择章节:基于用户的查询意图,进行逻辑推理,定位最可能包含答案的章节节点。
第三步,提取章节内容:通过选定的node_id,获取该章节的完整原始内容,并提取关键信息。
第四步,信息充分性校验:判断当前收集到的信息是否足以回答问题。若足够,则进入最终步骤;若不足,则返回第一步,继续导航至其他相关章节进行补充。
第五步,合成最终答案:整合所有迭代过程中收集到的、经过校验的信息,生成完整、准确且有依据的最终答案。
核心能力:攻克传统RAG五大瓶颈
正是这套机制,使得PageIndex能够原生地解决传统向量RAG的固有难题:
精准匹配查询意图:通过推理定位章节,而非机械的语义匹配,从根本上弥合了用户意图与内容位置之间的差距。
聚焦真实逻辑相关性:基于文档结构和上下文进行推理,只获取逻辑上真正相关的内容,自动过滤语义相似但无关的噪声信息。
保持语义与结构完整:按完整的章节或页面单位获取内容,并可动态补充相邻节点,彻底避免了硬分块导致的信息碎片化问题。
原生支持多轮对话:整个检索过程能够感知并利用对话历史,基于上文语境来优化和修正后续的检索方向。
智能处理内部交叉引用:凭借层级树的导航能力,可以自动解析并跟随“详见附录”等交叉引用,直接跳转到目标内容。
05、传统向量RAG与PageIndex推理式RAG对比
两者的对比,本质上是“检索即匹配”与“检索即推理”两种范式的差异。我们可以从以下几个维度进行清晰对比:
检索逻辑:传统方法是“被动搜索相似文本”,依赖向量相似度匹配;PageIndex是“主动寻找答案位置”,依靠大模型推理导航。
索引形式:传统方法是“碎片化的向量集合”,存储于外部数据库;PageIndex是“结构化的目录树”,驻留于模型上下文内。
信息完整性:传统方法因硬分块而“必然造成语义割裂”;PageIndex按结构获取,实现了“动态的语义完整”。
处理交叉引用:传统方法对此“完全无能为力”;PageIndex则可以“智能跟随与解析”。
最佳适用场景:传统方法更擅长处理“短文本、弱结构”的通用知识;PageIndex则专为攻克“长文档、强结构”的专业场景而设计。
06、总结与展望
PageIndex所做的,并非对传统向量RAG进行局部优化,而是从底层逻辑上彻底重构了RAG的检索范式,完全跳出了“文本相似度匹配”这一传统框架。
传统向量RAG的核心是被动搜索相似度——通过暴力切块、向量嵌入和静态匹配,其焦点始终停留在文本的表层语义关联上。而PageIndex所代表的推理式RAG,其核心是主动寻找位置——通过构建文档结构地图、进行推理导航和动态内容获取,直击文档的内在逻辑与真实相关性。
它以一套极其简洁的无向量架构,破解了传统向量RAG难以逾越的底层缺陷;凭借上下文内的层级目录索引,赋予了大模型真正理解文档结构的能力;再通过迭代式推理检索,完美还原了人类在查阅长文档时那种高效、精准的信息查找逻辑。
当然,我们也需客观看待其适用边界。PageIndex的目录树构建需要大模型通读全文,其计算开销与Token成本相对较高。此外,它与BookRAG类似,主要适用于那些具备清晰目录层级结构的文档。对于完全没有排版、缺乏章节划分的非结构化文本,其核心优势的发挥会受到限制。
从BookRAG的结构感知,到PageIndex的无向量推理,RAG技术领域正在加速告别“碎片化文本匹配”的初级阶段,大步迈向一个注重结构理解、依赖推理驱动、追求意图精准对齐的全新时代。PageIndex不仅为长文档专业场景提供了一种极简而强大的无向量RAG解决方案,也为结构感知型RAG的实际落地,指明了一条更贴近人类认知习惯的技术演进路径。
相关攻略

在RAG架构的演进中,一个核心趋势正变得愈发清晰:未来的竞争力,不在于系统能塞进多长的上下文,而在于它有多强的信息筛选智慧。将上下文窗口视为一种珍贵且有限的战略资源,而非可以随意堆砌的廉价空间,这已成为构建成熟AI系统必须坚守的工程哲学。 回顾大模型工程化的拓荒时期,我们曾深信一个朴素的理念:给模型

多模态RAG的深度重构:从“暴力提取”到“两次审视”的工程跃迁 在当前的LLM技术栈中,多模态能力正经历一场静默但深刻的变革:它正从一个可选的“插件”,演变为系统的“原生核心”。早期的处理思路,往往将图片视为一种单向的转换工具——简单地将像素转化为文本描述。然而,在复杂的业务场景下,这种粗暴的“降维

引言 在聊今天的技术主角之前,先说个题外话。备受关注的《2025年博客之星年度评选获奖名单》近期揭晓了,我们“小马过河R博客”团队很荣幸跻身年度百强之列。这无疑是个令人鼓舞的开始。 好,言归正传。如果你近期关注AI领域,想必对一个名字不会陌生——OpenClaw。这个开源项目近期可谓风头正劲,刷爆了

深入解析PageIndex:新一代无向量推理式RAG如何革新长文档问答 随着大模型上下文窗口的持续扩大,一个根本性问题——“上下文稀释”效应——依然存在。与此同时,向量检索增强生成(RAG)虽已成为标准方案,但其底层缺陷,即“语义相似不等于真实相关”的矛盾,始终未被根除。尤其在处理财报、法律合同、技

从“流水线”到“认知闭环”:Agentic RAG如何终结大模型的“幻觉死循环” 如果在2024年,大家谈论RAG(检索增强生成)是为了解决大模型的幻觉问题;那么到了今天,如果您的系统还固守着“查询-向量化-检索-生成”这套传统思路,那它在真实的业务场景中,恐怕早已步履维艰了。 大量的生产环境测试揭
热门专题







热门推荐

购买USDT是进入加密货币世界的重要一步。本文以OKX平台为例,详细介绍了从注册、身份认证到完成购买的完整流程,涵盖了快捷买币、C2C交易等不同方式的操作要点与注意事项,旨在帮助新手安全、顺利地迈出第一步。

Windows任务管理器,终于跟上了AI时代 几十年来,Windows任务管理器堪称操作系统的“老伙计”,忠实记录着每一个进程的脉搏。但眼下,这位老将遇到了新挑战:它必须得追上一波十年前根本无法想象的技术浪潮。最典型的例子是什么?就是你新买的电脑里,很可能已经多了个叫“神经网络处理单元”(NPU)的

苹果前沿 Web 技术试验田:Safari 预览版浏览器迎 10 周年,版本累计更迭 240 次 十年,对于一个快速迭代的科技产品来说,足以称得上一个里程碑。就在最近,苹果专门为开发者打造的浏览器测试工具——Safari 技术预览版,悄然迎来了它的十周岁生日。 故事要回溯到2016年3月30日。当时

C4D怎么使用TFD插件制作烟雾效果呢? 说起在Cinema 4D里模拟烟雾效果,TFD(TurbulenceFD)插件绝对是很多高手的首选工具。不过,对于刚接触它的朋友来说,那一堆参数和设置可能有点让人无从下手。别担心,下面这份详细的流程图解式教程,将一步步带你从零开始,制作出细节丰富、动态真实的

C4D必备技能:手把手教你打造三维线状圆环图纹 想要在Cinema 4D中创建出那种充满科技感和结构美的三维线状圆环图纹吗?这个效果在动态图形和视觉包装中应用广泛,制作过程其实并不复杂。掌握了核心的操作逻辑,几步就能实现,下面就为你拆解整个操作流程。 C4D怎么创建三维立体的线状圆环图纹效果 首先,