1月15日,科技媒体AppleInsider发布报道称,苹果公司近日公布了一项重要研究成果,详细介绍了名为DeepMMSearch-R1的人工智能模型。该模型重点优化了AI在复杂视觉场景下的搜索逻辑,通过“裁剪”机制有效缓解了AI的幻觉问题。
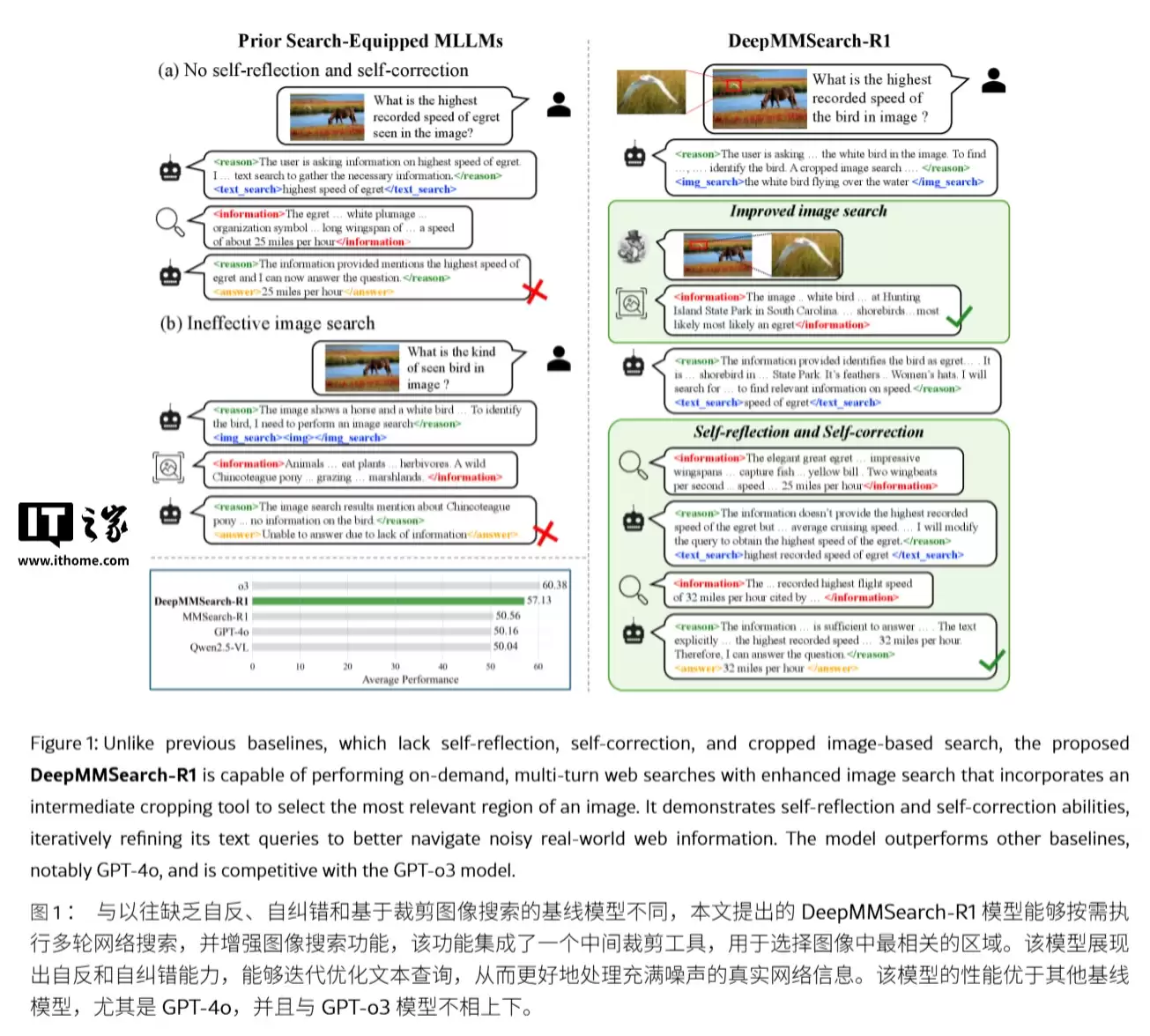
针对现有AI模型在处理复杂视觉信息时,时常出现的“答非所问”或“漏看”问题,苹果推出了DeepMMSearch-R1模型。传统模型在面对“图中左上角那只鸟的最高时速是多少”这类复合问题时,往往因无法聚焦局部细节而给出错误的平均数据。

DeepMMSearch-R1引入了一种独特的“视觉定位工具”,能够主动裁剪图片以剔除干扰信息。它首先精准识别微小目标,再进行针对性的网络搜索验证,从而确保答案的事实准确性。
为确保模型仅在必要时才启用裁剪功能以节省算力,研究人员采用了“监督微调+在线强化学习”的组合训练法。监督微调负责教会模型“不乱剪”,而强化学习则提升了工具调用的效率。

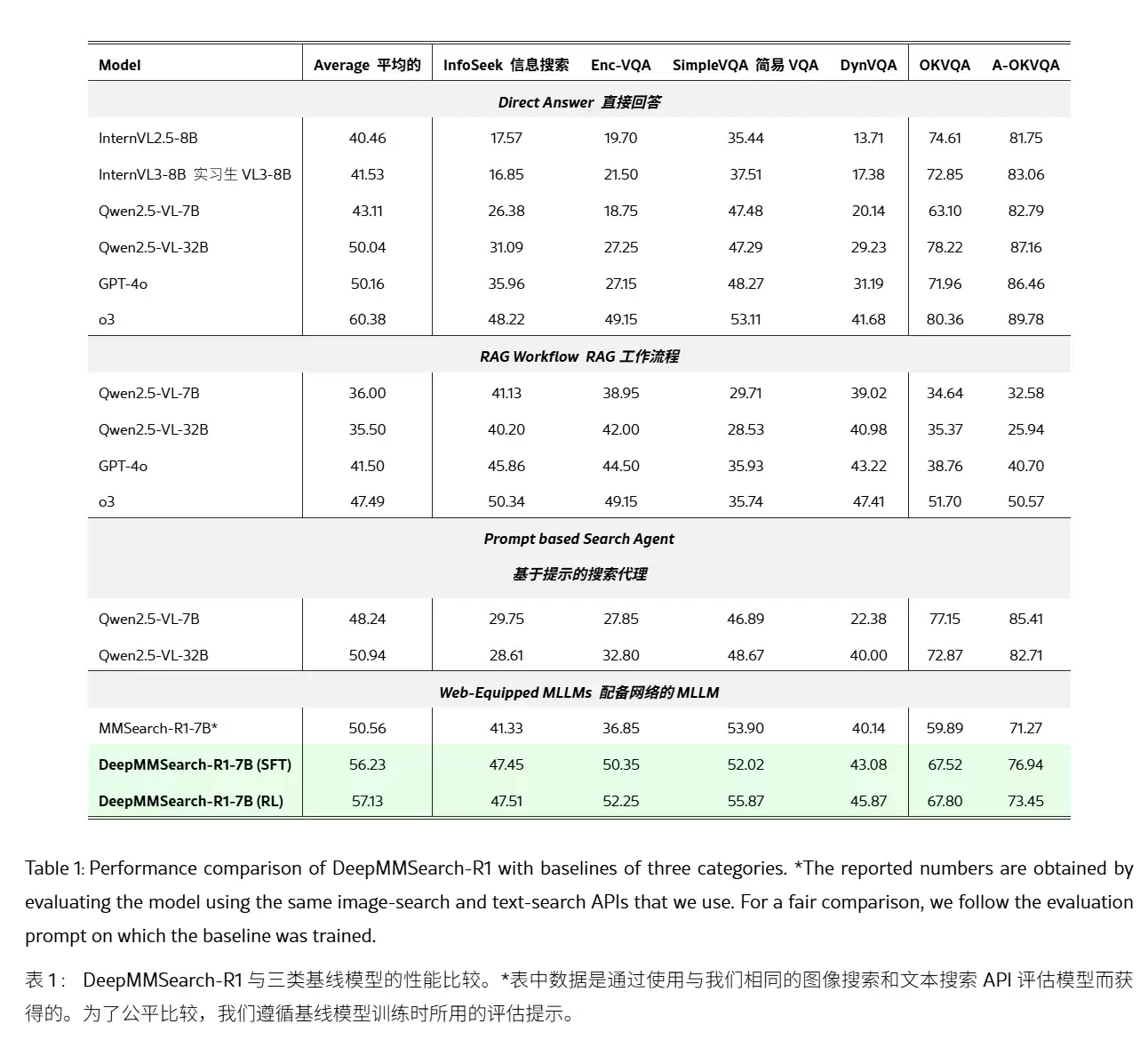
测试数据显示,该模型在处理需精准图文对应的问题上,表现显著优于目前的RAG工作流及基于提示词的搜索智能体,成功解决了AI在常识性事实检索中的“偷懒”现象。
附上参考文献
DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search




