1月15日消息,科技媒体Appleinsider今日发布报道称,苹果公司发表了一项重磅研究成果,详细介绍了名为“Manzano”的多模态模型。该模型创新性地融合了“视觉理解”与“文本生成图像”两大核心功能。
这一模型最显著的突破在于其“双向能力”:它不仅能够像人类一样精准解读图像中的内容与语义,还能根据文本描述生成高质量的视觉图像。
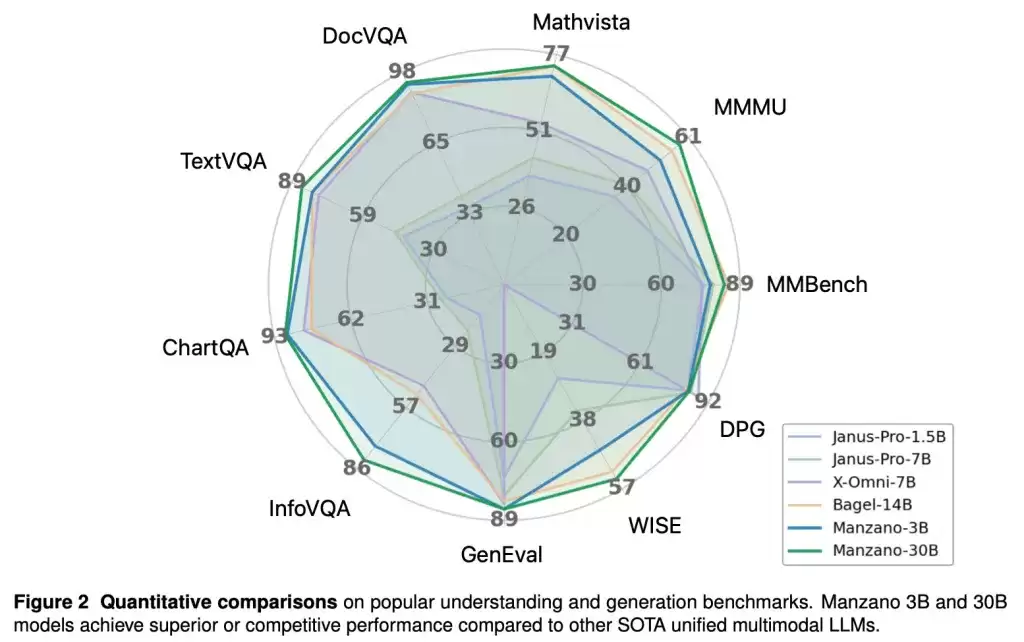
在此之前,行业内仅有少数模型能够同时兼顾这两项任务,且往往需要在生成质量与理解深度之间做出妥协。研究人员指出,其核心矛盾在于处理“视觉分词”的方式不同。
简单来说,AI在进行“图像理解”时,倾向于处理连续的数据流,类似于观看视频;而在进行“图像生成”时,则更依赖离散的数据块,类似于拼接拼图。传统模型强行让同一个“大脑”处理这两种截然不同的信号,往往会导致严重的任务冲突,结果要么是“看得懂但画不出”,要么是“画得好但理解偏”。
Manzano为了解决这一难题,引入了一种创新的三段式架构:
首先,它使用“混合视觉分词器”同时生成连续和离散的视觉表示;
接着,利用大语言模型预测图像的语义内容;
最后,将这些预测结果交给“扩散解码器”进行像素级渲染。
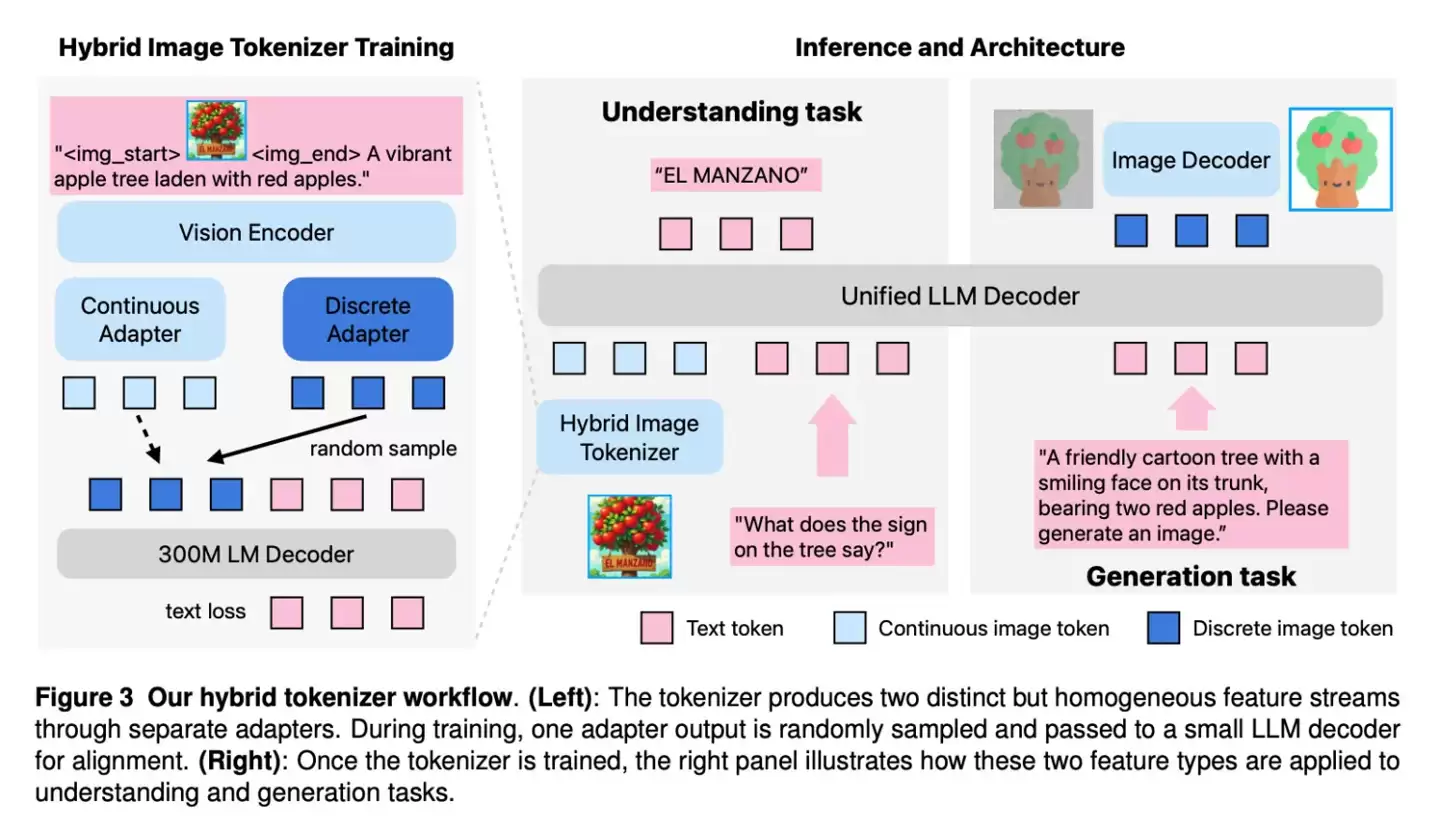
这种设计让Manzano既保留了强大的语义理解能力,又具备了精细的图像生成能力,甚至能够处理深度估计、风格迁移和图像修复等复杂任务。
测试数据显示,Manzano在处理反直觉、违背物理常识的复杂指令时表现惊人。例如,当要求生成“一只鸟在大象下方飞翔”的画面时,Manzano的逻辑准确性与OpenAI的GPT-4o以及谷歌的Nano Banana模型旗鼓相当。



研究团队测试了从30亿到300亿参数的不同版本,证实了该架构在模型规模扩大时依然能保持高效的性能提升。

尽管Manzano目前仍处于研究阶段,尚未直接应用于iPhone或Mac设备,但这表明苹果正在构建更强大的底层AI能力。
该媒体认为,这项技术极有可能会被整合进未来的“图乐园 Image Playground”功能中,为用户带来更智能的修图体验和更具想象力的画面生成能力,进一步巩固苹果在端侧AI领域的竞争力。
附上参考地址
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer




