DS之slow motion利用PaddleGAN的DAIN模型实现视频慢动作
本文介绍了基于Deepshop工具箱,利用PaddleGAN的DAIN模型实现视频慢动作效果的方法。先说明DAIN模型原理,它通过估计光流和深度图生成中间帧。接着给出安装PaddleGAN、创建慢动作类的步骤,最后演示模型使用,可指定慢动作速率和处理帧范围,输出慢动作视频。

先看效果 DS-slow motion
左边为原视频,右边为对第一个跃起动作进行slow motion的视频(只对视频中精彩时刻做slow motion,感觉能看出效果)
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
PS:视频来自B站
HTML('')
1 背景介绍
1.1 使用说明:
若只是想把视频实现慢动作slow motion效果,直接跳到“3视频慢动作” ,根据说明设置参数即可。若要了解过程,可继续阅读。
1.2 DS -- Deepshop:
1.在图像编辑中有大名鼎鼎的photoshop作为图像处理工具,那在这里我打算也弄个Deepshop作为图像处理的深度工具箱,开箱即用。
2.后续也会陆续整理其他工具,这次整理了视频慢动作工具的
3.至2024年6月,这个模型基于msgnet迁移训练,效果离以假乱真还有点距离,效果还可以继续优化,stylepro_artistic那个迁移可能效果更好,可惜暂时没找到那个可以迁移的,有时间看从头训练一个。
1.3 慢动作slow motion
1.随着手机摄像头帧率动不动就120fps,60fps,现在拍慢动作也很简单了。但若原视频只有25fps,30fps的要变成慢动作视频还是可以用DL的方法
2.就是利用ppgan(PaddleGAN中的DAIN模型,原本就是插帧的DL算法,在这里用DAIN插了帧后,保持原视频帧率不增加帧率,只增加了总帧数。相当于增加视频长度,但视频内容的真实时间长度是不变的,所以相当于实现慢动作,处理的那段视频变成慢动作了。
3.这里只是小小修改,方便进行使用而已,技术源自DAIN与PaddlePaddle
2 DAIN介绍
2.1 深度学习插帧模型
当前有不少插帧的深度学习模型,英伟达的Super slomo,上海交大的DAIN。都是为视频插帧,使视频看起来更丝滑。在这里我们把插的帧,不用来提升帧率,而是延长整个视频长度,形成慢动作slow motion效果。

2.2 深度感知视频帧插值 DAIN
DAIN的全称是Depth-Aware Video Frame Interpolation,2019年的CVPR.最新的github https://github.com/baowenbo/DAIN
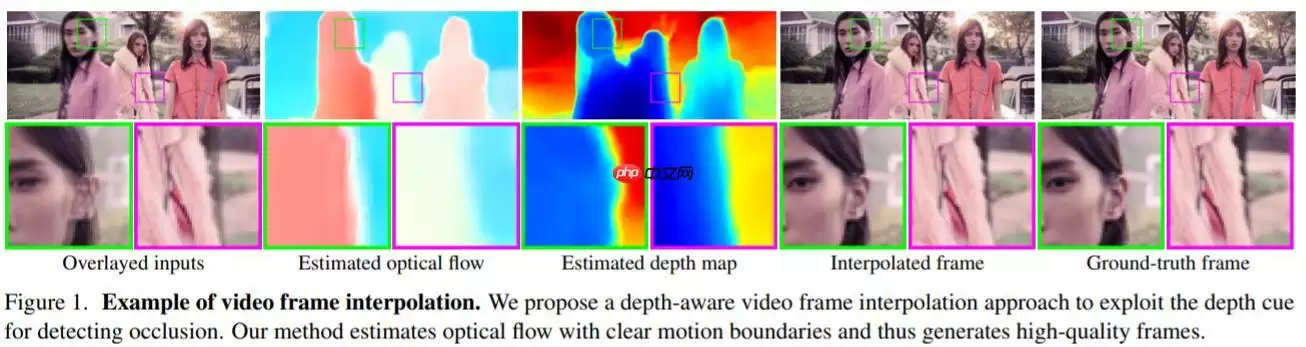
—— 给定两个时刻的输入帧,先估计光流和深度图,然后使用建议的深度感知流投影层生成中间流。然后,模型基于光流和局部插值内核对输入帧、深度图和上下文特征进行扭曲,合成输出帧。这种模型紧凑、高效且完全可微分。
参考自 https://zhuanlan.zhihu.com/p/149395616
—— 并且,项目并没有预训练的分类网络,而是自己训练了一个内容输出网络来获取高维特征,来给视频插值。
2.3 上手插帧理
2.3.1用PaddleGAN的DAIN插帧:
直接调用封装好的类:
In [ ]## 需要插帧的设置TruebaseUse=False## 指定要插帧的视频文件path='/home/aistudio/huaxue.mp4'#if baseUse: !pip install -q ppgan import paddle from ppgan.apps import DAINPredictor ##需注意用静态图 paddle.enable_static() dain=DAINPredictor(output='output', weight_path=None, time_step=0.5, use_gpu=True, remove_duplicates=False) dain.run(path)登录后复制
2.3.2 用别的整合的DAIN 插帧
若觉得改一行代码也累,想直接用,可找已有的网页https://distinctai.net/fps ,限制就是:免费试用最大不超过10M,支持MP4、avi、rmvb等多种格式,三次免费
3 视频慢动作
3.1 安装PaddleGAN
我用最懒方法直接pip安装,有需要的也可以git后安装
In [ ]!pip install -q ppgan登录后复制
3.2 创建慢动作类
1.在github上追踪DAIN的代码,在 ppgan.apps下面的dain类拷贝出来,进行修改(因改动不少就没有继承DAIN了)
2.主要修改部分是frame合成视频时,及 combine_frames方法。主要改图片的名字,然后放到output/DAIN/frames-combined中
PS:ppgan这里用的是ffmpeg生成视频,指定图片文件夹所在路径来生成。这里注意图片文件名要求从000.webp(0开始)一直连续顺序递增(0001.webp,0002.webp等)!!这里坑了不少时间
In [7]import osimport cv2import globimport shutilimport numpy as npfrom tqdm import tqdmfrom imageio import imread, imsaveimport paddlefrom ppgan.utils.download import get_path_from_urlfrom ppgan.utils.video import video2frames, frames2videofrom ppgan.apps.base_predictor import BasePredictorpaddle.enable_static()DAIN_WEIGHT_URL = 'https://paddlegan.bj.bcebos.com/applications/DAIN_weight.tar'class DAINSlowMotion(BasePredictor): def __init__(self, output='output', weight_path=None, use_gpu=True, remove_duplicates=False): self.output_path = os.path.join(output, 'DAIN') if weight_path is None: weight_path = get_path_from_url(DAIN_WEIGHT_URL) self.weight_path = weight_path #self.time_step = time_step self.key_frame_thread = 0 self.remove_duplicates = remove_duplicates self.build_inference_model() def run(self, video_path,slow_rate=0.5,frameIndex=[],interpolateIndex=[]): self.time_step=slow_rate if len(frameIndex)!=2: self.frame_start=0 self.frame_end=-1 else: self.frame_start=frameIndex[0] self.frame_end=frameIndex[1] if len(interpolateIndex)!=2: self.interpolate_start=0 self.interpolate_end=-1 else: self.interpolate_start=interpolateIndex[0] self.interpolate_end=interpolateIndex[1] frame_path_input = os.path.join(self.output_path, 'frames-input') frame_path_interpolated = os.path.join(self.output_path, 'frames-interpolated') frame_path_combined = os.path.join(self.output_path, 'frames-combined') video_path_output = os.path.join(self.output_path, 'videos-output') if not os.path.exists(self.output_path): os.makedirs(self.output_path) if not os.path.exists(frame_path_input): os.makedirs(frame_path_input) if not os.path.exists(frame_path_interpolated): os.makedirs(frame_path_interpolated) if not os.path.exists(frame_path_combined): os.makedirs(frame_path_combined) if not os.path.exists(video_path_output): os.makedirs(video_path_output) timestep = self.time_step num_frames = int(1.0 / timestep) - 1 cap = cv2.VideoCapture(video_path) fps = cap.get(cv2.CAP_PROP_FPS) print("Old fps (frame rate): ", fps) times_interp = int(1.0 / timestep) r2 = str(int(fps) * times_interp) print("New fps (frame rate): ", fps) out_path = video2frames(video_path, frame_path_input) vidname = os.path.basename(video_path).split('.')[0] frames = sorted(glob.glob(os.path.join(out_path, '*.webp'))) frames=frames[self.frame_start:self.frame_end] #print('frames',frames) # if self.remove_duplicates: # frames = self.remove_duplicate_frames(out_path) img = imread(frames[0]) int_width = img.shape[1] int_height = img.shape[0] channel = img.shape[2] if not channel == 3: return if int_width != ((int_width >> 7) << 7): int_width_pad = (((int_width >> 7) + 1) << 7) # more than necessary padding_left = int((int_width_pad - int_width) / 2) padding_right = int_width_pad - int_width - padding_left else: int_width_pad = int_width padding_left = 32 padding_right = 32 if int_height != ((int_height >> 7) << 7): int_height_pad = ( ((int_height >> 7) + 1) << 7) # more than necessary padding_top = int((int_height_pad - int_height) / 2) padding_bottom = int_height_pad - int_height - padding_top else: int_height_pad = int_height padding_top = 32 padding_bottom = 32 frame_num = len(frames) if not os.path.exists(os.path.join(frame_path_interpolated, vidname)): os.makedirs(os.path.join(frame_path_interpolated, vidname)) if not os.path.exists(os.path.join(frame_path_combined, vidname)): os.makedirs(os.path.join(frame_path_combined, vidname)) for i in tqdm(range(frame_num - 1)): if i < self.interpolate_start or (i>self.interpolate_end and self.interpolate_end>0):continue first = frames[i] second = frames[i + 1] first_index = int(first.split(os.sep)[-1].split('.')[-2]) second_index = int(second.split(os.sep)[-1].split('.')[-2]) img_first = imread(first) img_second = imread(second) '''--------------Frame change test------------------------''' #img_first_gray = np.dot(img_first[..., :3], [0.299, 0.587, 0.114]) #img_second_gray = np.dot(img_second[..., :3], [0.299, 0.587, 0.114]) #img_first_gray = img_first_gray.flatten(order='C') #img_second_gray = img_second_gray.flatten(order='C') #corr = np.corrcoef(img_first_gray, img_second_gray)[0, 1] #key_frame = False #if corr < self.key_frame_thread: # key_frame = True '''-------------------------------------------------------''' X0 = img_first.astype('float32').transpose((2, 0, 1)) / 255 X1 = img_second.astype('float32').transpose((2, 0, 1)) / 255 assert (X0.shape[1] == X1.shape[1]) assert (X0.shape[2] == X1.shape[2]) X0 = np.pad(X0, ((0,0), (padding_top, padding_bottom), \ (padding_left, padding_right)), mode='edge') X1 = np.pad(X1, ((0,0), (padding_top, padding_bottom), \ (padding_left, padding_right)), mode='edge') X0 = np.expand_dims(X0, axis=0) X1 = np.expand_dims(X1, axis=0) X0 = np.expand_dims(X0, axis=0) X1 = np.expand_dims(X1, axis=0) X = np.concatenate((X0, X1), axis=0) o = self.base_forward(X) y_ = o[0] y_ = [ np.transpose( 255.0 * item.clip( 0, 1.0)[0, :, padding_top:padding_top + int_height, padding_left:padding_left + int_width], (1, 2, 0)) for item in y_ ] if self.remove_duplicates: num_frames = times_interp * (second_index - first_index) - 1 time_offsets = [ kk * timestep for kk in range(1, 1 + num_frames, 1) ] start = times_interp * first_index + 1 for item, time_offset in zip(y_, time_offsets): out_dir = os.path.join(frame_path_interpolated, vidname, "{:08d}.webp".format(start)) imsave(out_dir, np.round(item).astype(np.uint8)) start = start + 1 else: time_offsets = [ kk * timestep for kk in range(1, 1 + num_frames, 1) ] count = 1 for item, time_offset in zip(y_, time_offsets): out_dir = os.path.join( frame_path_interpolated, vidname, "{:08d}{:01d}.webp".format(self.frame_start+i, count)) count = count + 1 imsave(out_dir, np.round(item).astype(np.uint8)) input_dir = os.path.join(frame_path_input, vidname) interpolated_dir = os.path.join(frame_path_interpolated, vidname) combined_dir = os.path.join(frame_path_combined, vidname) ##kevin ##if self.remove_duplicates: ## self.combine_frames_with_rm(input_dir, interpolated_dir, ## combined_dir, times_interp) ## else: num_frames = int(1.0 / timestep) - 1 self.combine_frames(frames, interpolated_dir, combined_dir, num_frames) frame_pattern_combined = os.path.join(frame_path_combined, vidname, '%08d.webp') #frame_pattern_combined = sorted(glob.glob(os.path.join(frame_path_combined,vidname, '*.webp'))) #print('frame_pattern_combined',frame_pattern_combined) video_pattern_output = os.path.join(video_path_output, vidname + '.mp4') if os.path.exists(video_pattern_output): os.remove(video_pattern_output) #kevin frames2video(frame_pattern_combined, video_pattern_output,str(int (fps))) # return frame_pattern_combined, video_pattern_output def combine_frames(self, frames, interpolated, combined, num_frames): frames1 = frames frames2 = sorted(glob.glob(os.path.join(interpolated, '*.webp'))) num1 = len(frames1) num2 = len(frames2) for i in range(num1): src = frames1[i] imgname = int(src.split(os.sep)[-1].split('.')[-2]) if imgname<=self.interpolate_start: dst=os.path.join(combined,'{:08d}.webp'.format(imgname-self.frame_start)) elif imgname<=self.interpolate_end: dst=os.path.join(combined,'{:08d}.webp'.format((imgname-self.interpolate_start)*num_frames+imgname-self.frame_start)) else: dst=os.path.join(combined,'{:08d}.webp'.format((self.interpolate_end-self.interpolate_start)*(num_frames+1) \ +self.interpolate_start+(i-self.interpolate_end)-self.frame_start)) # print('i,imgname',i,imgname) #assert i == imgname #dst = os.path.join(combined, # '{:08d}.webp'.format(imgname * (num_frames + 1))) shutil.copy2(src, dst) #print('dst1',dst) for i in range(num2): try: imgname = src.split(os.sep)[-1] src = frames2[i ] #src2=src[-12:-4]+'_' dst = os.path.join( combined,'{:08d}.webp'.format((i+self.interpolate_start+1+i//num_frames)-self.frame_start)) #print('dst2',dst) shutil.copy2(src, dst) except Exception as e: print(e) def combine_frames_with_rm(self, input, interpolated, combined, times_interp): frames1 = sorted(glob.glob(os.path.join(input, '*.webp'))) frames2 = sorted(glob.glob(os.path.join(interpolated, '*.webp'))) num1 = len(frames1) num2 = len(frames2) for i in range(num1): src = frames1[i] index = int(src.split(os.sep)[-1].split('.')[-2]) dst = os.path.join(combined, '{:08d}.webp'.format(times_interp * index)) shutil.copy2(src, dst) for i in range(num2): src = frames2[i] imgname = src.split(os.sep)[-1] dst = os.path.join(combined, imgname) shutil.copy2(src, dst) def remove_duplicate_frames(self, paths): def dhash(image, hash_size=8): gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) resized = cv2.resize(gray, (hash_size + 1, hash_size)) diff = resized[:, 1:] > resized[:, :-1] return sum([2**i for (i, v) in enumerate(diff.flatten()) if v]) hashes = {} max_interp = 9 image_paths = sorted(glob.glob(os.path.join(paths, '*.webp'))) for image_path in image_paths: image = cv2.imread(image_path) h = dhash(image) p = hashes.get(h, []) p.append(image_path) hashes[h] = p for (h, hashed_paths) in hashes.items(): if len(hashed_paths) > 1: first_index = int(hashed_paths[0].split( os.sep)[-1].split('.')[-2]) last_index = int(hashed_paths[-1].split( os.sep)[-1].split('.')[-2]) + 1 gap = 2 * (last_index - first_index) - 1 if gap > 2 * max_interp: cut1 = len(hashed_paths) // 3 cut2 = cut1 * 2 for p in hashed_paths[1:cut1 - 1]: os.remove(p) for p in hashed_paths[cut1 + 1:cut2]: os.remove(p) for p in hashed_paths[cut2 + 1:]: os.remove(p) if gap > max_interp: mid = len(hashed_paths) // 2 for p in hashed_paths[1:mid - 1]: os.remove(p) for p in hashed_paths[mid + 1:]: os.remove(p) else: for p in hashed_paths[1:]: os.remove(p) frames = sorted(glob.glob(os.path.join(paths, '*.webp'))) return frames登录后复制4模型使用
In [10]!rm -rf /home/aistudio/output/DAIN#慢动作速率,0.25相当于 新生成3帧slow_rate=0.25# 待处理视频路径path='/home/aistudio/shijinsai.mp4'## 裁切视频videoIndex=[a,b],到时候只输出视频的第a帧到第b帧,整个视频则设空数组[]videoIndex=[]## 裁切视频,先把第几帧到第几帧的视频切出来,不切取视频则设空数组[],这里还是原视频的帧数slowIndex=[120,150]dain=DAINSlowMotion(output='output', weight_path=None, use_gpu=True, remove_duplicates=False)##输出视频在 output/DAIN/videos-outputdain.run(path,slow_rate,videoIndex,slowIndex)登录后复制
[07/09 16:24:17] ppgan INFO: Found /home/aistudio/.cache/ppgan/DAIN_weight.tar[07/09 16:24:17] ppgan INFO: Decompressing /home/aistudio/.cache/ppgan/DAIN_weight.tar...登录后复制
2024-07-09 16:24:17,776-WARNING: The old way to load inference model is deprecated. model path: /home/aistudio/.cache/ppgan/DAIN_weight/model, params path: /home/aistudio/.cache/ppgan/DAIN_weight/params登录后复制
Old fps (frame rate): 25.0New fps (frame rate): 25.0登录后复制
0%| | 0/356 [00:00登录后复制('output/DAIN/frames-combined/shijinsai/%08d.webp', 'output/DAIN/videos-output/shijinsai.mp4')登录后复制代码解释 相关攻略

GitHub前掌门人押注AI编码浪潮下的新基建,获得6000万美元种子轮融资,视图打造AI生成代码的「管理员」,成为适配编程智能体的原生开发平台 硅谷正在用真金白银,重写软件工程的底层逻辑。 2026年2月,GitHub前CEO Thomas Dohmke创办的Entire,以3亿美元估值完成了60

可15分钟内自动生成结构清晰的周报:通过方舟CodingPlan连接Git仓库、设定时间与过滤条件、启用智能归类与语义摘要、插入定制化区块并导出PDF。 还在为每周手动整理Git提交记录而头疼吗?耗时费力不说,还容易遗漏关键信息。其实,借助方舟CodingPlan这类工具,完全可以在15分钟内自动生

预测2026年可能成为下一个百倍币的几个项目 在加密市场寻找潜力项目,光看叙事和热度远远不够。真正的价值支撑,最终要回归到具体的技术指标和生态进展上。今天,我们就聚焦五个备受关注的项目:SUI、TIA、RSS3、MERL和IO。要判断它们是否名副其实,不能只听故事,必须亲手验证以下三项核心数据。 一

C++如何判断字符串是否为数字:isdigit与regex两种方法【实战】 最轻量高效的方法是使用std::isdigit逐字符检查,但必须先将char转为unsigned char以避免未定义行为,同时需单独处理空字符串;当依赖locale时结果可能异常,更推荐使用ASCII范围手动比较:c >=

准备工作:安装Node js 21+与Git版本控制工具 在正式部署OpenClaw之前,请务必完成运行环境的配置。您需要在计算机上预先安装Node js(建议使用21或更高版本)以及Git版本控制系统。这两项是确保后续所有步骤顺利执行的先决条件。 一、安装pnpm包管理器 首先,我们需要安装高效的
热门专题







热门推荐

数据挖掘与分析的基本流程 想把一堆数据变成洞察和决策?你需要一个系统的流程。这里梳理了一套清晰可行的路径,按步骤推进,能让你的数据分析工作事半功倍。 第一步:数据探索 拿到数据别急着动手。先得跟它“认识认识”,看看它到底长什么样。这个过程就是数据探索:通过检验数据质量、绘制图表、计算关键特征量等方式

数据抓取这件事,本质上就是让自动化程序代替人手,按照预设的规则,从浩瀚的互联网上高效地收集公开信息。整个过程听起来很技术化,但其实可以把它拆解成几个环环相扣的步骤,理解起来并不难。 目标选择 第一步是明确方向。就像出门寻宝得先有张地图,数据抓取也需要事先锁定目标网站,并精确圈定出你要提取的具体数据内

在商业领域中,合同管理是一项至关重要的任务 生意越做越大,需要处理的合同自然也堆积如山。这时候,合同管理的效率与准确性,就成了所有管理者必须直视的关键问题。如何应对?答案之一是建立起一套高效的合同快速对比机制。今天,我们就来拆解一下实现合同快速对比的核心步骤与实用方法,帮你把这项繁琐却重要的工作,变

币圈巨鲸地址可通过五种方式识别:一、用Etherscan等浏览器查Top Holders;二、借Nansen、Arkham等平台看已标记地址;三、监控CryptoQuant交易所净流量;四、订阅Whale Alert实时警报;五、交叉验证Nansen、Glassnode等多源数据确保准确性。 币圈加

谷歌与苹果联手:下一代Siri背后的AI范式转移 科技圈最近有个大新闻,在Google Cloud Next26大会上,官方消息终于落定:苹果正式选定谷歌作为其首选云服务提供商。双方正在联手,基于谷歌的Gemini模型,共同开发下一代“Apple Foundation”机型。这意味着什么?简单说,那