基于Datasheet二次开发的纯浏览器端PostgreSQL数据分析工具
时间:2026-06-29 17:45
最近一直在用 CodeBuddy 和 WorkBuddy 辅助日常开发,确实方便了不少。不过每次对话都会生成详细的日志:用了哪个模型、消耗了多少积分、调用时间等等,全部记录在案。这些数据被导出为一个 Excel 文件,按理说 Excel 做统计分析应该信手拈来——但现实往往不按剧本来。 坦白说,我对
最近一直在用 CodeBuddy 和 WorkBuddy 辅助日常开发,确实方便了不少。不过每次对话都会生成详细的日志:用了哪个模型、消耗了多少积分、调用时间等等,全部记录在案。这些数据被导出为一个 Excel 文件,按理说 Excel 做统计分析应该信手拈来——但现实往往不按剧本来。
坦白说,我对 Excel 的使用还停留在“够用”的水平。复杂的数据透视表、公式统计,常常让人绕得头昏脑涨。每次想统计“某月各模型的使用次数与积分消耗”,或者看看“某月每天的积分使用趋势”,都得在 Excel 里鼓捣半天,结果还不一定对。
那更理想的方案是什么?把数据导入数据库,用 SQL 查询——这才是最顺手的姿势。但问题是,每次要启动本地数据库、写导入脚本,实在太麻烦了。想要一款这样的工具:
- 无需安装,打开浏览器就能用
- 支持 SQL 查询,用最顺手的方式分析数据
- 数据能持久化,刷新页面不会丢
- 最好还能有些可视化能力,让数据更直观
正巧,在 GitHub 上刷到了一个很有意思的开源项目——Datasheet。它基于 PGlite 在浏览器中运行完整的 PostgreSQL 数据库,数据存储在 IndexedDB 中,完美契合了“浏览器内 SQL 分析”这个需求。
于是 Fork 了这个项目,过程中修复了一些 Bug,并根据实际需求新增了不少功能。下面把这些修改记录下来,希望也能帮到有类似需求的朋友。
什么是 Datasheet?
Datasheet 是一个基于浏览器的 PostgreSQL 数据管理工具,核心是 PGlite——一个将 PostgreSQL 编译为 WebAssembly 的方案,可以在浏览器中直接运行完整的 PG 数据库。
原项目的核心特性
- 浏览器内 PostgreSQL:无需安装数据库,数据持久化到 IndexedDB
- 多工作区管理:通过 Schema 隔离,支持创建/切换/删除工作区
- SQL 编辑器:基于 CodeMirror,支持语法高亮、智能提示
- 数据导入:从 Excel/CSV 导入数据,可视化配置映射关系
- 表结构浏览:左侧栏展示数据库表列表
- 查询结果编辑:表格形式展示,支持直接编辑并保存
我做了哪些修改?
Bug 修复
1. 数据导入表头错误
问题在于,导入 Excel 时,表头竟然被当作数据行一起导入了。排查发现,`ImportDialog.vue` 中获取数据行时使用了错误的切片起点。原代码用 `headerRow` 作为切片起点,实际上应该用 `dataStartRow`。修复后,数据从正确的行开始读取,表头独立映射为列名。
2. 查询结果首行缺失
执行 `SELECT` 查询后,结果集的第一行数据总是神秘消失。原因在 `index.vue` 中,对查询结果做了 `rows.slice(1)` 处理,大概原本想跳过表头,结果把真正的数据行给误跳了。对于那些聚合查询(比如 `SUM`、`COUNT`),结果只有一行时干脆直接不显示。修复后,不再对查询结果进行切片,完整显示所有行。
3. 类型推断精度不足
导入数据时,如果数值列的后续行有大数值,会报 `numeric field overflow` 错误。翻看代码发现,`useImport.ts` 中的类型推断只采样了前 10 行数据来判断列类型。如果前 10 行都是小数值,后面突然冒出一个大整数,类型设置自然就偏小了。修复后,改为扫描全部数据行进行类型推断,确保精度够用。
4. 日期时间类型丢失时间部分
包含时间的日期列,导入后被推断为 `DATE` 类型,时间部分直接丢了。原因是日期和日期时间都被检测为 `DATE` 类型。修复方案是增加时间检测逻辑,区分 `DATE`(仅日期)和 `TIMESTAMP`(日期+时间),并在导入时格式化为标准格式。
新增功能
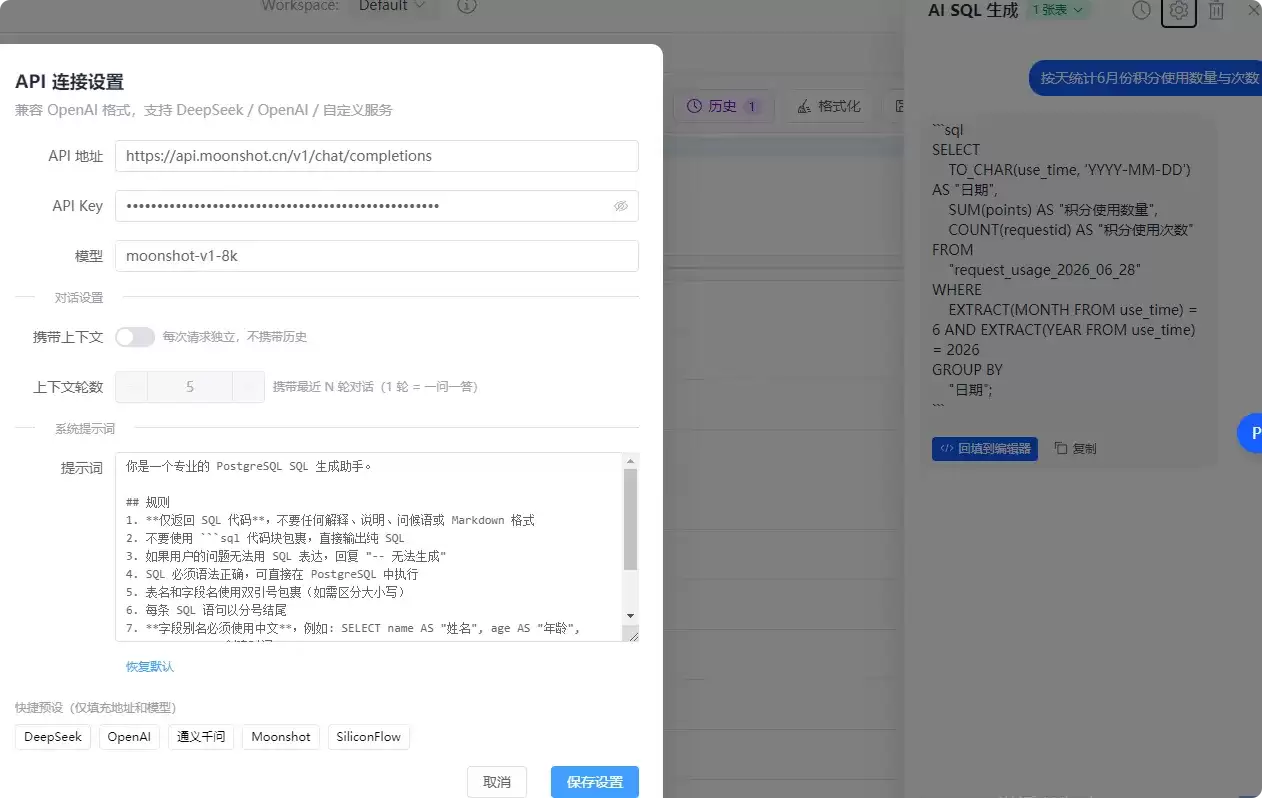
1. AI SQL 生成
这应该是最受欢迎的新功能。接入兼容 OpenAI 格式的大模型 API,用自然语言描述需求,AI 自动生成 SQL。支持的平台包括:DeepSeek、OpenAI、通义千问、Moonshot、SiliconFlow。配置方面也很灵活:API 地址、Key、模型都可以自定义;系统提示词可调整;支持选择表结构作为上下文来减少 Token 消耗;还能配置是否携带对话历史及轮数。
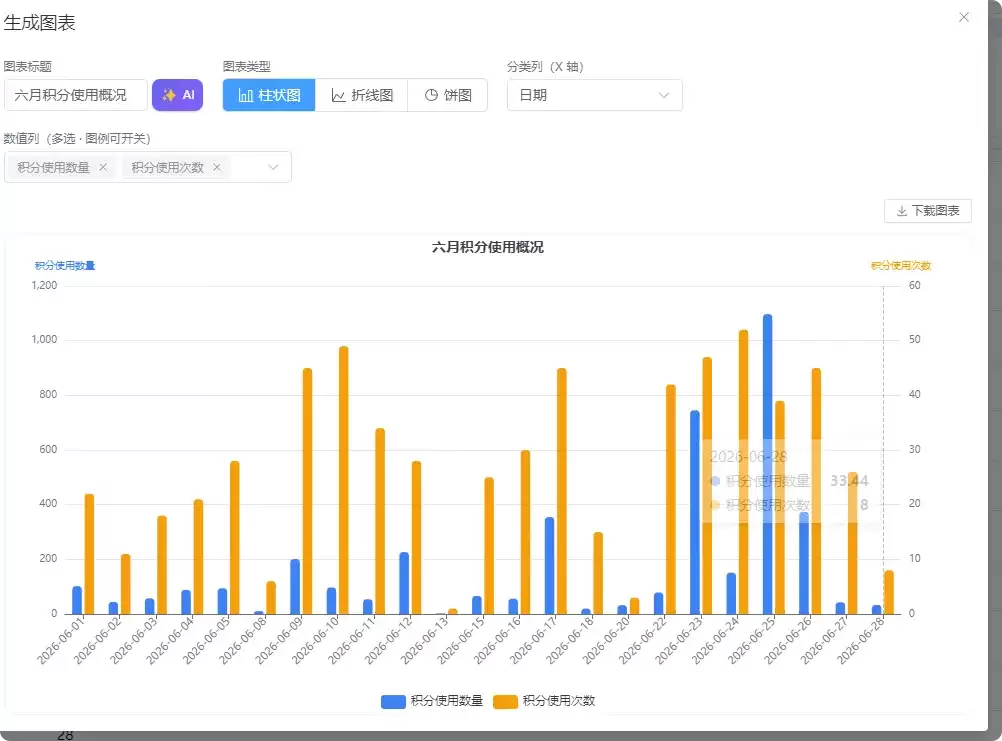
2. 数据可视化
查询结果可以一键生成图表,这对于数据分析来说太实用了。支持的图表类型包括:柱状图、折线图、饼图。特色功能也不少:可以多选数值列,支持多 Y 轴交替左右分布;不同颜色区分数据系列;图例支持点击开关;AI 还能根据 SQL 自动生成图表标题;图表可以下载为 PNG 图片;双饼图还能合并导出。柱状图的细节也做了优化:自适应宽度,横坐标过长时斜 45° 显示,省略号截断,网格边距防遮挡。
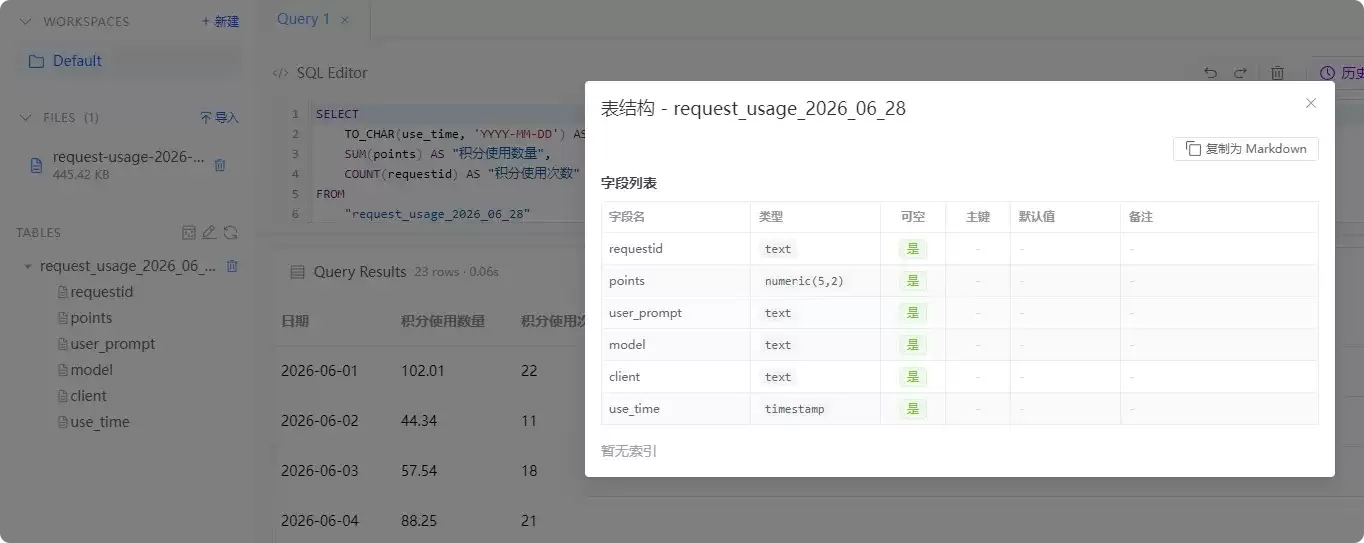
3. 表结构查看
在左侧 TABLES 树中右键点击表名,弹出菜单选择“查看表结构”。展示的信息很全面:字段名、数据类型、是否可空、主键标识、默认值、字段备注、索引信息。还有一个实用的小功能:一键复制为 Markdown,方便在文档中记录表结构,或者作为 AI 生成 SQL 的上下文。
4. SQL 收藏
常用 SQL 可以保存下来,方便随时复用。保存时填写标题、SQL 内容、描述;左侧 SA VED SQL 列表展示所有收藏;点击即可加载到编辑器;支持编辑和删除。
5. 标签页增强
多标签页管理更加顺手:右键菜单支持关闭其它标签、关闭左侧标签、关闭右侧标签;“新建查询”按钮重新设计为青绿色渐变样式,更加醒目。
6. 删除功能完善
补充了原来缺失的删除操作:删除表(表行末固定显示删除按钮)、删除工作区(非 default 工作区列表行末显示删除按钮)、删除文件(侧边栏、对话框、详情页均添加删除按钮)。
7. 日期格式化显示
所有查询结果中的 Date 对象统一显示为 `yyyy-MM-dd HH:mm:ss` 格式,让时间数据一目了然。
8. 列宽拖拽
查询结果表格支持鼠标拖拽调整列宽,列头右侧显示蓝色拖拽手柄,方便查看长文本内容。
9. GitHub Pages 自动部署
新增 `deploy.yml` GitHub Actions 工作流,push 到 main 分支自动构建并部署到 GitHub Pages。
项目技术栈
- Nuxt 4 + Vue 3 + TypeScript
- Element Plus UI 组件库
- PGlite 浏览器内 PostgreSQL
- CodeMirror 5 SQL 编辑器
- ECharts 5 数据可视化
- UnoCSS 原子 CSS
- Pinia + VueUse
如何使用
在线体验
直接访问在线版本即可使用。
本地开发
# 安装依赖
pnpm install
# 启动开发服务器
pnpm dev
# 构建生产版本
pnpm build
# 静态生成(用于 GitHub Pages 部署)
pnpm generate
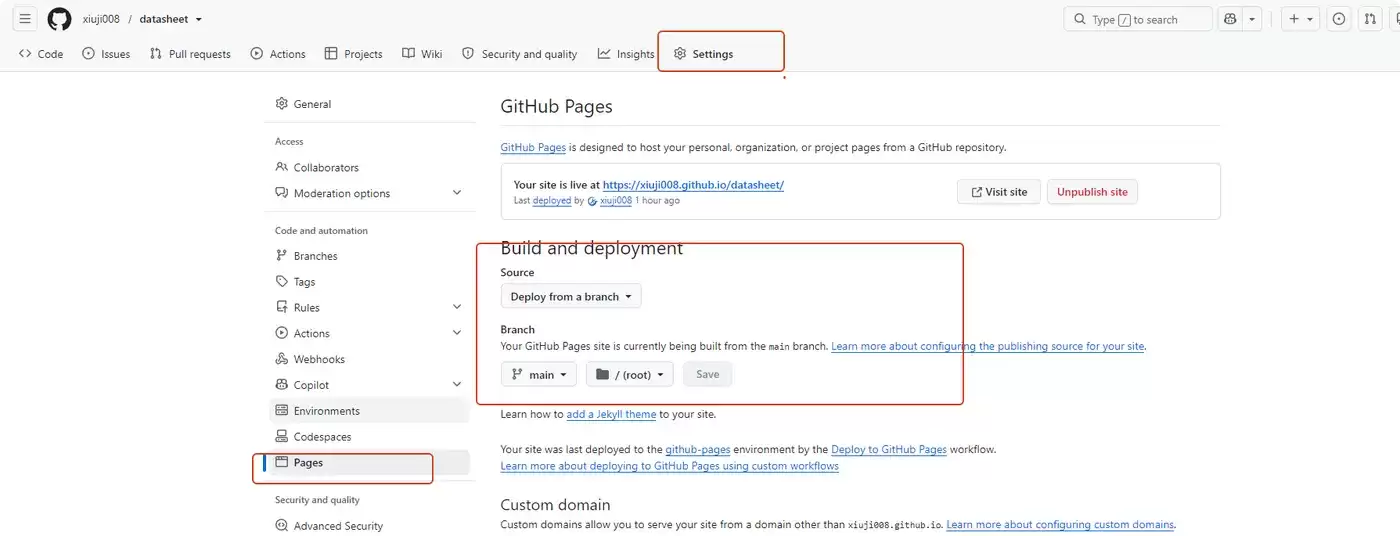
Github Pages 部署
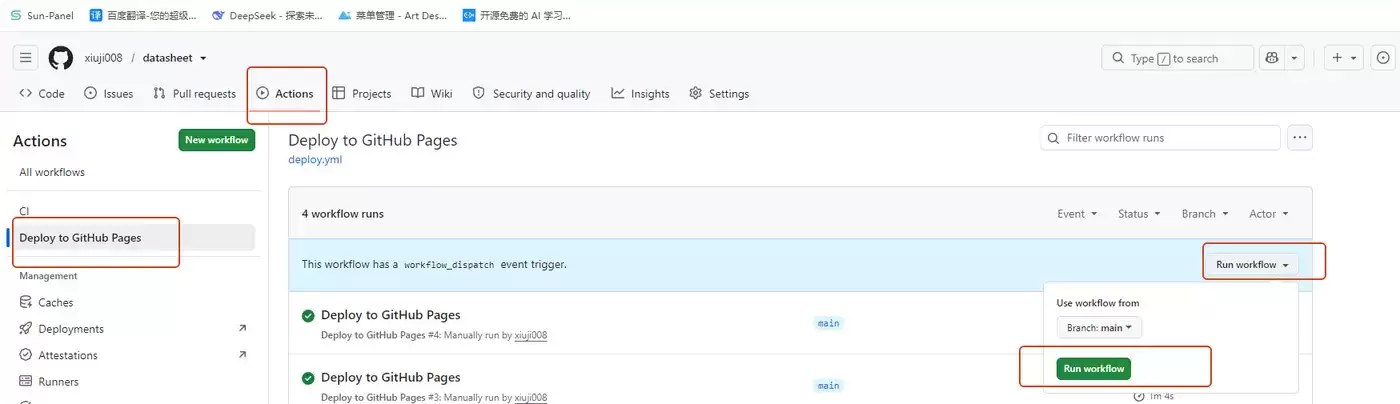
直接 fork 本项目后设置 `Pages`,然后在 `Actions` 执行完成即可访问。
Docker部署
1. 创建部署目录 `mkdir datasheet`
2. 创建 `docker-compose.yml` 文件,内容如下:
services:
datasheet:
image: registry.cn-hangzhou.aliyuncs.com/xj_lew/datasheet:1.0.0
container_name: datasheet
ports:
- '3000:3000'
restart: unless-stopped
3. 启动容器:`docker-compose up -d`
4. 访问项目:在浏览器中打开部署地址即可访问
使用场景
场景一:积分统计与分析
回到最初的需求——把 CodeBuddy/WorkBuddy 的日志 Excel 导入 Datasheet:
1. 点击“导入数据”,选择 Excel 文件
2. 自动识别表头和数据,映射到表中
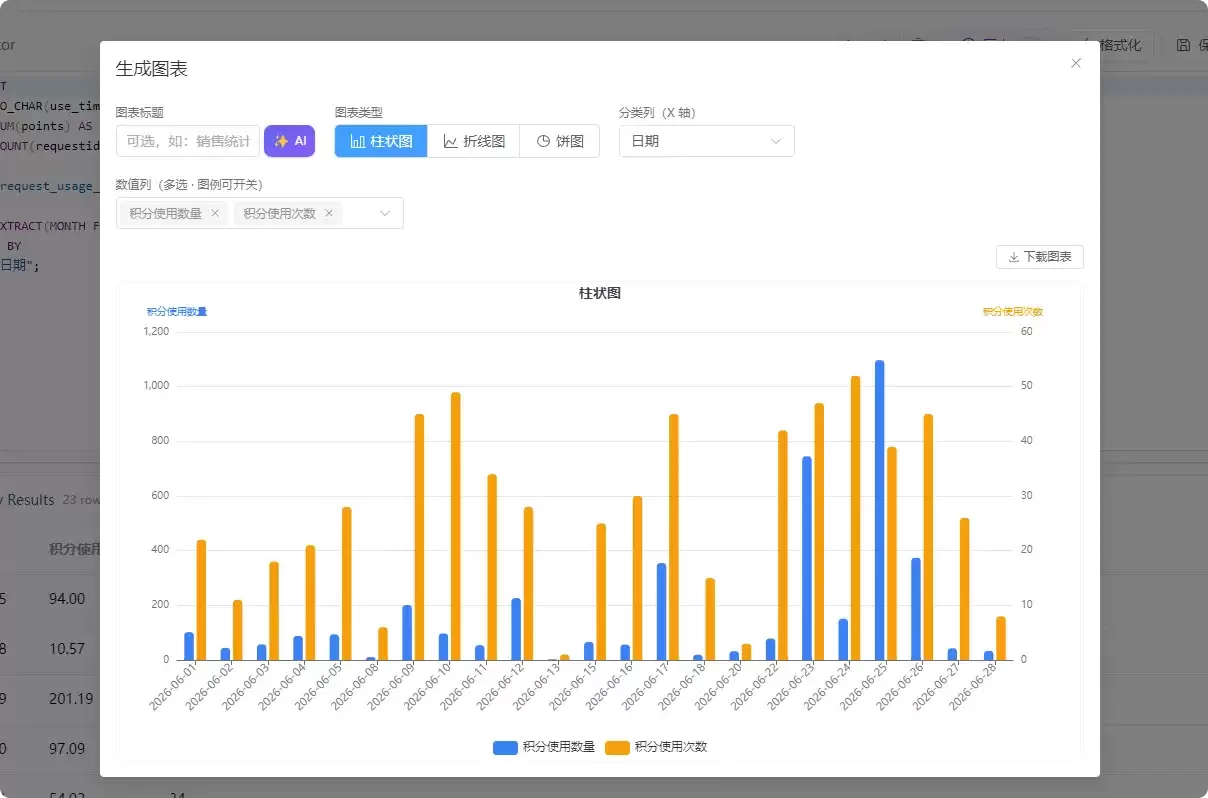
3. 在 SQL 编辑器中写查询:
SELECT
TO_CHAR(use_time, 'YYYY-MM-DD') AS "日期",
SUM(points) AS "积分使用数量",
COUNT(requestid) AS "积分使用次数"
FROM "request_usage_2026_06_28"
WHERE EXTRACT(MONTH FROM use_time) = 6 AND EXTRACT(YEAR FROM use_time) = 2026
GROUP BY "日期";
4. 点击“图表”,选择柱状图,选择日期作为 X 轴,使用次数和积分作为 Y 轴,分析结果一目了然。
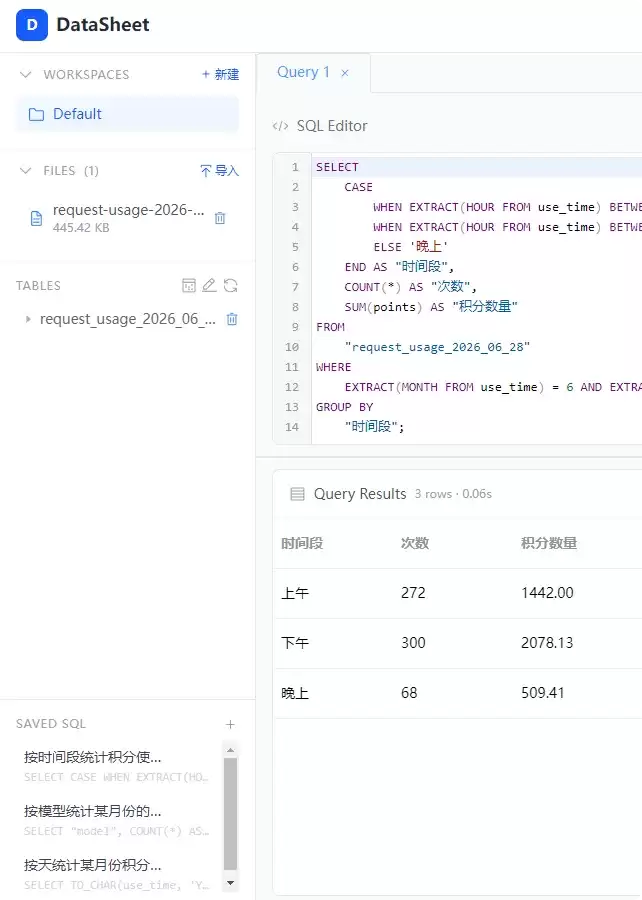
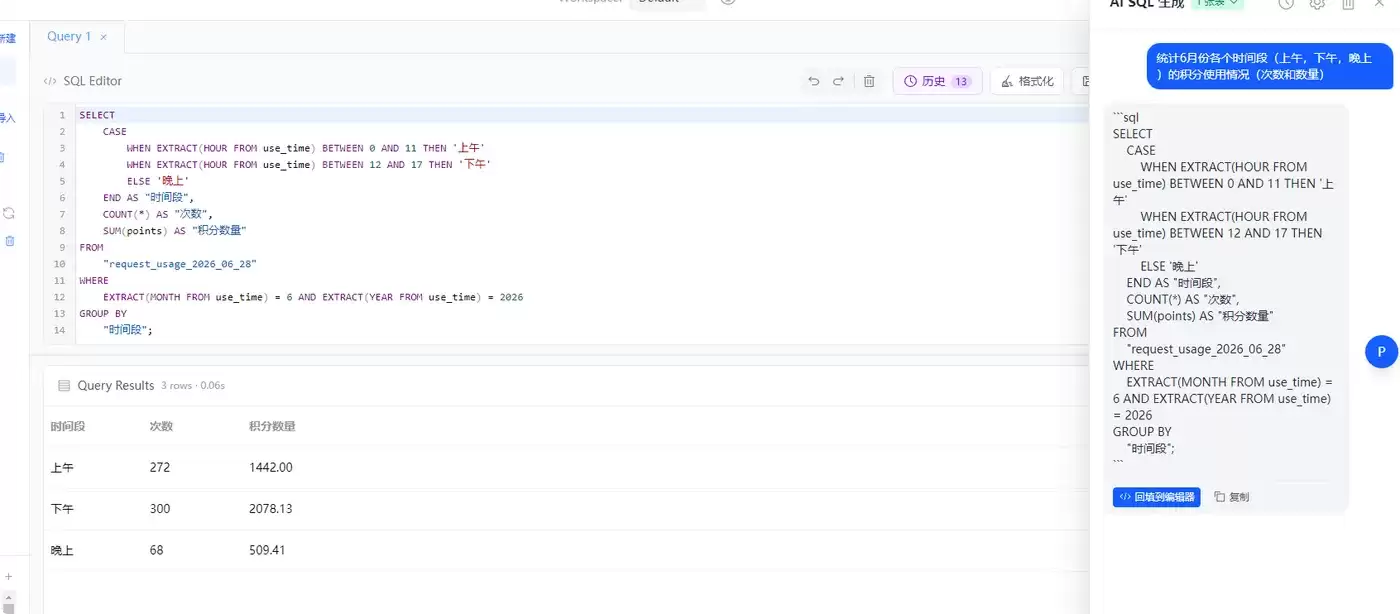
场景二:AI 辅助 SQL 生成
不熟悉 SQL 语法也没关系:
1. 点击「✨ AI 生成 SQL」按钮
2. 用自然语言描述:`统计6月份各个时间段(上午,下午,晚上)的积分使用情况(次数和数量)`
3. AI 自动生成 SQL,点击“回填并执行”即可。
场景三:数据探索与可视化
导入任意数据后:
1. 左侧查看所有表结构
2. 写 SQL 探索数据
3. 一键生成图表
4. 保存常用查询,下次一键复用
与原项目对比
| 功能 | 原版 Datasheet | 修改版 |
|---|
| SQL 编辑器 | ✅ | ✅ |
| 数据导入 | ✅ | ✅(修复表头错误、类型推断) |
| 多工作区 | ✅ | ✅(增加删除功能) |
| 表结构查看 | 基础 | ✅ 右键弹窗 + Markdown 复制 |
| SQL 收藏 | ❌ | ✅ |
| AI 生成 SQL | ❌ | ✅ |
| 数据可视化 | ❌ | ✅(柱状/折线/饼图) |
| 列宽拖拽 | ❌ | ✅ |
| 日期格式化 | ❌ | ✅ |
| 标签页管理 | 基础 | ✅ 右键关闭其它/左侧/右侧 |
写在最后
这个项目目前还在持续迭代中,作为一个纯前端工具,它很好地解决了“在浏览器中分析数据”这个需求。如果你也有类似的使用场景——比如分析日志数据、探索数据集、或者单纯想在浏览器里用 SQL 分析 Excel 数据——不妨试试这个工具。
开源项目最有趣的地方就在于:可以按照自己的需求去修改它、扩展它,让它真正为你所用。




