先说说核心判断。今天继续探讨基于本体构建的电商数据分析项目,上一篇完成了框架搭建,这篇重点聚焦于优化改进。同时,也希望把之前的核心观点再往前推进一层。
那个核心观点是什么?——经典本体论(OWL、SWRL、SHACL)的局限性,不在于“推理能力弱”,而在于“推理空间是封闭的”。它只能在有限的公理集合里做演绎。但真实的商业分析,恰恰要求跳出这个封闭空间去做溯因和策略生成——而这,是LLM能做到、SWRL规则引擎永远做不到的。
摘要
当前的ecommerce-ontology-analytics项目,实现了一套四阶段的“本体驱动电商数据智能分析”系统:需求探索→本体建模→场景执行与推理→对话式分析。在对Phase3核心代码做逐行审查后,发现系统在架构层面有一个根本性问题:精确算法逻辑和AI动态模糊推理的边界,被混淆了。
具体表现为四个关键缺陷:(1)AI被用于生成确定性的SQL查询;(2)LLM自评的置信度被当成了统计推断;(3)数据注入采用暴力字符截断,而非结构化摘要;(4)本体模型的语义信息仅被浅层消费。这篇文章会逐一分析这些问题,并提出一个基于“精确层+护栏机制+动态层”三层分离的改进架构。
核心论点再说一遍:经典本体论的局限性不在推理能力本身,而在它只能在一个封闭的公理空间里做演绎。真实商业分析需要溯因和策略生成,这恰恰是LLM的强项,也是规则引擎的盲区。两者不是替代关系,而是分层协作关系。
1. 引言:一个架构层面的根本混淆
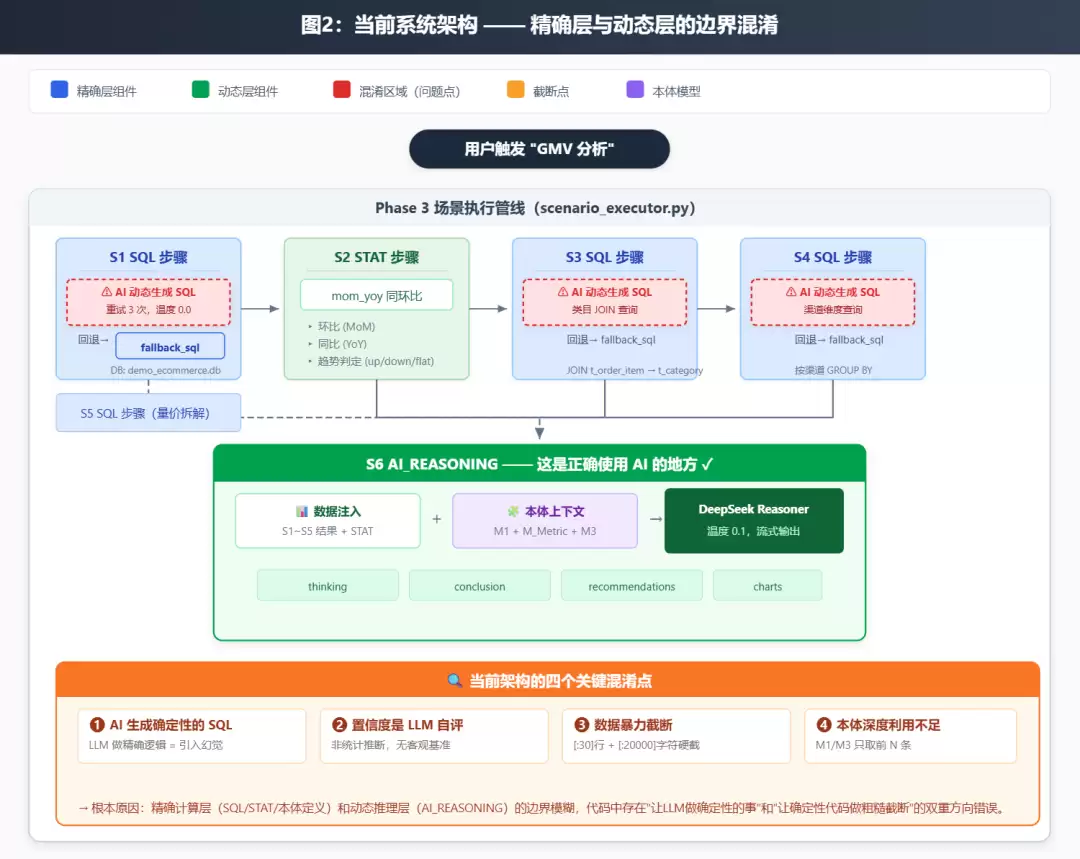
Phase1和Phase2完成需求探索和本体建模后,Phase3进入核心执行阶段。以GMV分析场景为例,执行流程包含6个步骤:S1~S5负责SQL查询和统计计算,S6交给LLM做业务推理。
表面上看,这个分工挺合理的:精确的数据查询交给SQL和Python,复杂的业务解读交给LLM。但深入到代码层面,这个分工在执行层被打破了。系统在以下四个环节,出现了精确与模糊的边界混淆:
- SQL生成:让LLM动态生成SQL,虽然预设了
fallback_sql兜底,但AI生成是默认主路径。 - 数据注入:用
[:30]行截断和[:20000]字符硬截断将查询结果喂给LLM,丢失了统计分布信息。 - 置信度计算:完全依赖LLM在输出文本中自行标注“置信度: XX%”,代码仅用正则表达式提取。
- 本体利用:M1/M3本体仅取前12条/6条注入Prompt,未按语义相关度筛选。
这四个问题的共同根源在于:系统没有明确定义“什么是确定性计算”和“什么是启发式推理”的边界。结果就是两边都做得不对——让LLM做了它不该做的事(生成SQL),又让确定性代码做了粗糙的事(暴力截断数据)。
接下来的章节会逐一剖析这些问题,并提出可落地的改进方案。
2. 经典本体论的推理空间与LLM的互补性
2.1 经典本体论:一个封闭的演绎系统
经典语义网技术栈的核心组件及其能力边界如下:
| 组件 | 能力 | 盲区 |
|---|---|---|
| OWL(本体定义) | 定义实体、属性、关系、基数约束 | 无法表达概率性、时序性、因果性知识 |
| SWRL(推理规则) | Horn子句形式的IF-THEN推导 | 规则前提必须完全已知,无法处理“可能原因” |
| SHACL(约束校验) | 数据完整性、一致性验证 | 只能检测违规,不能解释违规原因 |
这三者的共同特点是:推理空间是封闭的。它们只能在一个有限的、预先定义的公理集合内进行演绎推理。给定公理集A = {A₁, A₂, ..., Aₙ},推理引擎只能推导出A逻辑蕴含的结论,永远不会“跳出”公理集生成新的假设。
以电商经营分析为例,SWRL可以写出这样的规则:
有效订单(oid) ← 订单(oid) ∧ hasStatus(oid, s) ∧ s ∉ {5, 6}高风险类目(cid) ← 类目(cid) ∧ 退款率(cid, r) ∧ r > 0.10但SWRL无法写出:
GMV下降原因(?) ← GMV(近3月, ↓40%)原因不是表达能力不够——理论上可以穷举所有可能原因写成规则。但“可能原因”的集合是开放的、无限的、依赖于外部世界知识的:宏观经济下行、竞品冲击、季节因素、供应链中断、质量事故、定价策略失误、营销活动透支……这个列表可以无限延伸,且每个原因的判断都需要复杂的商业逻辑理解。
2.2 LLM 填补的空白:溯因推理与策略生成
LLM能做到经典本体论做不到的,正是以下三类任务:
- 溯因推理(Abduction)——从现象反推原因
这不是IF-THEN规则能推导的。这需要LLM理解“清仓活动通常意味着质量让步”、“质量让步会导致退款率上升”、“退款经历会降低复购意愿”、“持续降价会损害品牌价格体系”等一系列商业常识。
- 策略生成(Strategy Generation)——从分析到行动
策略空间是无限的,无法被有限规则穷举。LLM能结合本体中定义的实体关系(商品→店铺→供应商,订单→退款→原因)和外部商业知识,生成具体可执行的行动建议。
- 语境解读(Contextual Interpretation)——理解数字背后的含义
这种解读需要同时理解多个维度的数据,并将它们编织成一个连贯的商业叙事。这不是规则引擎能做到的。
2.3 关键区分:精确vs动态的分界线
所以,正确的架构不是“本体 vs LLM”的二选一,而是对任务按性质进行精确分层:
| 层 | 任务类型 | 推理性质 | 实现方式 |
|---|---|---|---|
| 精确层 | 数据查询、聚合计算、统计检验、口径验证 | 演绎推理(封闭空间) | 预定义SQL + Python算法 + 本体约束 |
| 动态层 | 因果归因、趋势解读、策略生成、行动建议 | 溯因推理(开放空间) | LLM + 结构化Prompt + 护栏约束 |
这条分界线,是本文所有分析和建议的基石。

图1:经典本体论能力边界
3. 当前系统问题分析
3.1 问题一:AI 动态生成确定性的 SQL
位置:backend/ai/scenario_executor.py:150-250,_execute_sql_step() 函数
现状:系统对每个SQL步骤默认先调用DeepSeek API生成SQL,最多重试3次,AI失败后才回退到fallback_sql。AI生成时的温度设为0.0,试图最大化稳定性。
问题出在哪里:
对于GMV这类预定义场景,SQL是确定性问题——给定Schema、映射和业务需求,正确的SQL是唯一的(或少数几个等价形式)。比如S1的月度GMV查询:
SELECT strftime('%Y-%m', gmt_create) AS period, SUM(payment_amount) AS gmv, COUNT(order_id) AS order_countFROM t_orderWHERE status NOT IN (5,6)AND gmt_create >= date('2025-05-17')GROUP BY periodORDER BY period用LLM去重新“发现”这个SQL,是架构上的方向错误:
- 引入幻觉风险:LLM可能遗漏
status NOT IN (5,6)过滤、使用错误的日期范围、用错聚合函数。 - 增加延迟:5个SQL步骤 × 1-3次API调用 = 5-15次网络往返,累计延迟10-30秒。
- 消耗成本:每次执行GMV场景为5个确定性查询支付Token费用。
- 无增益:
fallback_sql已经是最优解,AI生成的结果不会比它更好。
改进建议:
在场景YAML中增加显式开关,Phase3默认走预定义SQL:
# scenario_executor.py _execute_sql_step 改进use_ai_sql = step.get("use_ai_sql", False)# 默认不走AIif use_ai_sql and api_key_configured:# AI 生成路径(仅用于验证“本体→SQL”能力的测试场景)...else:# 直接执行 fallback_sql(生产默认路径)final_sql = fallback_sqlAI生成SQL的能力保留给Phase4(用户自由提问),因为那里的问题是开放的、无法预定义所有可能的SQL。
3.2 问题二:数据注入的暴力截断
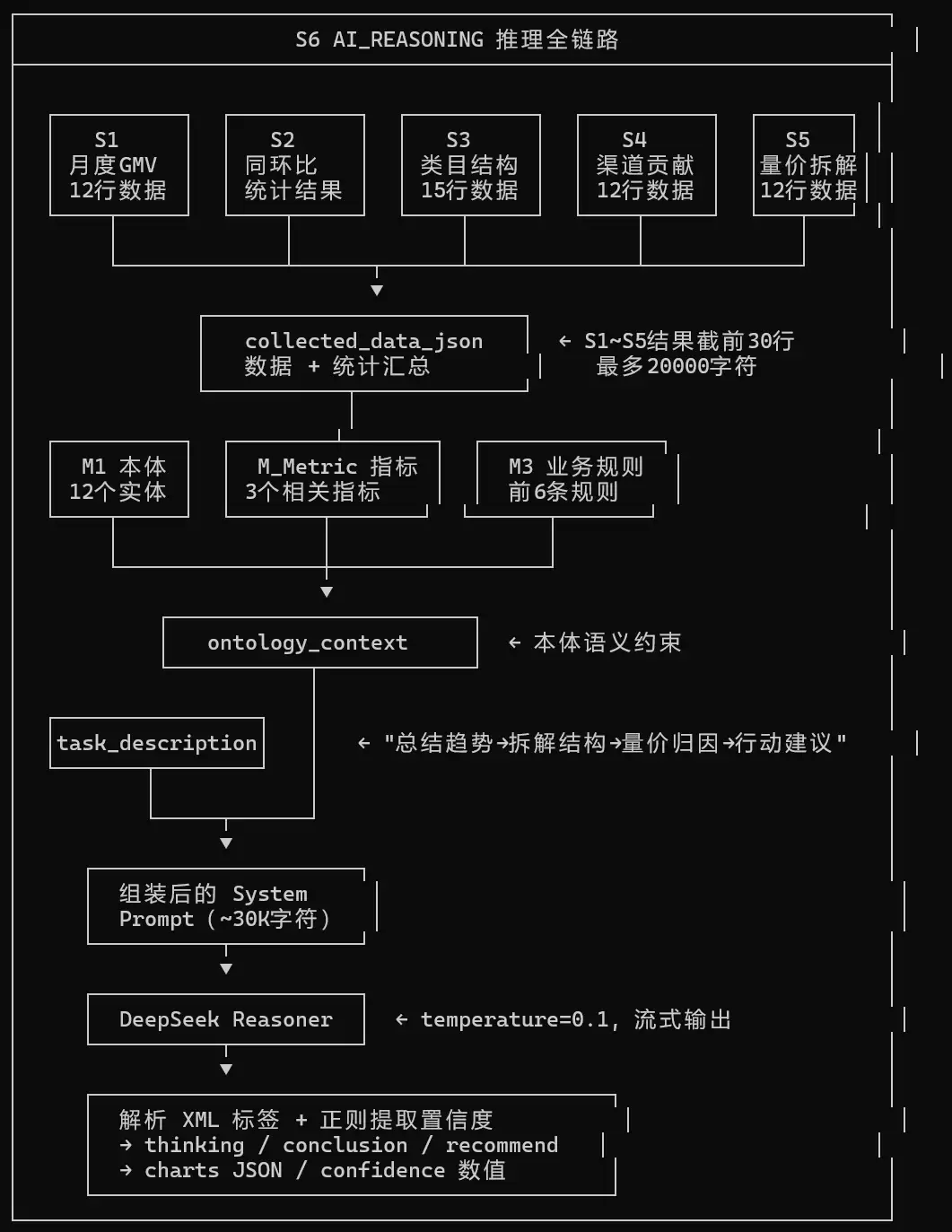
位置:backend/ai/scenario_executor.py:278-293、:299、:384-404
现状:当前系统有7处硬编码截断:
| 行号 | 截断方式 | 后果 |
|---|---|---|
| 287 | rows[:30] | 每步骤只取前30行,丢弃70%的数据 |
| 299 | json.dumps(...)[:20000] | JSON可能在中间被截断,损坏数据结构 |
| 390 | entities[:12] | M1共~14个实体,截断丢弃末尾的Campaign/Coupon |
| 402 | rules[:6] | M3共20条规则,只取前6条 |
| 179 | db_schema_doc[:8000] | 复杂Schema可能丢失关键表定义 |
| 340 | raw_text[:6000] | LLM输出的完整推理被截断在前端 |
| 368 | field_mappings[:8] | 每个实体的映射字段只取前8个 |
问题的本质:
这些截断的本质是用“字符数量”这个错误的维度去控制“信息质量”。前30行不一定是信息密度最高的30行;前12个实体不一定是与当前场景最相关的12个实体。以GMV场景为例——类目分布S3有15行数据,截断取前30行,看起来没问题。但如果类目扩展到100个、时间跨度拉到36个月(36×100=3600行),30行的截断就是灾难性的——LLM可能永远看不到贡献最大的那部分数据。
改进建议:
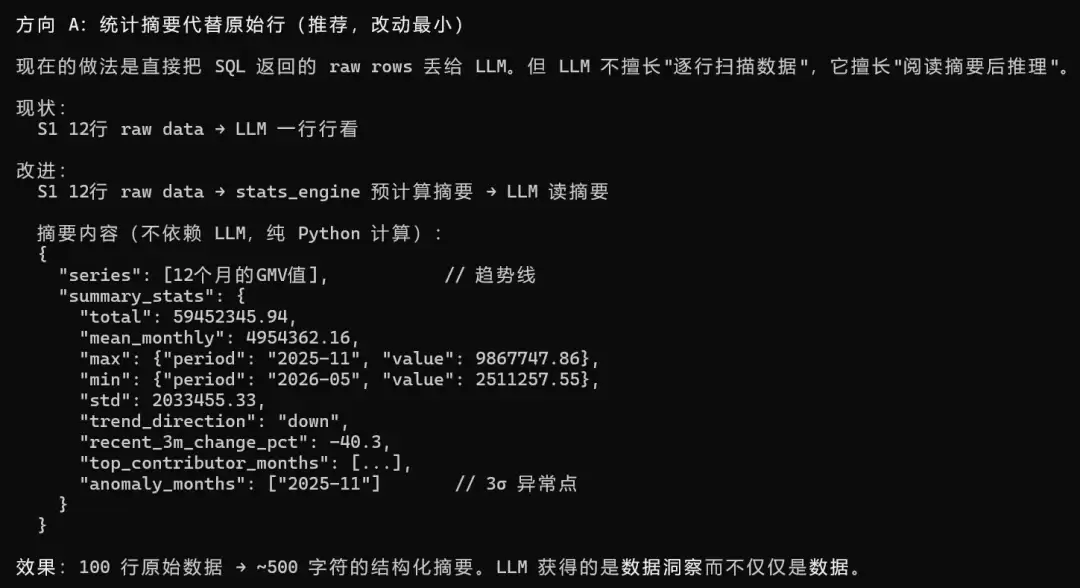
用统计摘要层替代暴力截断。在stats_engine中增加预计算函数,将raw rows转化为结构化洞察:
def compute_data_summary(rows, columns, value_key, period_key=None):"""将 raw rows 转换为统计摘要(确定性计算,不依赖 LLM)"""values = [float(r[value_key]) for r in rows]return {"row_count": len(rows),"summary_stats": {"total": sum(values),"mean": statistics.fmean(values),"median": statistics.median(values),"std": statistics.pstdev(values),"q25": quantile(values, 0.25),"q75": quantile(values, 0.75),"skewness": compute_skewness(values)},"top_n": sorted(rows, key=lambda r: -float(r[value_key]))[:5],"bottom_n": sorted(rows, key=lambda r: float(r[value_key]))[:5],"anomalies": detect_outliers(values, method="modified_zscore"),"trend": compute_trend(rows, period_key, value_key) if period_key else None}效果立竿见影:1000行原始数据 → ~500字符结构化摘要。LLM获得的是数据的统计画像,而不仅仅是数据的前N行。

3.3 问题三:置信度的伪量化
位置:backend/ai/scenario_executor.py:413-428
现状:置信度的计算方式是这样的:
_CONF_RE = re.compile(r"置信度[::]?\s*(\d+)\s*%")# 从 LLM 输出文本中提取所有“置信度: XX%”模式confidences = [85, 72, 90, 68, 79] # 示例a vg = sum(confidences) / len(confidences) # → 78.8问题分析:
这个“置信度”有三个层面的问题:
- 不是统计量:85%和72%之差没有统计学意义。一个发现标注85%,另一个标注72%,并不表示前者的可靠性比后者高13个百分点——它们只是LLM在特定时刻的措辞习惯。
- 不可校准:LLM没有历史准确率作为参照基准。真正的置信度需要“这个判断正确的概率是X%”这样的校准数据支撑。
- 易被Prompt操纵:如果在Prompt中写“宁可低置信度也不要过度自信”,所有的数字都会系统性偏低。如果写“做自信的分析师”,数字会系统性偏高。
改进建议:
建立双轨置信度标注:统计置信度(系统计算) + LLM置信度(LLM标注),并明确区分两者的语义。
# 统计置信度:由代码计算(确定性)stats_confidence = {"trend_significance": mann_kendall_test(values), # 趋势的统计显著性"anomaly_confidence": grubbs_test(values), # 异常点的置信水平"effect_size": cohens_d(group_a, group_b), # 效应量}# LLM 置信度:LLM 自评(启发式),但从 Prompt 层面约束其含义# Prompt 中指定:# “置信度: XX% — 其中 XX 表示:你有 XX% 的把握认为这个推断在类似的商业场景中是成立的”3.4 问题四:本体模型的浅层利用
位置:backend/ai/scenario_executor.py:384-404
现状:_build_ontology_context()将本体信息注入Prompt时,采用简单粗暴的列表截取:
for ent in m1.get("entities", [])[:12]: # 只取前12个实体parts.append(f"- {ent.get('id')}: {ent.get('name')}")for r in m3.get("rules", [])[:6]: # 只取前6条规则parts.append(f"- {r.get('id')}: {r.get('name')} — {r.get('description')}")问题分析:
这种注入方式有两个致命缺陷:
- 只注入了本体字典(ID→名称),未注入本体结构(关系网络)。LLM知道“ENT-ORD-001是订单”,但不知道“订单包含了1到多个订单明细”、“订单明细通过category_id关联到3级类目树”。这些关系信息对于LLM理解数据之间的关联至关重要。
- 未按语义相关度筛选。M3有20条规则(含计算规则和验证规则),但GMV场景只需要前3条计算规则(GMV口径、有效订单数口径、客单价口径)。其余17条与GMV无关的规则(如退款率、营销ROI、库存周转率)注入后不仅浪费上下文,还可能分散LLM的注意力。
改进建议:
将本体注入从“列表枚举”升级为“语义子图”:
def _build_ontology_context(scenario, include_relations=True):"""构建当前场景的语义子图"""# 1. 根据 key_metrics 反向查找相关实体relevant_entities = set()for metric_id in scenario["key_metrics"]:metric = find_metric(metric_id)relevant_entities.update(metric["depends_on_entities"])# 2. 沿关系扩展一跳(找到关联实体)for ent_id in list(relevant_entities):for rel in find_relations_involving(ent_id):# 一跳关系relevant_entities.add(rel["targetEntity"])# 3. 只注入相关实体的完整信息(属性+关系+规则)context = {"entities": [full_entity_info(eid) for eid in relevant_entities],"metrics": [full_metric_info(mid) for mid in scenario["key_metrics"]],"relations": find_relations_between(relevant_entities),"relevant_rules": find_rules_for_entities(relevant_entities),}return format_as_prompt(context)图2:当前系统架构-精确+动态
4. 改进方案:三层分离的融合推理架构
基于上述四个问题的分析,我们提出一个“精确层 + 护栏机制 + 动态层”三层分离的融合推理架构。
4.1 精确计算层(Deterministic Layer)
精确层的职责很明确:所有输入确定、输出确定的计算任务,均在这一层完成,不依赖任何概率模型。
具体包括五个组件:
- ① 本体模型定义(≈ OWL TBox + 指标本体 + 规则库)
- M1:对象模型 —— 12个实体 × 19条关系,定义实体属性、生命周期、约束
- M_Metric:指标模型 —— 20个指标 × SQL模板 × 原子粒度 × 下钻维度 × 单位
- M3:规则模型 —— 20条计算规则(口径定义) + 4条数据质量约束
- 改进点:按场景语义相关性筛选注入,而非列表截取前N条
- ② 预定义SQL执行器
- 场景YAML中
fallback_sql作为primary SQL,经过DBA审核 + 预执行验证 - AI SQL生成保留给Phase4(用户自由提问),因为那里的查询空间是开放的
- 改进点:加
use_ai_sql: true/false显式开关,Phase3默认false
- 场景YAML中
- ③ 统计计算引擎
- 已有:
mom_yoy(同环比)、anomaly_3sigma(异常检测)、rfm_score、abc_classification - 改进点:扩展统计摘要函数 ——
compute_data_summary()自动计算分布形态、分位数、变化贡献度,将raw rows转为洞察摘要
- 已有:
- ④ 客观置信度计算引擎(新增)
- 趋势置信度:Mann-Kendall检验 + Theil-Sen斜率估计
- 异常置信度:Grubbs检验 + 修正Z-score
- 差异显著性:Cohen"s d效应量 + 自助法置信区间
- ⑤ 智能数据闸门(新增)
- Layer 1(必入):统计摘要(趋势/分布/异常点/贡献度)
- Layer 2(尽力):代表性样本(P0/P25/P50/P75/P100 + Top-N变化点)
- Layer 3(按需):Agentic模式下LLM主动索取的详细数据
4.2 动态推理层(Heuristic Layer)
动态层的职责是:所有需要溯因推理、语境解读、策略生成的任务,均由LLM完成,但输入和输出均受精确层的事实约束。
- 输入约束(护栏入):
- 精确层产出的结构化数据作为LLM输入的“事实部分”
- Prompt中明确分离“事实陈述(不可质疑)”和“推理任务(需要你完成)”
- 注入的每条数据附带来源标注(来自哪个SQL步骤、哪个统计计算)
- 推理引擎:
- DeepSeek Reasoner(或其他推理增强模型),温度0.1-0.3
- 思维链逐步展开,每步引用具体数据
- 区分“强推断”和“弱推断”——有充分数据支撑的结论 vs. 基于经验的推测
- 输出约束(护栏出):
- 结构化XML输出(thinking / conclusion / recommendations / charts)
- 每条结论必须引用数据来源
- 双轨置信度:统计置信度(系统计算)+ LLM推理置信度(LLM自评,正则提取)
- Phase4 对话式探索:
- 用户自由提问 → 意图识别 → AI生成SQL(这里AI是必需的,因为问题空间开放)
- 仍需安全网:SQL校验 + 试运行 + fallback
- 场景化Agentic分步:LLM先看摘要 → 发现问题 → 主动索取细节 → 生成完整报告
4.3 护栏机制(Guardrail Layer)
护栏层是精确层和动态层之间的结构化接口协议。它的核心原则是:事实不可否认,推断需标注,来源可回溯,置信度双轨。
具体包括四条规则:
- 事实不可否认:Prompt中明确标注“以下数据是经数据库查询和统计计算的确定性事实,请勿质疑或忽略”
- 推断需标注:LLM需要在“这是事实”和“这是我的推断”之间做明确区分
- 来源可回溯:每条分析结论需追溯到具体的SQL步骤编号或统计指标
- 置信度双轨:统计置信度和LLM置信度分别标注,用户对两者的可靠性有清晰的认知
4.4 实施优先级
| 优先级 | 改进项 | 工作量 | 影响 |
|---|---|---|---|
| P0 | Phase3 SQL默认走fallback,加use_ai_sql开关 | 1天 | 消除最大幻觉源,延迟降低90% |
| P1 | 增加统计摘要层(扩展stats_engine) | 3-5天 | 解决数据截断问题,提升推理质量 |
| P2 | 双轨置信度引擎 | 3-5天 | 置信度从“修辞”升级为“度量” |
| P2 | 本体语义子图按相关性筛选注入 | 2-3天 | 提升LLM对本体信息的利用效率 |
| P3 | 智能数据闸门分层注入 | 5-7天 | 从“推”模式升级为“推+拉”模式 |
| P3 | Agentic多轮推理 | 7-10天 | LLM主动索取数据,降低单次Prompt的信息负载 |
图3:改进方案——精确层+护栏机制+动态层的融合推理架构

图4:推理空间对比——经典本体论 vs 本体驱动LLM混合推理

5. 核心结论
5.1 经典本体论与 LLM 不是替代关系,而是分层协作关系
经典本体论(OWL、SWRL、SHACL)的价值在于定义精确的语义边界:什么是有效的订单?GMV的计算口径是什么?退款率归属于哪个时间窗口?这些是公理化的、不可妥协的。规则引擎在这里是不可替代的。
但经典本体论的推理空间是封闭的——它只能在一个有限的公理集合内做演绎。真实商业分析需要在这个封闭空间之外进行溯因推理和策略生成,而这是LLM能做到、SWRL规则引擎永远做不到的。
5.2 “该精确的一定要精确”是系统设计的第一原则
任何输入确定、输出确定的任务——SQL生成、数据聚合、统计计算——都应该在确定性代码层完成。将这类任务交给LLM不是“智能化”,而是“概率化”——把一个100%可靠的操作降级为一个概率性的操作。当前代码中AI生成SQL作为Phase3默认路径,是这一原则被违反的典型案例。
5.3 AI 的重点不是“生成事实”,而是“解读事实”
LLM在分析系统中的正确位置是:接收确定性计算产生的结构化事实,结合本体模型定义的语义关系,进行溯因推理和策略生成。
精确层负责“是什么”(What happened),动态层负责“为什么”(Why it happened)和“怎么办”(What to do)。前者靠SQL和统计算法,后者靠LLM的语义理解能力。两者不能混淆,混淆的代价是:精确性丢失 + 成本增加 + 推理质量下降。
5.4 “推”模式应向“推+拉”模式演进

当前的数据注入是“推”模式——系统决定LLM应该看什么,然后一次性推过去。更先进的模式是“推+拉”——系统推送统计摘要(确保覆盖),LLM在推理过程中主动索取它认为关键的细节数据(确保深度)。
这种Agentic分步模式是将LLM从“被动阅读者”升级为“主动分析者”的关键一步,也是融合推理架构从Demo走向生产的关键进化路径。
5.5 一句话总结
本文基于 ecommerce-ontology-analytics 项目 v1.0 代码分析撰写。所有引用代码行号以分析时的版本为准。




