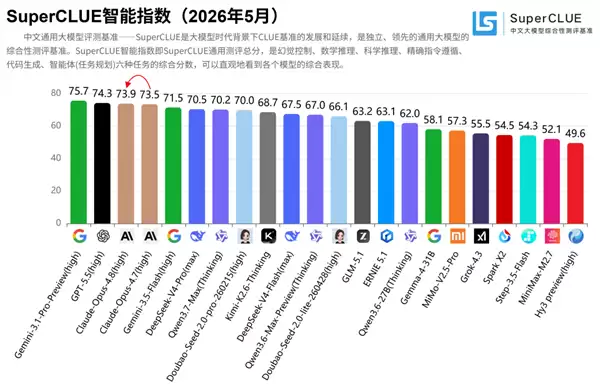
先聊聊我的观察——2026年5月30日,Anthropic于5月28日正式推出了其最新旗舰模型:Claude Opus 4.8。在中文综合评测中,这款大模型表现十分亮眼,尤其在代码生成、幻觉抑制和科学推理三个维度上,直接拿下全球第一的成绩。
从具体数据来看。在代码生成领域,Opus 4.8获得了83.58分,领先第二名超过2分,相比上一代4.7版本提升了4.5分以上。在软件工程相关的细分任务中,它的表现同样处于最优水平——独立完成编程和网页开发任务时,稳定性与性能均有肉眼可见的提升。
幻觉控制是另一个突出亮点。87.48分的成绩位居全球首位,相比前代提升了超过6分。模型编造信息的现象明显减少,输出内容更加严谨可靠。对专业应用场景而言,这种可信度的提升至关重要。
科学推理方面,Opus 4.8拿下77.19分,稳居全球榜首。与上一代相比,接近9分的增幅意味着它在理科计算和复杂逻辑推导方面的基础更加扎实。
综合智能指数73.93分,与GPT-5.5、Gemini 3.1 Pro Preview同属第一梯队。响应速度基本保持不变,API调用价格也未调整——整体定位依旧是高性能但单位算力成本相对较高的旗舰级产品。
当然,也需要客观看待。这一版本在智能体任务规划、数学推理和指令遵循三个指标上有所回落。指令遵循能力的下降较为明显,不过对日常交互使用的影响其实有限。
总的来说,Opus 4.8将火力集中在代码能力、事实准确性和科学推理上,对技术密集型用户而言是实实在在的提升。特别是开发者和科研工作者,应该能感受到这种“量身定制”的优化。就当前阶段而言,它是最综合能力最为均衡的旗舰级大模型之一。




