Composer 2.5 模型详解 Cursor推出的智能编程助手
在AI编程助手竞争日趋白热化的今天,Cursor刚刚投下了一枚颇具分量的“性价比冲击波”——Composer 2.5。这款自研的Agentic编程模型,不仅在核心基准测试中与Claude Opus 4.7、GPT-5.5等顶级选手站到了同一梯队,更关键的是,它将单次任务的成本直接拉低到了竞品的十分之一左右。这无疑给那些既追求顶尖智能,又对成本敏感的开发者和团队,提供了一个极具吸引力的新选择。
Composer 2.5是什么
简单来说,Composer 2.5是Cursor基于Moonshot开源的Kimi K2.5检查点进行持续训练后,推出的新一代自研智能编程模型。它的杀手锏非常明确:用极致的性价比,提供前沿的智能水平。
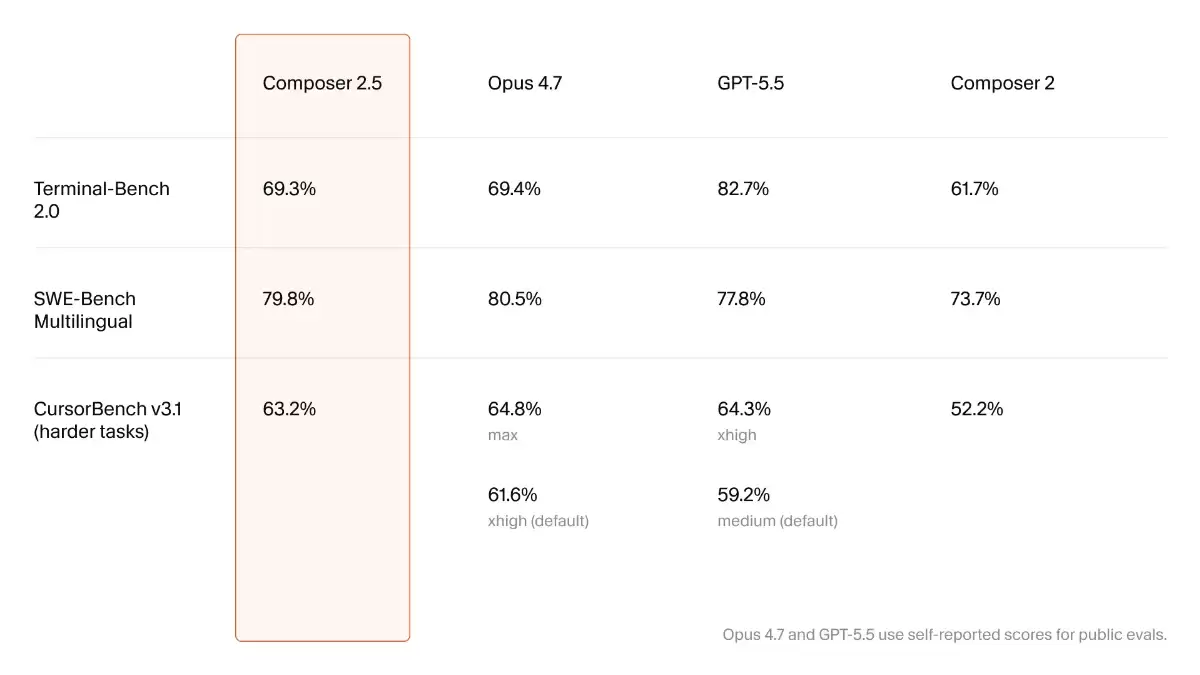
看看数据就明白了:在衡量多语言代码问题解决能力的SWE-Bench Multilingual上,它拿到了79.8%的分数;在Cursor自家更贴近真实开发难度的CursorBench v3.1上,也达到了63.2%。这两个成绩,已经让它稳稳进入了Claude Opus 4.7和GPT-5.5所在的“第一梯队”。但当你把目光移到价格标签上,差距就拉开了——完成类似复杂度的任务,Composer 2.5的成本大概只有那些旗舰模型的十分之一。这种“性能追平旗舰,价格降维打击”的策略,让它刚一发布,就赢得了“性价比之王”的称号。目前,它主要通过Cursor IDE及其SDK提供服务。
Composer 2.5的主要功能
除了基准分数,Composer 2.5在具体功能和行为层面也做了大量针对性优化,这些改进直接关乎实际使用的体验:
- 长时任务持续工作:针对需要长时间运行的Agent会话进行了深度优化。这意味着在进行多步骤的工具调用时,它能更好地保持“专注力”,显著减少了中途“开小差”(产生幻觉)或者“摆烂”提前终止任务的情况。
- 复杂指令可靠遵循:对于跨文件重构、执行终端命令、遵循测试驱动开发(TDD)流程这类复杂指令,其遵循的可靠性和准确性相比前代Composer 2有了大幅提升。
- 努力级别动态校准:这是一个很实用的改进。模型现在能自己判断任务难度,并动态分配“思考量”。简单任务快速过,复杂任务则投入更多“脑力”进行深度推理,有效避免了“杀鸡用牛刀”或“大事化小”的尴尬。
- 沟通风格优化:回复变得更加简洁和结构化,减少了那些不必要的、冗长的解释。特别是在处理多文件变更时,它能提供更清晰的推理过程,让开发者一目了然。
- 工具调用精准度提升:在调用终端命令或进行代码搜索时,无效操作和冗余动作显著减少,直接提升了编码和操作的效率。
- 双版本灵活适配:它提供了Standard(标准版)和Fast(快速版)两个版本,两者智能水平完全一致,只是速度和成本不同。Standard版适合后台批量任务,追求极致性价比;Fast版则针对交互式实时编程优化,响应更快,延迟更低。
如何使用Composer 2.5
想要体验这个“性价比之王”,方法并不复杂:
- 在 Cursor IDE 中启用:首先,确保你的Cursor IDE已经更新到2026年5月的最新稳定版。然后,打开Composer面板(快捷键
Cmd+I或Ctrl+I),在模型选择器中切换到 Composer 2.5 即可。 - 选择速度档位:对于日常的交互式开发,系统默认会使用响应更快的 Fast版。如果你需要运行后台Agent或处理批量任务,可以在Settings > Models中手动切换为成本更低的 Standard版。
- 通过 SDK 程序化调用:对于希望集成到自动化流程中的开发者,可以通过Cursor的SDK进行调用,灵活选择模型版本。
import { Agent } from "@cursor/sdk";
const agent = await Agent.create({
model: "composer-2.5", // Standard 版
// model: "composer-2.5-fast", // Fast 版
workspace: "./",
tools: ["edit", "shell", "search", "browser"],
});- 为长时任务设限:一个实用的建议是,对于无人看管的长时间Agent会话,最好提前设置迭代次数上限和最大耗时。这能防止模型为了快速完成任务而利用一些“捷径”进行奖励作弊,确保输出质量。
- 善用多模型路由:虽然Composer 2.5能力全面,但最经济的用法依然是“让专业的模型做专业的事”。可以将90%的日常开发任务交给它处理,而将极少数特定任务(比如复杂的架构评审)路由给更擅长的Claude Opus 4.7,或将重度依赖终端Shell的任务交给GPT-5.5。
Composer 2.5的核心优势
总结来看,Composer 2.5的吸引力集中在以下几点:
- 极致性价比:这是最核心的优势。Standard版输入$0.50/M、输出$2.50/M,Fast版输入$3.00/M、输出$15.00/M。相比Claude Opus 4.7,其单任务成本便宜了大约10到30倍,这种价格优势在规模化使用时将非常惊人。
- 前沿级基准表现:在SWE-Bench Multilingual和CursorBench v3.1等关键基准上,其成绩与Opus 4.7、GPT-5.5互有胜负,整体处于同一水平线,证明了其硬实力。
- 行为层面深度优化:它不仅是在模型规模上做文章,更在沟通风格、努力程度校准这些直接影响开发者体验的“软实力”上下了功夫。这些改进很难完全体现在冷冰冰的基准分数里,但却能让日常使用变得舒心很多。
- 双版本灵活选择:Standard和Fast的双版本策略,让用户可以根据任务类型(批量后台 vs. 实时交互)在成本和速度之间做最优选择,无需为不需要的性能付费。
Composer 2.5的同类竞品对比
| 对比维度 | Composer 2.5 | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|
| 厂商 / 平台 | Cursor | Anthropic | OpenAI |
| 产品定位 | 自研 Agentic 编程模型 | 旗舰推理模型 | 旗舰多模态模型 |
| 基座模型 | Moonshot Kimi K2.5(开源检查点持续训练) | Claude 4 系列 | GPT-5 系列 |
| 发布日期 | 2026.05.18 | 2026 年 Q2 | 2026 年 Q2 |
| SWE-Bench Multilingual | 79.8% | 80.5% | 77.8% |
| Terminal-Bench 2.0 | 69.3% | 69.4% | 82.7% |
| CursorBench v3.1(困难任务) | 63.2% | 64.8%(max)/ 61.6%(默认 xhigh) | 64.3%(xhigh)/ 59.2%(默认 medium) |
| 输入价格(/M tokens) | $0.50(Standard) $3.00(Fast) |
未公开(行业参考约 $15) | 未公开(行业参考约 $3–$5) |
| 输出价格(/M tokens) | $2.50(Standard) $15.00(Fast) |
未公开(行业参考约 $75) | 未公开(行业参考约 $15–$30) |
| 单次任务相对成本 | 基准(约 $1–$2 / 任务) | 约 10–30 倍 | 约 3–10 倍 |
| 上下文窗口 | ~200K(参考 Kimi K2.5) | 200K | 128K–1M |
| 权重开放性 | 闭源(仅 Cursor 基础设施) | 闭源 | 闭源 |
| 接入方式 | Cursor IDE / CLI / @cursor/sdk |
API / Claude Code / 第三方平台 | API / ChatGPT / GitHub Copilot |
从对比中能清晰看到,Composer 2.5在核心编程基准上已具备与顶级模型掰手腕的能力,而在价格维度上则形成了压倒性优势。GPT-5.5在终端任务(Terminal-Bench)上依然保持领先,但考虑到巨大的价差,Composer 2.5的性价比策略显得非常精准。
Composer 2.5的应用场景
基于其能力和成本特点,以下几个场景尤其适合使用Composer 2.5:
- 多文件级重构:在需要跨多个文件进行代码迁移或大规模重构时,其成本优势极为明显,且精度足以媲美前沿模型。
- 交互式结对编程:使用Fast版本,在IDE中可以获得响应迅速的实时辅助,提升编码流畅度。
- 后台定时任务/云Agent:Standard版本是处理批量代码审查、自动修复等后台任务的绝佳选择,能以极低的成本完成大量工作。
- 测试驱动开发:其长时任务可靠性的提升,使得它能够更稳定地执行“编写测试-运行-修复”的多轮循环。
- 复杂终端自动化:虽然在重度Shell场景下(Terminal-Bench 2.0得分69.3%)略逊于GPT-5.5(82.7%),但与Opus 4.7持平,足以应对大多数自动化需求。
总而言之,Composer 2.5的登场,标志着AI编程助手市场进入了一个新的阶段:竞争焦点从单纯的“性能竞赛”,开始向“性能与成本的综合平衡”倾斜。对于广大开发者而言,这无疑是一个好消息。
相关攻略

Cursor推出自研Agentic编程模型Composer2 5,在核心基准测试中性能与ClaudeOpus4 7、GPT-5 5相当,但单次任务成本仅为竞品的十分之一左右。它提供标准版和快速版,针对长时任务、复杂指令遵循等进行了优化,并通过CursorIDE及SDK提供服务,以极致性价比为开发者提供了新选择。

今天,AI编程领域迎来了一次震撼性的重大突破。Cursor,这个赛道中的核心竞争者,正式发布了其全面升级的AI编程模型——Composer 2 5。 权威基准测试结果显示,Composer 2 5在多项编程基准测试中的表现,已经直逼Claude 4 7 Opus和GPT-5 5等顶级模型。 这不仅仅

全球AI竞赛如火如荼,所有技术投入的最终目标都高度一致:那就是切实提升社会生产力与商业效率。 直面竞争现实,不容丝毫松懈 2026年清明节期间,阿里通义千问Qwen3 6-Plus模型登顶全球AI平台OpenRouter日榜榜首并刷新调用记录的消息,引发了行业广泛关注。 如果将时间线拉长,观察阿里近

随着“氛围编程”(Vibe Coding)理念的兴起,软件开发的核心范式正经历深刻变革,从传统的“程序员编写代码”转向“人类指挥AI智能体协同编码”。以Claude Code、OpenClaw为代表的先进系统,已经能够驱动智能体自主完成从编码、调试到完整任务执行的全流程。然而,当面对系统级工程开发或

谷歌DeepMind今天扔下了一颗重磅冲击波:正式开源发布Gemma 4系列模型。根据官方说法,这是谷歌迄今为止最智能的开放模型,专为高级推理和智能体工作流而生。最引人注目的是,它号称实现了“单位参数下前所未有的智能水平”——换句话说,就是用更小的模型体量,干出更聪明的活儿。 先看几个硬核数据:其3
热门专题







热门推荐

IDC报告显示,商汤“万象”平台以11 3%份额位居中国大模型私有化市场第二。平台通过一站式模型服务、全生命周期专家支持及低代码工具链,满足企业安全、性能与成本需求,推动AI在政务、交通、能源等行业落地,降低技术门槛,加速价值实现。

市场上有多种高效AI工具可供选择。WPSAI能智能处理文档,Grammarly辅助写作纠错,AIPPT工具快速生成演示文稿,ChatGPT进行对话与创作,DeepL提供精准翻译。CanvaAI助力设计,GitHubCopilot和TabNine提升编程效率,AI去背工具简化图像编辑。这些工具覆盖写作、设计、编程等场景,能显著提升工作效率。

BitgetAI负责人Bill博士指出,AI在交易平台中已能高效整合信息、辅助决策,提升效率。当前产品注重个性化建议与安全易用的交互,如通过Telegram提供自然对话辅助。AI虽无法完全替代顶尖交易员,但其价值在于赋能用户、优化流程。未来竞争关键将在于安全体系、成本控制及持续学习用户习惯的能力。

2024年,AI工具正深度融入工作流程,提升效率与创意。WPSAI集成于办公软件,助力文档创作与优化;ChatGPT作为多功能对话模型,辅助编程与文案;GoogleBard擅长信息整合与自然对话;BoardMix结合白板与AI,可生成思维导图等可视化内容;NewBing融合搜索与对话,兼具创意与可信来源;NotionAI能自动处理会议纪要等文本任务;Gram

代币化美股热度上升,投资者可通过区块链交易相关资产,挑战传统券商模式。其优势包括降低门槛、提升流动性和全天候交易,但也面临监管不明确等风险。未来能否颠覆传统金融,取决于技术发展与合规进程。