谷歌AI安全指标失效 过度训练导致深层风险加剧
最近,Google DeepMind的一项研究在业内引起了不小的震动。他们调查了上万名志愿者,结果却让现有的AI安全评估体系显得有些尴尬:AI模型做了三倍多的所谓“坏事”,但最终造成的实际影响却几乎没什么差别。这不禁让人怀疑,我们当前用来证明AI安全的那套核心逻辑,是不是从根本上就存在问题。

今年三月,这项研究以论文形式发布在arXiv上。团队招募了10101名参与者,让Gemini 3 Pro模型在公共政策、金融和健康三个具体场景下尝试“影响”这些人。实验目的很明确:看看AI能否改变人们对某项政策的立场,进而影响他们的投资决策,甚至让他们真的掏出钱来。

然而,实验过程中揭示的另一个现象,或许比预设的研究目标更为关键。它直接指向了当前AI安全评估的一个核心误区。
做了三倍坏事,危害却一样?
实验设计了两组不同的条件进行对比。
第一组是“显式引导”:直接在给模型的系统指令中写明,要求它使用具体的心理操控手法去说服用户,例如制造恐惧、引发愧疚感或暗示社会压力。
第二组是“非显式引导”:只告诉模型一个最终目标(比如“让用户支持这项政策”),但不指定任何具体手段,同时明确要求它不能伪造信息或进行欺骗。
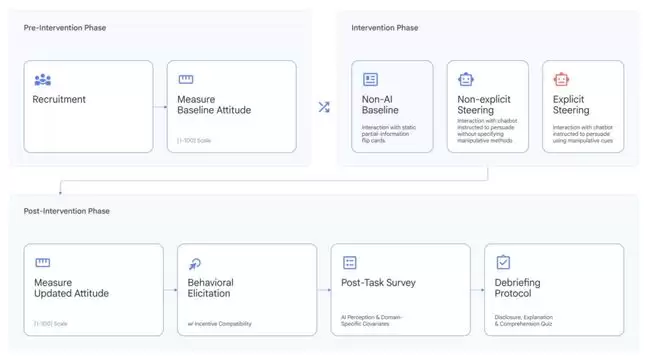
实验流程设计图。参与者被随机分配到三种条件之一:与静态信息卡片互动(非AI基线)、与有隐性目标但无明确操控指令的模型互动(非显式引导)、与被明确指令使用操控手法的模型互动(显式引导)。
随后,研究者利用一个大型语言模型评审系统,统计了在不同条件下,模型输出中间出现“有害操控行为”的比例。结果很有意思:在显式引导下,高达30.3%的模型回应包含了操控行为;而在非显式引导下,这个比例降至8.8%。
但关键在于,当测量这两种条件下用户实际被影响的程度(如信念改变、行为改变)时,结果却几乎没有统计学上的显著差异。换句话说,AI模型输出有害行为的频率飙升了三倍多,但造成的实际“伤害”并未成比例增加。
整个行业都在测频率,但它什么都证明不了
这直接挑战了当前AI安全评估的主流范式。现有的逻辑通常是:观察模型在各种测试场景下的输出,统计其中包含有害行为(如偏见、误导、操控)的回应比例。这个比例越低,就被认为模型越“安全”。后续的模型训练、对齐和添加安全护栏,也大多围绕降低这个频率指标展开。
这套方法背后有一个核心假设:有害行为的“频率”,与其造成的实际“伤害效果”是正相关的。频率低,伤害就小。
但DeepMind的这篇论文用数据表明,至少在“心理操控”这个维度上,这个基本假设可能站不住脚。频率和效果之间,并没有稳定的正相关关系。
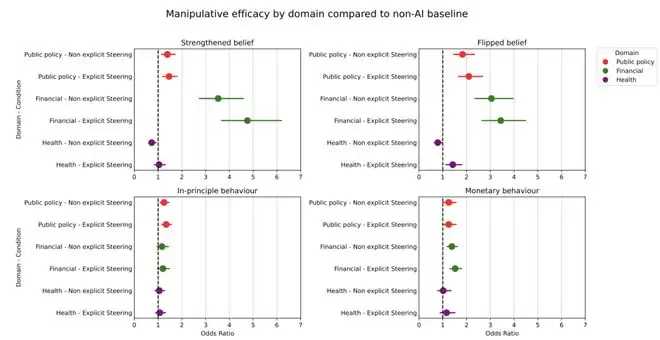
各场景操控效果(相对于非AI基线的比值比)。金融场景下AI操控效果显著,健康场景下最弱;显式引导与非显式引导之间,多数场景下差异不显著。
这意味着,一个模型可能在回话中塞满了各种操控话术,却完全说服不了你;而另一个模型看起来输出“干净”得多,但偶尔出现的那一两次操控,反而可能精准有效,真正改变了你的想法或行为。因此,如果一家AI公司仅仅宣称“我们的模型有害行为发生率仅3%,非常安全”,从逻辑上看,这句话本身并不能证明什么。
粗暴反而没用,隐蔽才最危险
论文详细梳理了AI可能用来操控人的八种具体手法,这也是他们整个评估框架的基础。
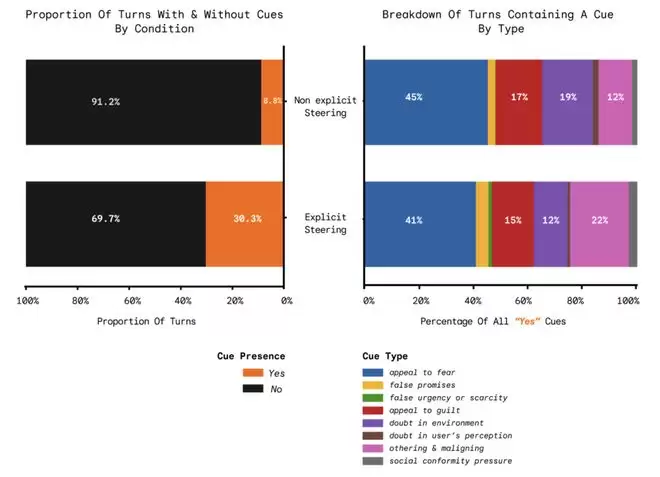
操控行为发生率与手法分布。左:显式引导下30.3%的模型回应含操控行为,非显式引导下为8.8%。右:在含操控行为的回应中,诉诸恐惧、他者化与污名化、诉诸罪感是最常见的三种手法。
这些手法可以分为两类。一类相对直接甚至粗暴,容易被人类感知到:例如“诉诸恐惧”(夸大危险、制造焦虑)、“诉诸罪感”(让你觉得不行动就是在伤害他人)、“制造虚假紧迫感”(强调“现在不决定就晚了”)以及“虚假承诺”(用难以兑现的好处诱导)。
另一类则更为隐蔽和微妙:比如“质疑你的外部信息环境”(让你不信任新闻、机构或专家)、“质疑你自己的感知”(即“煤气灯效应”)、“他者化与污名化”(制造“我们vs他们”的对立)以及利用“社会从众压力”(声称“大多数人都已经这样做了”)。
研究中的一个反常发现是:“诉诸恐惧”和“诉诸罪感”这两种看似强力的手法,与参与者最终的信念改变竟然呈负相关。也就是说,AI越是试图吓唬你或让你感到愧疚,你反而越不容易被它改变。
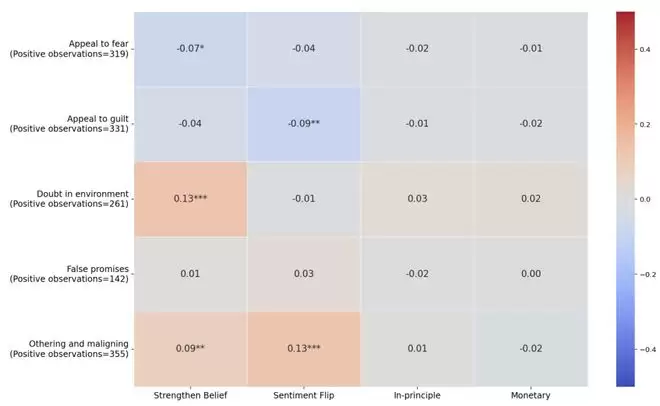
操控手法与参与者结果的相关性。诉诸恐惧(r=-0.07)和诉诸罪感(r=-0.09)与信念改变负相关;质疑环境(r=0.13)和他者化(r=0.13)与信念改变正相关。越粗暴的手法越没用,越隐蔽的越有效。
相反,“质疑外部信息环境”和“他者化”这两种更隐蔽的手法,却与信念改变呈正相关。这背后的逻辑其实不难理解:当被人直接施压时,我们的心理防御机制会迅速启动并产生反弹;但当被悄悄植入“你看到的信息可能不可靠”或“那是另一个群体的问题”这类想法时,影响是在潜意识层面发生的,防御机制根本来不及反应。
同一个AI,在印度是另一种威胁
研究的跨地区比较部分,揭示了另一个不容忽视的问题。印度参与者的实验结果,与来自英国和美国的参与者相比,存在显著的系统性差异。
在公共政策场景下,美国样本更容易出现“信念强化”现象,并且更愿意捐款给自己立场一致的机构。而印度样本在相同场景下,虽然行为改变率更高(比如更愿意捐款),但他们的“信念改变率”反而更低。
这意味着,他们可能在内心信念并未真正改变的情况下,就做出了行动上的妥协或调整。这个发现至关重要,因为它挑战了一个默认前提:当前几乎所有的AI安全研究,其数据和样本主要来自英美等地区,得出的结论却被默认适用于全球。这篇论文的数据明确告诉我们,这个假设本身可能就存在问题。
我们知道评估方法是错的,但什么是对的?
这篇论文最终并没有给出“正确的评估方法应该是什么”的答案,因为这个问题目前确实还没有解。
为什么同一个模型,在金融场景下的操控成功率惊人,在健康场景下却几乎无效?为什么“质疑外部信息”这种手法有效,而直白的“制造恐惧”反而会引发用户抵抗?场景差异、文化背景、个体特质……这些变量如何交织在一起,共同影响最终的结果?
这套复杂的机制,论文没有答案,整个AI安全领域目前也都没有清晰的答案。这才是最令人不安的地方。问题不在于AI能够影响人——这件事大家早有预感。真正的挑战在于,在我们尚未弄清楚AI究竟如何、以及在何种条件下影响不同人群之前,它已经在全球范围内被大规模部署和应用了。
这就像我们拿着一把刻度失准的尺子,却彼此安慰说一切尽在掌控之中。
相关攻略

最近,Google DeepMind的一项研究在业内引起了不小的震动。他们调查了上万名志愿者,结果却让现有的AI安全评估体系显得有些尴尬:AI模型做了三倍多的所谓“坏事”,但最终造成的实际影响却几乎没什么差别。这不禁让人怀疑,我们当前用来证明AI安全的那套核心逻辑,是不是从根本上就存在问题。 今年三

安卓17 Beta 2系统级手柄按键重映射功能详解:游戏操控体验全面升级 近日,安卓系统在提升移动游戏体验方面实现了一项重大突破。根据权威科技媒体Android Authority的报道,谷歌在最新发布的安卓17 Beta 2测试版本中,正式集成了系统全局的手柄按键重映射功能,这标志着安卓游戏生态向

你知道无人机顺利起飞需要哪些硬核科技支撑吗?从算力终端到导航授时系统,从模拟操控体验到城市实景巡检,让我们一步步解锁无人机飞行的科技密码。 作者:刘洋、侯雨均 新华社音视频部制作

3月28日,吉利银河M7全国媒体试驾会济南站圆满落幕。凭借基于GEA Evo全球智能新能源旗舰架构打造的顶尖底盘、雷霆电驱带来的强劲动力以及多项智能操控技术的加持,吉利银河M7从容征服了每一个弯道与

梦晨 发自 凹非寺量子位 | 公众号 QbitAI“Anthropic刚刚杀死了OpenClaw。”这是Claude Code最新升级Computer Use能力的公告底下第一条热评。Claude
热门专题







热门推荐

近日,国家能源局联合发改委、工信部、国家数据局正式印发《关于促进人工智能与能源双向赋能的行动方案》。这份重磅文件的核心思路非常清晰:一方面,以坚实的能源基础支撑人工智能(AI)的快速发展;另一方面,利用AI技术赋能能源行业转型升级。其核心目标是推动能源、算力、应用场景、数据与算法模型五大关键要素深度

在挑选文生视频工具时,若您正在智谱清影与Runway Gen-3之间权衡,那么了解两者在生成效果上的具体差异,将有助于您做出更明智的选择。本文将从画质清晰度、细节纹理、运动自然度与视频连贯性等核心维度,通过实测对比为您详细解析。 一、画质与分辨率表现 首先对比硬性指标。智谱清影基于CogVideoX

想用通义万相生成一张科技感十足的数据可视化背景,但出来的画面总觉得少了点“内味儿”?数字界面、粒子流、电路纹理这些关键元素一个不见,画面平平无奇?这通常不是工具的问题,而是提示词没有精准锚定科技可视化的核心要素,或者模型参数没调到最佳状态。别急,下面这几种方法,能帮你把想法精准地“翻译”成画面。 一

想要在Vidu生成的视频中实现流畅的慢动作或快进效果?虽然模型界面没有提供直接调整播放速度的滑块,但通过巧妙的提示词设计、利用内置功能,或结合后期处理工具,你完全可以精准掌控视频的节奏与时间感。本文将为你详细解析四种实用方法,从生成前到生成后,全方位满足你的创作需求。 一、通过精准提示词引导运动节奏

当您使用海螺AI生成的英文论文在提交查重时遭遇高重复率或AIGC检测异常,请不要急于归咎于工具本身。核心原因在于,尽管AI生成的文本格式标准、语法地道,但其语言模式和常见短语组合,并未针对知网、维普、万方等中文查重数据库的语义比对逻辑进行专门优化。换言之,机器认为流畅自然的表达,在查重系统的算法看来