开源框架全天候自动运行实验每日成本仅五毛钱
对于从事深度学习研究的科研人员来说,这样的工作场景一定非常熟悉:调整超参数,提交训练任务,等待数小时甚至数天,查看实验结果,不满意再重新调整,如此循环往复。在项目截止日期临近时,这样的实验循环可能需要进行上百次。甚至需要半夜设置闹钟,醒来查看损失曲线是否按预期下降——下降了,才能安心继续睡;没下降,就只能强打精神修改代码,提交新一轮实验。
最令人感到疲惫的往往不是工作本身的强度,而是其高度重复和机械化的本质:实验方案早已构思完成,剩下的只是将其转化为代码并等待运行结果。这部分宝贵的时间,本应投入到更具创造性的科学思考与问题分析中。
那么,是否存在一种可能,让一个AI智能体(Agent)来自动化地完成这部分实验执行与管理工作呢?
近期,GitHub上出现了一个名为“Deep Researcher Agent”的开源AI科研框架,正是为了回答这个问题而生。它的核心价值在于实现科研流程的自动化:当你休息时,它在自动进行实验迭代;当你需要撰写论文时,它已经将整理好的实验结果与对比表格准备完毕。
Deep Researcher Agent 的工作原理是什么?
该框架的核心,是一个高度自主的“思考(THINK)→ 执行(EXECUTE)→ 监控(MONITOR)→ 反思(REFLECT)”循环系统。
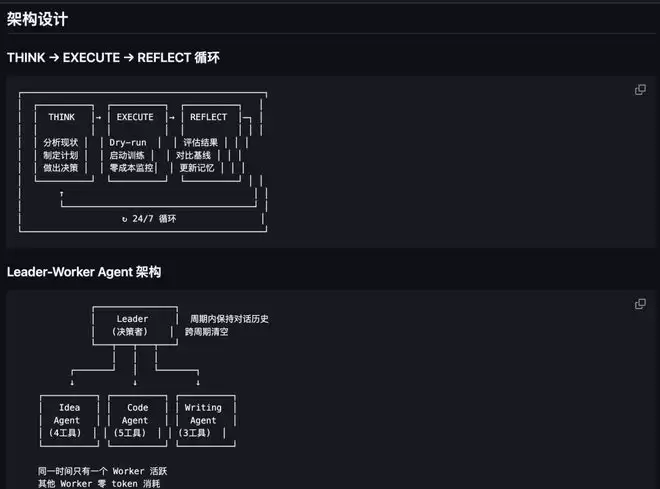
THINK(思考与规划):智能体读取项目研究目标与过往实验记忆,分析当前最佳结果,并智能决策下一步的优化方向。值得注意的是,它的决策维度非常广泛,不仅能调整学习率、批次大小等超参数,还可以修改神经网络模型架构、更换损失函数、或增加新的数据增强策略。
EXECUTE(代码执行与任务启动):智能体自动修改项目代码或配置文件,并会先进行一次强制性的“干运行”(Dry Run),仅执行少量前向和反向传播以验证代码无语法或逻辑错误,确认无误后才将完整的训练任务提交到GPU集群。
MONITOR(零成本训练监控):这是整个框架设计中最为精妙的一环。在模型训练期间,智能体完全不调用任何大型语言模型(LLM)的API,从而实现了监控阶段的零额外计算成本。它仅执行几个轻量级的系统操作:检查训练进程是否存活、监控GPU利用率是否正常、以及实时追踪日志文件的最新输出内容。
REFLECT(结果分析与迭代决策):训练任务结束后,智能体自动解析日志文件、提取准确率、损失值等关键性能指标、与历史最优结果进行对比分析、记录重要里程碑,然后自动开启下一轮实验循环。整个过程可以7×24小时不间断运行。研究者若想中途介入或调整方向,只需在项目指定目录中放入一个简单的指令文件,智能体便会在下一轮循环开始时读取并执行。
每日运行成本仅约0.5元,是如何做到的?
让一个由大语言模型驱动的AI智能体全天候运行,听起来似乎成本不菲?其关键在于上述提到的“零成本监控”机制。

在一天24小时中,超过90%的时间都消耗在模型训练上,而这段时间的LLM API调用成本为零。只有在循环开始时的“思考”阶段和结束时的“反思”阶段才需要调用大模型进行推理,每次仅需数分钟。经过折算,日均运行成本可以控制在极低的水平。

这意味着,让智能体连续自动运行一周的总开销,可能比购买一杯咖啡还要便宜,极大地降低了AI科研自动化的门槛。
长期运行内存不膨胀:创新的两层“恒定记忆”系统
长时间自主运行的AI智能体常面临一个经典难题:上下文记忆随着实验次数不断累积,导致运行速度变慢、API成本增加且决策效率降低。Deep Researcher Agent 的解决方案是设计了一个高效的两层记忆系统:
第一层是由研究者编写的、固定不变的项目说明文档(约3000字符),用于明确告知智能体研究目标、可用数据和约束条件。
第二层是智能体自行维护的滚动式实验日志,关键实验结果会被自动总结并压缩至1200字符以内,且系统仅保留最近15条核心决策记录。
通过这种设计,智能体工作时的总上下文记忆量被恒定地维持在大约5000字符。无论是运行1天还是6个月,其内存占用和API调用成本都基本保持稳定,确保了长期运行的可行性。
并非演示原型,而是经过实战检验的科研工具
该框架并非停留在论文或概念演示阶段。它已在多个真实的深度学习研究项目中连续运行超过30天,取得了多项实质性成果:自主完成了超过500轮实验循环,将某个图像分类项目的关键指标(如Top-1准确率)相较于基线模型提升了52%(这是经过200多次全自动实验迭代优化的结果),同时能够并行管理4个独立研究项目与4台GPU服务器。在长达30多天的持续运行中,人类研究者仅介入了五六次进行方向性指导。
兼容Claude与GPT系列,一行配置即可切换模型
框架设计灵活,不绑定单一的大语言模型后端,支持主流模型切换:
- Anthropic系列:可选用 Claude Sonnet(平衡速度与成本)或 Claude Opus(追求最强推理性能)。
- OpenAI系列:可选用 Codex(速度优先)或 GPT-4系列(性能最强)。
用户只需修改配置文件中的一行模型名称,即可在不同的大语言模型之间快速切换,灵活选择最适合当前项目需求和预算的工具。
移动端实时监控:随时随地管理AI实验进程
配合专用的Happy Coder移动应用程序(支持iOS与Android),研究者可以在手机上实时查看所有实验的进度曲线、接收训练完成或出现错误的即时推送通知,并随时向智能体下达新的文本指令(如“暂停当前实验”、“尝试使用ResNet-50架构”)。所有通信均采用端到端加密,确保实验代码与数据结果的私密性与安全性。这真正实现了研究者在地铁通勤、咖啡馆休息或居家办公时,就能远程指挥和管理一整套深度学习实验流水线。
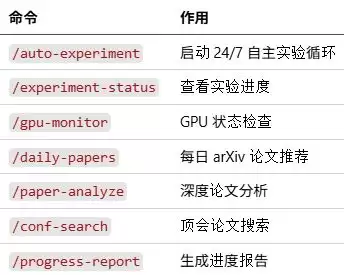
简易安装与七个核心斜杠命令
安装部署过程非常简单:克隆项目GitHub仓库后,运行一条标准的安装命令,即可获得7个针对Claude或Codex优化的斜杠命令(Slash Commands),覆盖从环境配置、启动实验到进度监控的全流程。
对于完全的新手用户,仓库中提供了一个极其详细的交互式指南文件。只需将该文件的内容复制给任何AI聊天助手(如ChatGPT),它便能以问答的方式,一步步引导你完成所有安装步骤,并成功启动第一个自动化实验。
与现有AI科研辅助工具的对比分析
目前主流的AI研究辅助工具,如Claude Scholar、AI Scientist、SWE-Agent等,其主要功能集中在辅助文献阅读、论文写作或代码片段生成上。但市场上尚缺乏一个能够真正替代研究者,端到端地执行并管理整个复杂实验流程的自动化工具。
Deep Researcher Agent 是首个专门为“运行”和“优化”深度学习实验而设计的开源智能体框架,其定位是实验执行者与管理员,而不仅仅是写作或编程助手。
重要的项目声明与科研伦理
项目作者在README中附上了一段严肃的声明,其意义或许超越了工具本身的技术价值:
本项目严禁用于任何形式的学术造假与科研不端行为。
开发这个自动化框架的唯一目的,是将深度学习研究过程中那些机械、重复、耗时的实验执行环节从研究者身上剥离,让大家能把节省下来的宝贵时间与认知资源,投入到真正重要的核心工作——科学思考与创新上去。
研究思路(Research Idea)与科学问题必须由人来提出。请不要期望利用本项目进行自动“炼丹”或学术不端,这既非项目的开发初衷,也违背了开源社区的科研精神。
学术研究应当保持其纯粹性与严肃性。AI智能体可以替你运行实验、调参优化,但研究思路的提出、学术价值的判断与研究责任的承担必须由人来完成。我们真诚希望每一位使用者都能以“人在回路”(Human-in-the-loop)的方式运用本工具,在自己的研究方向上做出真实、有价值、可复现的贡献。
在这个“AI一键生成论文”概念流行的时代,看到开源作者主动为自己的工具设定如此清晰的伦理边界,是令人触动且值得尊敬的。技术工具本身或许是中立的,但开发者的立场与倡导的价值观可以且应当鲜明。
归根结底,研究者的精力与时间是有限的。理应将时间花费在阅读前沿文献、构思创新点子、深度解读实验结果上,而不是消耗在凌晨三点反复查看损失曲线、手动提交任务的重复劳动中。Deep Researcher Agent 试图实现的愿景,正是将后者交还给机器自动化,而将前者——科学的灵魂与创造力——留给人。
相关攻略

在光学字符识别(OCR)技术的快速发展进程中,深度学习模型已成为推动其性能飞跃的核心引擎。这些先进的算法不仅大幅提升了文字识别的准确度,更让系统具备了强大的环境适应能力——无论是光线昏暗、字体多变还是背景复杂的图片,都能实现精准解析。可以说,深度学习的引入,真正推动了OCR技术从理论走向大规模商业化

在Linux系统上部署TensorFlow GPU版本时,许多开发者第一步就会遇到障碍。你以为执行conda install tensorflow-gpu就能轻松完成,实际运行时却频繁出现libcudart so not found或Failed to get device properties等错

你是否曾好奇,计算机如何从一张高分辨率的卫星或航拍图像中,精准识别出数十甚至上百个不同目标?这些目标朝向各异、尺寸悬殊,背景更是复杂多变。面对这一挑战,RetinaNet深度学习模型给出了卓越答案——它首次让单阶段目标检测器在精度上超越了传统的两阶段方法,成为航空影像智能解译的关键利器。 DOTA数

人工智能领域迎来重大突破,一项关于“深度学习文本机器人训练方法与系统”的研究取得了实质性进展。这项研究并非简单的功能迭代,而是致力于解决人机交互的核心痛点——如何让AI对话更自然、更智能,从而显著提升用户体验。 该研究的核心目标,在于利用深度学习技术彻底革新传统文本机器人的训练模式。过去,聊天机器人

近期,一项由马克斯·普朗克智能系统研究所主导、联合欧洲多所顶尖学术机构共同完成的研究,在人工智能领域引发了广泛关注。这篇发布于arXiv平台、编号为2603 15389v1的预印本论文,精准地指出了当前大语言模型(LLM)规模化发展中的一个核心瓶颈,并提出了一套兼具理论深度与实用价值的创新解决方案。
热门专题







热门推荐

近日,国家能源局联合发改委、工信部、国家数据局正式印发《关于促进人工智能与能源双向赋能的行动方案》。这份重磅文件的核心思路非常清晰:一方面,以坚实的能源基础支撑人工智能(AI)的快速发展;另一方面,利用AI技术赋能能源行业转型升级。其核心目标是推动能源、算力、应用场景、数据与算法模型五大关键要素深度

在挑选文生视频工具时,若您正在智谱清影与Runway Gen-3之间权衡,那么了解两者在生成效果上的具体差异,将有助于您做出更明智的选择。本文将从画质清晰度、细节纹理、运动自然度与视频连贯性等核心维度,通过实测对比为您详细解析。 一、画质与分辨率表现 首先对比硬性指标。智谱清影基于CogVideoX

想用通义万相生成一张科技感十足的数据可视化背景,但出来的画面总觉得少了点“内味儿”?数字界面、粒子流、电路纹理这些关键元素一个不见,画面平平无奇?这通常不是工具的问题,而是提示词没有精准锚定科技可视化的核心要素,或者模型参数没调到最佳状态。别急,下面这几种方法,能帮你把想法精准地“翻译”成画面。 一

想要在Vidu生成的视频中实现流畅的慢动作或快进效果?虽然模型界面没有提供直接调整播放速度的滑块,但通过巧妙的提示词设计、利用内置功能,或结合后期处理工具,你完全可以精准掌控视频的节奏与时间感。本文将为你详细解析四种实用方法,从生成前到生成后,全方位满足你的创作需求。 一、通过精准提示词引导运动节奏

当您使用海螺AI生成的英文论文在提交查重时遭遇高重复率或AIGC检测异常,请不要急于归咎于工具本身。核心原因在于,尽管AI生成的文本格式标准、语法地道,但其语言模式和常见短语组合,并未针对知网、维普、万方等中文查重数据库的语义比对逻辑进行专门优化。换言之,机器认为流畅自然的表达,在查重系统的算法看来