在光学字符识别(OCR)技术的快速发展进程中,深度学习模型已成为推动其性能飞跃的核心引擎。这些先进的算法不仅大幅提升了文字识别的准确度,更让系统具备了强大的环境适应能力——无论是光线昏暗、字体多变还是背景复杂的图片,都能实现精准解析。可以说,深度学习的引入,真正推动了OCR技术从理论走向大规模商业化应用。

那么,当前主流的OCR系统背后,究竟依赖哪些关键的深度学习模型架构呢?本文将为您详细解析几种核心的OCR深度学习模型。
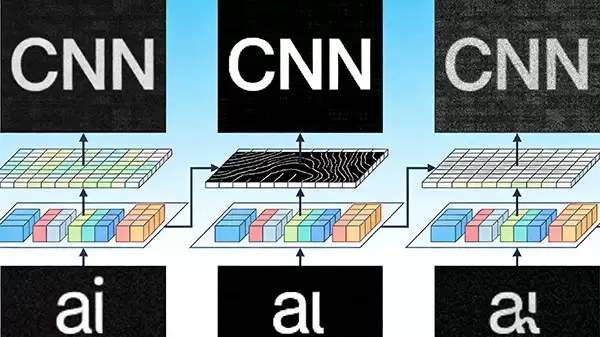
卷积神经网络(CNN)
在图像识别与处理领域,卷积神经网络(CNN)无疑是基础且关键的模型。在OCR技术中,CNN扮演着“特征提取器”的角色。它通过多层的卷积与池化运算,自动从图像像素中学习并捕获边缘、纹理、笔画等底层视觉特征,并将其逐步组合为更高层次的语义特征。这种强大的视觉表征能力,为后续的字符分类与识别奠定了坚实基础。
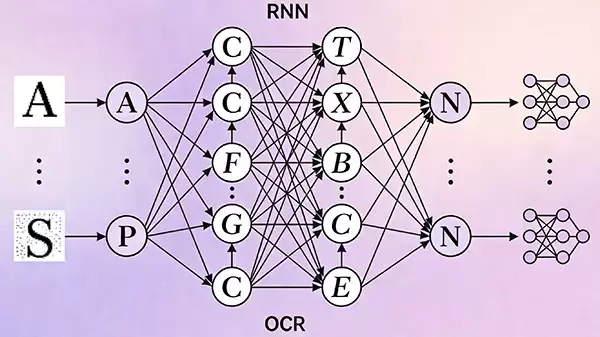
循环神经网络(RNN)
文本本质上是具有前后关联的序列数据,而循环神经网络(RNN)正是为序列建模而设计的。在OCR流程中,RNN能够将识别出的字符视为一个时间序列,并利用其内部的循环连接传递上下文信息。例如,当识别出“中”字后,模型会基于此记忆,更准确地预测后续可能出现的“文”、“国”等关联字符,从而提升整行文本的识别连贯性与正确率。
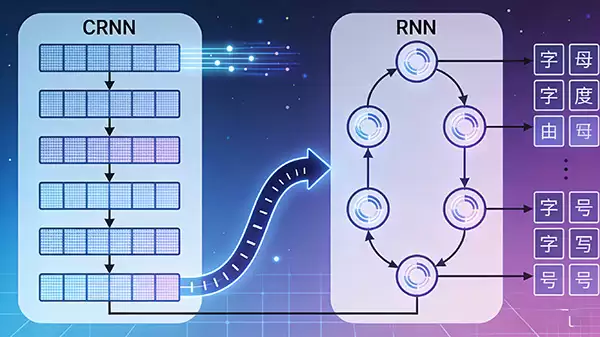
卷积循环神经网络(CRNN)
既然CNN精于图像特征抽取,RNN擅长序列上下文理解,将二者结合的卷积循环神经网络(CRNN)便成为OCR任务中的经典架构。CRNN通常先利用CNN网络提取图像的特征图并将其转换为特征序列,再由RNN(常用LSTM或GRU)对该序列进行上下文编码,最终通过转录层输出文本行识别结果。这种端到端的模型设计,有效融合了视觉与序列信息,在场景文字识别中表现卓越。
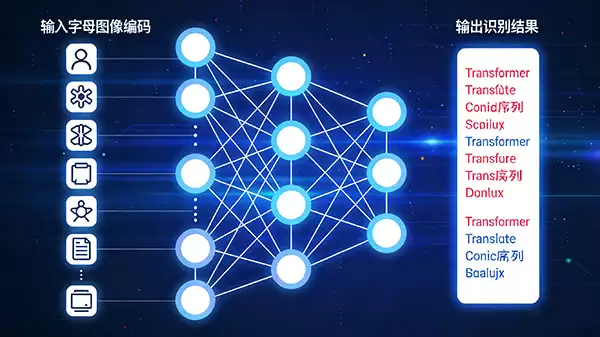
Transformer模型
近年来,基于自注意力机制的Transformer模型在自然语言处理领域取得突破后,也被成功引入OCR任务。与RNN不同,Transformer完全依赖注意力机制来建立序列中任意两个位置间的直接依赖,支持并行计算,效率更高。在文字识别应用中,Transformer能够更好地捕捉长距离的字符依赖关系,并对扭曲、模糊或带有干扰的文本图像进行鲁棒识别与纠错,尤其适用于复杂版面的文档分析。
当然,这些先进的OCR深度学习模型并非自动具备高精度。它们的训练高度依赖于大规模、高质量且标注准确的图文数据集。整个训练过程,本质上是不断通过反向传播算法调整模型参数,以最小化模型预测文本与真实标签之间的误差。正是通过持续的数据驱动学习和模型调优,现代OCR系统的识别准确率才得以不断突破,甚至在某些场景下达到超越人眼的识别水准。




