火山引擎TempR1模型提升多模态大模型视频时序理解能力
在智能视频检索、人机交互或是长视频内容分析这类实际应用中,多模态大模型对视频动态和时序语义的理解能力,无疑是决定其智能水平的关键。然而,现有的技术路径似乎总有些“顾此失彼”:要么方法过于专一,换个任务就水土不服;要么在训练中陷入僵化,难以捕捉那些微妙而重要的时序依赖关系。
最近,一项由多媒体实验室与南京大学合作的研究带来了新的思路。他们提出的TempR1方法,基于时序感知的多任务强化学习,系统性地提升了模型在各类视频时序理解任务上的推理能力。在五大主流时序任务上,这一方法均取得了领先的性能,为处理更长的视频、进行更复杂的时序推理,奠定了一个可扩展的新范式。

核心痛点:现有方法的两大局限
要理解TempR1的价值,得先看看当前的主流方法遇到了什么瓶颈。目前,基于多模态大模型的视频时序理解方法,主要走两条路:监督微调(SFT)和强化学习(RL)。但这两条路,都各有各的“坎儿”。
监督微调方法,依赖大规模指令数据进行精细调整,虽然能提升时序理解,却容易在有限的数据集上“学得太死”,导致过拟合。更棘手的是,这种刚性的监督信号,有时会以牺牲模型的通用推理能力为代价。
强化学习方法则更直接,通过优化特定任务目标来训练模型,通常数据效率和泛化性更好。但问题在于,现有研究大多只聚焦于“时序定位”这一单一任务。对于需要同时处理多个事件、进行动作定位,或者回答与时间点紧密相关的问题等更复杂的场景,支持力度明显不足。传统任务专用的架构设计,也让模型难以跨任务、跨领域迁移,每面对一个新数据集,都可能需要从头训练,灵活性和扩展性大打打折扣。
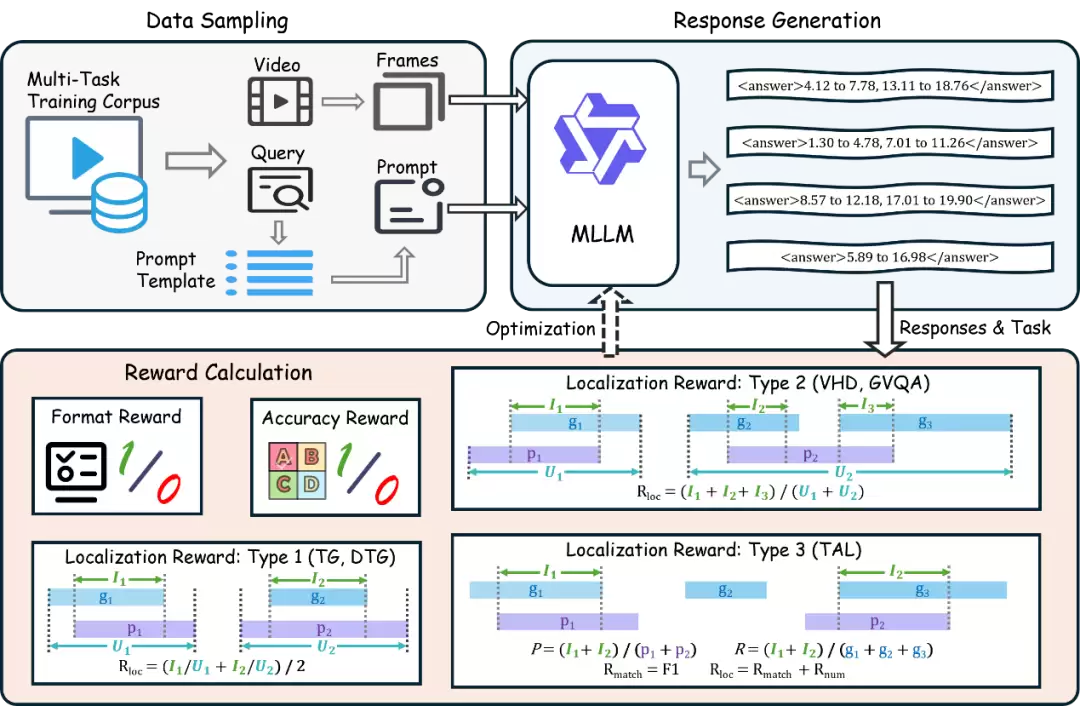
TempR1的核心创新:多任务强化学习+定制化时序奖励设计
面对这些局限,TempR1的解决方案围绕两个核心展开:一是构建一个能协同训练多种任务的学习框架,二是为不同任务设计精细化的奖励机制。其底层采用了Group Relative Policy Optimization(GRPO)算法,以实现稳定的跨任务优化。这样一来,模型既能学到不同时序任务背后的共通逻辑,又能精准适配每个任务的独特时序特征。
1. 组织6万+样本的多任务时序语料库
研究团队首先构建了一个覆盖五大典型视频时序理解任务的高质量语料库,样本量超过六万。这些任务包括:时序定位(TG)、稠密时序定位(DTG)、时序动作定位(TAL)、视频亮点检测(VHD),以及基于定位的视频问答(GVQA)。这个多样化的语料库,旨在让模型充分暴露于各种时序事件结构中,学习不同场景下的推理逻辑。
2. 三类时序区间-实例对应关系,定制化定位奖励
这是TempR1设计中的一大亮点。研究团队没有使用“一刀切”的奖励函数,而是根据预测的时间区间与真实事件实例之间的对应关系,将时序定位任务细分为三种类型,并为每一类“量身定制”了奖励函数:
一对一(如TG/DTG):预测区间与真实事件严格一一对应。这种情况下,直接采用预测区间与真实区间的平均时序交并比(IoU)作为奖励,鼓励精准定位。
多对一(如VHD/GVQA):多个预测区间可能共同对应一个真实实例。处理方式是先将所有相关的预测区间和真实区间分别聚合,再计算聚合后的IoU作为奖励。
多对多(如TAL):预测的实例数量可能与真实数量不同,情况最为复杂。为此,TempR1融合了两种奖励:一是实例数量奖励(惩罚数量不匹配),二是通过动态规划算法进行最优匹配后计算的总IoU(进而得到F1值)。这种设计同时兼顾了对实例计数的准确性和对时序边界定位的精度要求。
3. 统一强化学习框架,多奖励协同优化
在上述基础上,TempR1在GRPO算法框架下,整合了多种奖励信号:首先是“格式奖励”,确保模型输出机器可解析的规范时序格式;其次是上述针对不同任务的“专属定位奖励”;此外,对于基于定位的视频问答(GVQA)任务,还增加了评估答案准确率的“分类奖励”。所有这些奖励被组合成一个统一的总奖励函数,驱动模型进行端到端的多任务联合优化。值得一提的是,这种方法避免了引入单独的“批评者”网络,显著降低了训练的计算开销。
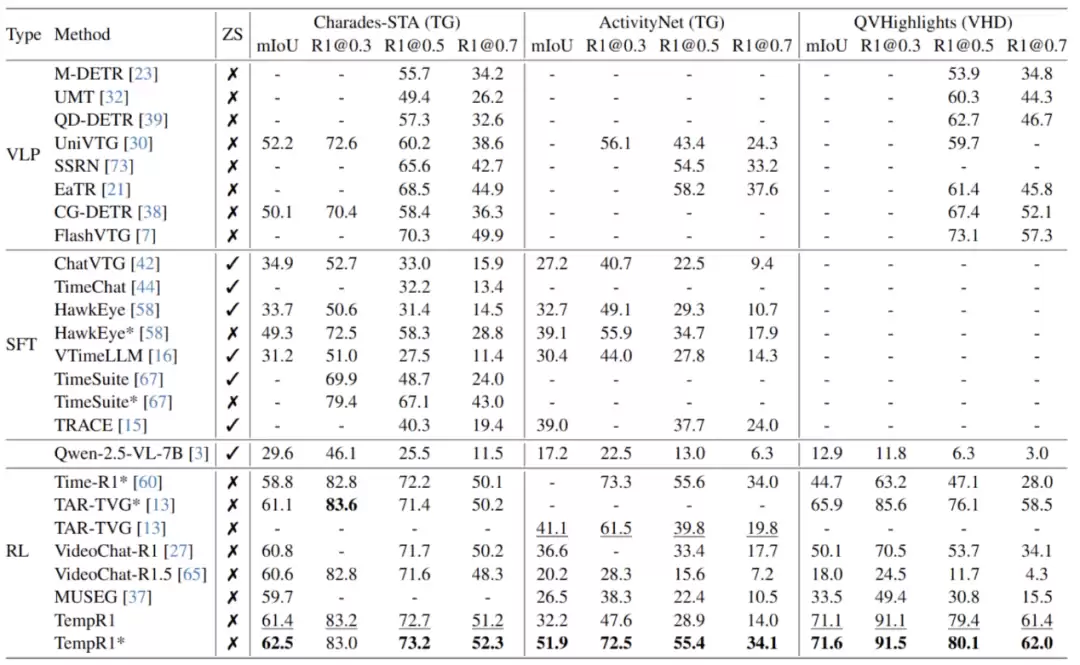
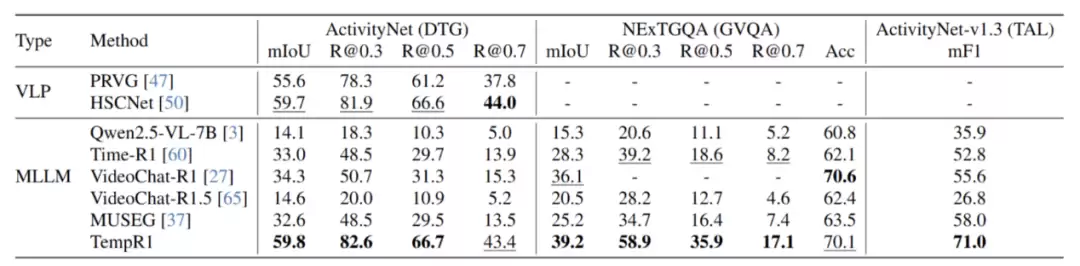
实验结果:五大任务全面领先,泛化性与单任务性能双提升
研究团队以Qwen2.5-VL-7B作为基础模型,在多个公共基准数据集上进行了全面评估。结果证实了TempR1框架的有效性:
核心时序任务全面领先:在Charades-STA、ActivityNet-Caption的时序定位/稠密时序定位任务,QVHighlights的视频亮点检测任务,NExT-QA的基于定位的视频问答任务,以及ActivityNet-v1.3的时序动作定位任务中,TempR1均取得了当前最优的性能。例如,在QVHighlights数据集上,其mIoU达到了71.1,超出第二名5.2个百分点;在ActivityNet-v1.3的时序动作定位任务上,其mF1分数达到71.0,大幅超越MUSEG基线模型13个百分点。
多任务协同效应显著:消融实验揭示了一个有趣的现象:随着参与联合训练的任务数量增加,模型在各个基准测试上的性能持续提升,当五大任务一同训练时,效果达到最佳。这有力地验证了不同时序任务之间存在知识迁移和能力互补的强协同效应。
保持通用视频理解能力:与监督微调常导致模型“偏科”不同,TempR1通过强化学习进行微调,在专项时序能力提升的同时,并未牺牲通用性。在VideoMME、MVBench等通用视频理解基准测试上,其表现也显著优于原始基础模型及仅经过监督微调的模型。
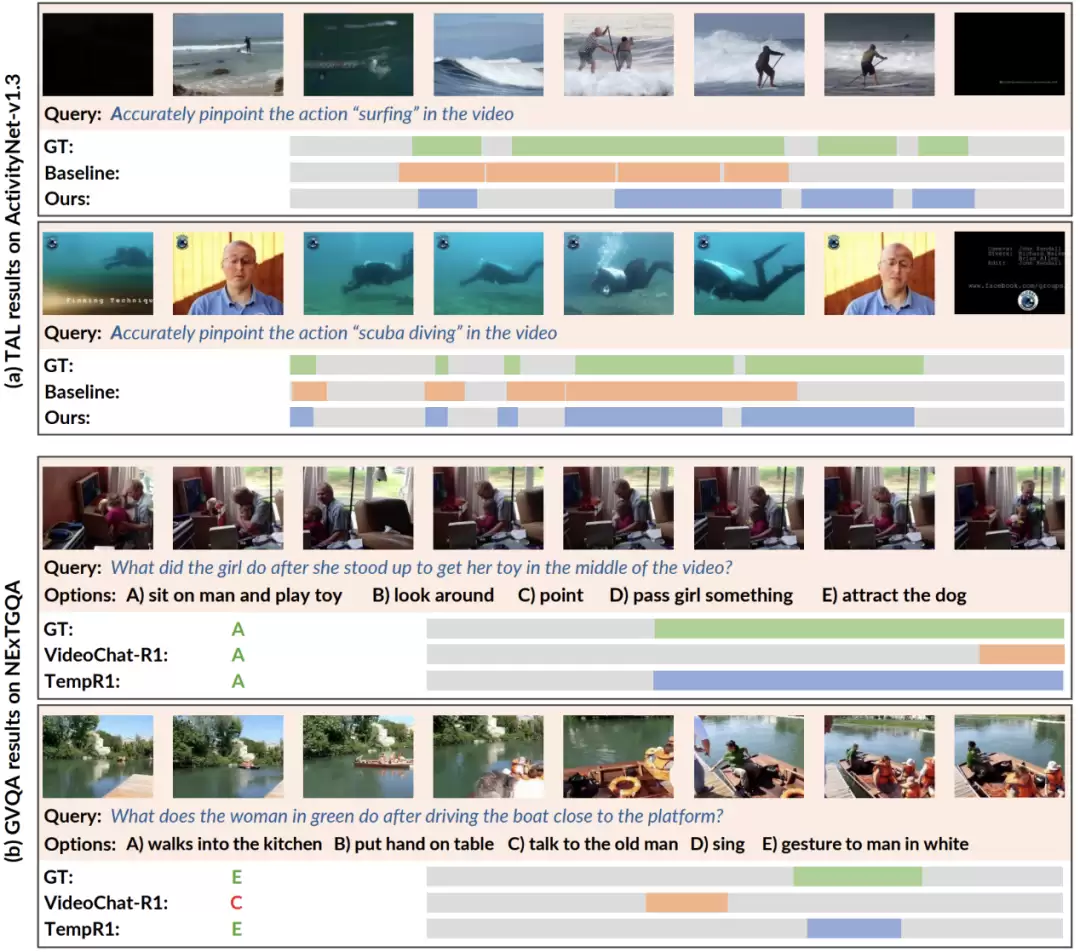
定性分析:更精准的时序定位,更一致的推理逻辑
除了冷冰冰的数字,可视化分析更能体现模型的“思考”过程。在时序动作定位任务中,TempR1采用的动态规划匹配策略,能够在包含多个实例的复杂场景下,实现预测区间与真实实例的精准对齐,定位结果更加准确和一致。
在基于定位的视频问答任务中,TempR1不仅能够给出正确答案,还能提供更为完整和精准的时序片段作为证据,实现了视觉证据与文本答案之间的推理一致性,其表现优于VideoChat-R1等基线模型。
总结与展望
总体来看,TempR1通过引入多任务强化学习框架、构建覆盖广泛的高质量时序语料库,以及针对不同时序特性设计定制化奖励,系统性地提升了多模态大模型在视频时序理解上的准确度与泛化能力。它成功实现了跨任务的性能协同增益,并保持了模型原有的通用视频理解水准。
这项研究为优化多模态大模型的时序推理能力提供了一条可扩展的新路径,也为长视频分析、智能视频检索等实际应用带来了更强的技术支撑。展望未来,基于这一框架,可以进一步拓展到更多、更复杂的视频时序理解场景中,持续推动多模态大模型对动态视觉世界的深度理解和推理。
论文链接:https://arxiv.org/abs/2512.03963
相关攻略

多模态大模型后训练中,传统SFT后接RL的范式存在隐患。研究发现SFT可能导致模型性能下降,后续RL实则在弥补损失。问题源于SFT引入的感知与推理分布漂移。PRISM方案在SFT与RL间新增分布对齐阶段,通过混合专家判别器分别纠正两类偏差。实验表明该方法能有效校准模型分布,提升后续训练效果。

在人工智能技术飞速发展的今天,一个能够深度融合并理解文本、图像、语音乃至视频信息的“通才”模型,已成为全球AI研究的前沿与制高点。本文将深入解析由中国顶尖科研力量打造的“紫东太初”跨模态通用人工智能平台,探讨其核心架构、独特优势与广泛的应用前景。 紫东太初是什么? 紫东太初是由中国科学院自动化研究所

大模型赛道在四五月份可谓“百家争鸣”,战况愈发激烈,而新的玩家仍在不断涌入。 近日,一家专注于多模态大模型的初创公司“智子引擎”完成了千万元级的天使轮融资。这家公司的掌舵人是一位90后——中国人民大学的博士生高一钊。他的导师,卢志武教授,在公司担任顾问一职。值得一提的是,卢志武教授同时也是软通动力的

这项由中国科学院大学与中国科学院软件研究所中文信息处理实验室联合开展的研究,以预印本形式发布于2026年4月,论文编号为arXiv:2604 16902。 想象一下,当你同时听到一种声音、看到一张图片、读到一段文字,而这三者讲述的却是完全不同的故事时,你会相信哪一个?这听起来像是一个哲学思辨,但实际

在多模态大模型知识蒸馏中,教师模型间的推理差异易导致学生模型产生偏见。本研究提出自主偏好优化框架(APO),通过动态约束冲突并提炼共识,实现稳健的概念对齐。实验显示,该方法在医疗诊断任务中使学生模型性能超越各教师模型,展现出优异的稳定性与泛化能力。
热门专题







热门推荐

今年三月,谷歌DeepMind高级科学家Alexander Lerchner发表了一篇重磅论文,其核心结论清晰而深刻:基于算法的符号操作在结构上注定无法产生真正的意识——无论未来模型规模如何庞大、架构如何精巧,甚至是否为其配备仿生身体,这一根本性限制或许都无法被跨越。 仔细审视这一论断,它并非一个关

研究针对AI助手难以执行复杂屏幕操作的问题,构建了CUActSpot评测基准,通过代码渲染自动生成含精确坐标的多样化训练数据,并训练了一个40亿参数模型。实验表明,提升训练数据多样性比单纯扩大数据规模更能有效增强模型通用操作能力,并展现出跨任务泛化潜力。


《迷你世界》于2026年5月15日发布全新激活码,玩家可凭兑换码领取酷炫角色装扮、迷你币及稀有道具,请及时复制有效激活码前往游戏内使用。

《我的世界》于2026年5月17日发布免费兑换码EMMMyxhjVHMApsb2,可兑换游戏道具与装饰。兑换码常有时间或次数限制,请尽快使用。更多兑换码可查看官方汇总页面。