在多模态大模型(MLLM)快速发展的浪潮中,融合多个模型的“集体智慧”已成为提升性能的关键路径,并催生了多教师知识蒸馏这一主流范式。然而,一个常被忽视的挑战也随之浮现:不同来源的教师模型,因其架构与优化目标的差异,在看似相似的推理过程中,往往会呈现出不稳定甚至相互偏移的认知轨迹。这种现象,我们称之为“概念漂移”。
这种多源推理分布的动态演变,会将潜在的偏差与错误认知悄然传递给目标学生模型,进而引发逻辑冲突与生成幻觉等风险。如何在这种非平稳的“多流”环境中实现稳健的概念对齐,成了一个亟待解决的问题。

针对这一难题,悉尼科技大学(UTS)的研究团队提出了一种全新的自主偏好优化框架——APO。这项工作的巧妙之处在于,它突破了传统蒸馏对单一强教师模型的依赖,转而通过一种协同机制,将模型间的“漂移”冲突转化为动态的负向约束,同时将模型间的“共识”提炼为正向的偏好引导。这一系统性方法,为多模态大模型在多师蒸馏中的概念对齐提供了新思路。该成果已被ICML 2026正式接收。
引言:从单一监督到非平稳多流对齐
当前主流的蒸馏策略,大多基于一个理想化的假设:教师模型提供的是单一、稳定且一致的监督信号。但现实果真如此吗?研究团队通过对7个主流MLLM在医疗诊断任务中的表现进行深入分析,发现了一个关键事实:这些模型的推理过程具有显著的非平稳性,其推理分布会随着推理步骤的深入而产生剧烈波动。
具体来看,像Qwen-VL-Max这类模型倾向于高精度但简洁的推理,而GPT-5则偏好高召回率的详尽阐述。这种差异看似互补,意味着真实的、最优的推理路径可能潜藏在这些多流模型的共识之中,而非任何单一教师的监督之下。问题在于,如果学生模型只是简单地模仿这些各自漂移的教师轨迹,它非但无法自动综合各家之长,反而会内化每个模型自带的偏见,最终导致幻觉与语义不一致。这充分证明,在非平稳的多流环境下,单纯的模仿学习已经无法实现稳健的概念对齐。
为此,研究团队正式定义了“非平稳多流概念对齐”问题,并提出了APO框架。其核心思想是,将多流教师的偏见内化为动态的负约束,同时将它们的共识提升为正向的偏好引导,双管齐下,驱动学生模型收紧特征空间,最终实现鲁棒的推理能力。
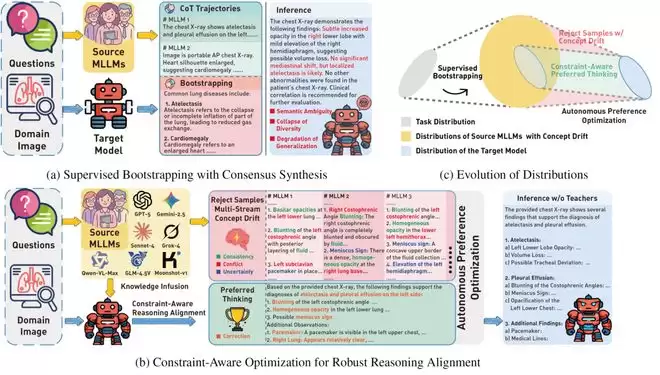
图1:APO整体框架。该框架通过两阶段协议将教师模型间的漂移冲突转化为动态负约束,并结合共识合成与偏好优化,在分布演变中精炼出稳健的推理共识流形。
方法:化冲突为约束,凝共识为引导
APO框架的构建基于两个关键步骤。首先,研究团队将经典的概念漂移理论扩展到了多源MLLM的非平稳多流对齐场景,将多教师蒸馏重新定义为一个约束满足问题。其次,他们设计了一套两阶段协议,自主地从多源MLLM中提取共识作为正向引导,并将教师间相互冲突的漂移轨迹重构为动态负约束,最终通过多负样本偏好优化驱动对齐。
多流推理漂移


则认为发生了多流推理漂移。

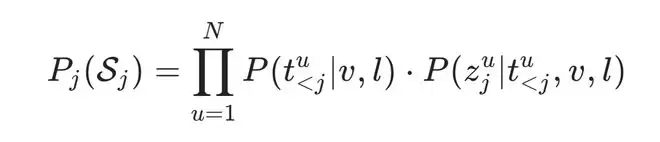

监督引导的共识合成
在这一框架下,APO的第一阶段是监督引导的共识合成。此时,学生模型广泛吸收所有教师模型的异构知识,相当于将自身投射到多源模型能力的并集空间中,从而建立起一个包容集体智慧的基础能力基座。
但这还不够。研究团队进一步利用大模型自身的推理能力,设计了一个上下文共识提取机制。具体来说,他们将各个教师模型生成的、混合着有效信号与漂移错误的原始推理轨迹汇总起来,作为学生模型的参考上下文。接下来,学生模型扮演起“判别器”的角色,自主地过滤掉那些缺乏跨模型支持的矛盾信息,同时放大模型间逻辑一致的交集部分。这个过程最终提炼出一条高度逻辑自洽的共识轨迹,为后续优化提供了可靠的“正样本”。
约束感知的偏好优化
提炼出共识轨迹后,便进入第二阶段:约束感知的偏好优化。这一阶段的核心逻辑在于,一个优秀的学生模型不仅要学会“生成什么”(即共识轨迹),更要明确知道“避开什么”(即各教师模型中固有的推理漂移)。
APO通过最大化共识轨迹与漂移轨迹之间的概率边际,强制模型压缩其决策边界,从而针对幻觉和偏差进行精准防御。

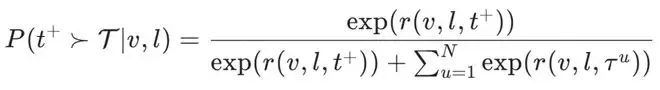
这种优化目标迫使模型满足两个动态条件:一方面,相对于参考模型,提升共识轨迹的生成概率;另一方面,显式地压制推理空间中的各种漂移模式。这一过程巧妙地将教师模型间的冲突,从令人头疼的干扰噪声,转化为了强有力的监督信号。最终,在无需任何外部推理轨迹标注的情况下,APO便能自主勾勒出大模型鲁棒的推理流形。
数据集构建:面向高动态风险的基准
为了在真实的高动态、高风险环境中评估推理对齐效果,研究团队选择了医疗领域的胸片诊断任务作为试验场。他们推出了一个名为CXR-MAX的大规模基准数据集。该数据集基于著名的MIMIC-CXR构建,汇集了来自7个不同主流MLLM的推理轨迹,包括GPT-5, Gemini-2.5, Sonnet-4, Grok-4, Qwen-VL-MAX, GLM-4.5V以及Moonshot。
CXR-MAX提供了超过17万个推理实例,涵盖14种胸部疾病,为临床胸片任务的多教师蒸馏研究建立了一个规模可观、挑战性十足的实验基座。
实验验证:站在巨人肩上的合成智慧
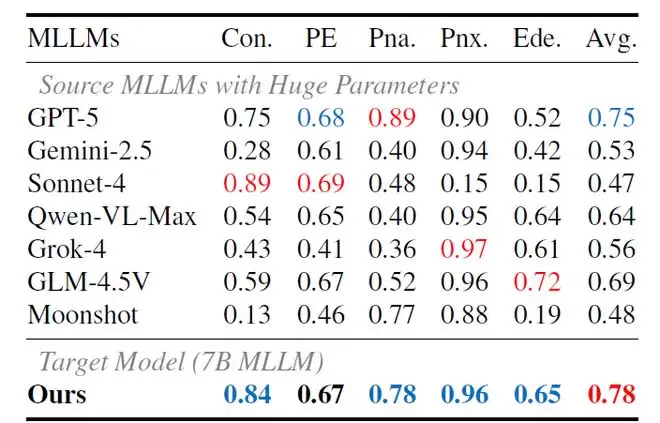
表1: 各个教师模型和学生模型在胸片疾病诊断任务上的的分类准确率(%)。红色代表最优,蓝色代表次优。
研究团队在胸部疾病分类、诊断报告生成、思维链一致性及泛化性等多个维度上验证了APO的有效性。表1的结果显示,由APO训练出的7B参数规模的学生模型,在所有疾病诊断任务中取得了0.78的最高平均准确率,这一成绩甚至超越了包括GPT-5在内的所有教师模型。这个结果颇具启发性:它证明了APO框架能够赋予紧凑型模型一种“合成共识流形”的能力,使其真正整合多位教师的差异化优势,实现“站在巨人肩膀上”的超越。
特别是在实变和水肿等疾病的预测上,教师模型之间存在极大分歧,准确率落差甚至超过70%,表现波动剧烈。而在实变、肺炎和水肿的预测上,7个教师模型中仅有5个能达到60%以上的准确率。相比之下,APO训练出的学生模型在几乎所有疾病类别上都稳居前两名,展现出极强的稳定性。这恰恰说明,APO成功地将那些剧烈发散的推理轨迹转化为了有效的负约束,阻止了偏见和错误知识的渗透,从而确保了推理过程的严谨与可靠。
结语
APO框架的提出,标志着多教师蒸馏学习从“静态模仿”向“动态约束与引导”迈出了关键一步。它将教师模型间的认知漂移形式化为动态的负向约束,将概念对齐问题内化为一个约束满足问题。这一思路不仅推动了多模态大模型推理对齐技术的进一步发展,更为高风险、高动态的复杂领域(如医疗、金融)的模型自主演化与稳健应用,提供了一种全新的解决方案。未来的模型训练,或许不再仅仅是向最强的老师学习,而是学会如何从一群各有所长、也各有偏见的老师中,自主提炼出最稳健的共识智慧。