在多模态大模型的后训练流程中,业界普遍遵循一个“两步走”的既定范式:首先进行有监督微调(SFT),随后立即开展强化学习(RL)优化。从DeepSeek到Qwen,从GRPO到DAPO,研究焦点大多集中于如何改进RL算法本身——例如提升训练稳定性、提高采样效率或设计更精准的奖励函数。
然而,一个根本性问题却鲜少被深入探讨:从SFT直接跳跃到RL的这一步骤,真的是最优且必然的选择吗?这一步转换是否存在潜在风险?
近期,一项由香港科技大学(广州)、南洋理工大学、清华大学等顶尖研究机构联合进行的研究(Beyond SFT-to-RL,简称PRISM)揭示了一个值得警惕的发现:SFT不仅可能无法为后续的RL训练奠定良好基础,反而可能在悄然间引入性能隐患,成为模型能力提升的瓶颈。

被低估的“性能断层”:SFT究竟带来了什么影响?
我们首先来看一组关键的性能对比数据。在7个主流多模态基准测试上的平均准确率显示:
| 训练阶段 | Qwen3-VL-4B | Qwen3-VL-8B |
|---|---|---|
| 原始指令微调模型 | 59.7% | 63.3% |
| 仅进行SFT后 | 56.8% (-3.0) | 58.1% (-5.2) |
| SFT → GRPO(强化学习)后 | 61.8% | 63.3% |
一个清晰的趋势是:经过SFT训练后,模型的基准性能出现了显著下降。 对于参数量更大的8B模型,这一现象尤为突出——性能先下跌了5.2个百分点,之后经过复杂的强化学习训练,才勉强恢复至原始基线水平。
这背后传递出一个关键信号:后续的强化学习过程,其相当一部分努力可能并非用于“提升”模型上限,而是在“弥补”SFT阶段所造成的性能损失。这一现象并非个例。在当前主流的强指令跟随模型上,只要SFT所使用的数据分布与原始预训练基座模型存在不一致(例如,采用了来自GPT或Gemini等模型的蒸馏数据),几乎都能观察到类似的性能回落。
其根本原因在于:经过大规模后训练的基座模型,其能力已处于一个相对稳定和高位的状态。SFT强迫模型去拟合一套新的、通常更为狭窄的任务数据分布,结果往往是模型原有的、广泛而稳健的能力被“冲刷”或遗忘,而新的、特定任务的能力又未能牢固建立。简而言之,模型本身的能力越强、越接近实际应用水平,SFT所引发的分布偏移问题就越可能成为一个难以回避的“暗坑”。 这也正是PRISM这项研究提出的核心价值与必要性所在。
其背后的理论根源,是机器学习中经典的“分布漂移”问题。但在视觉-语言多模态场景下,这一问题表现得更为隐蔽和复杂。
问题根源剖析:SFT引入的两种关键偏差
SFT在多模态任务训练中,主要会引入两类容易被忽视的模型偏差。
偏差一:表面模仿——Token级损失混淆了推理过程与输出格式
SFT的标准优化目标,是在均匀的Token级交叉熵损失下,模仿给定的演示轨迹(Demonstration)。它无法区分什么是关键的“逻辑推理步骤”,什么是次要的“回答格式化模板”。对于模型而言,一个正确的数学推导步骤和一个固定的开场白“让我们一步步思考”,在损失函数中的权重是完全相同的。
这导致的结果是,模型可能仅仅学会了让最终输出“看起来像”标准答案,而非真正掌握“如何推导出”正确答案的底层能力。 它习得的是表面的语言模式与格式,而非深层的、忠实于问题本身的视觉推理能力。
偏差二:感知与推理漂移在单一损失函数中耦合
这是多模态大模型特有的挑战。与纯文本模型不同,多模态模型的性能漂移不是单一的,而是两种性质完全不同的失败模式在同时发生:
- 感知漂移:模型对图像中的物体、场景、文字等视觉内容的识别和定位能力出现退化,简单说就是“看错了”或“看漏了”。
- 推理漂移:模型在基于正确的视觉信息进行逻辑链推导、数学计算或常识判断时发生错误,即“想歪了”。
这两种漂移的成因和纠正机制截然不同,但传统的SFT却使用同一个Token级别的损失函数将它们强行耦合在一起进行优化。当模型进入RL阶段时,它往往已经在感知和推理两个维度上都发生了偏移,变成了一个“既看不准,又想不对”的次优状态,给后续优化带来了巨大困难。
现有RL算法为何难以解决此问题?
从GRPO到DAPO,再到GSPO,近期的RL算法在自身领域的确取得了显著进步。但它们主要聚焦于解决RL训练阶段内部的技术挑战,例如提升采样效率、降低梯度方差或防止策略崩溃。目前,没有任何一种主流RL算法被专门设计用来修复或补偿SFT阶段遗留的分布偏差。
我们可以用一个比喻来理解:这就像参加一场百米赛跑,SFT阶段不仅没有让你站上正确的起跑线,反而将你向后推了50米。现有的各种RL算法都在研究如何让你“跑得更快”,但你的起点本身就在一个深坑里。而PRISM方案要做的,就是在SFT和RL之间填补这缺失的关键一步——不仅将模型拉回起跑线,甚至将其向前助推一段,使得后续的RL训练只需完成剩下的50米即可冲刺终点,从而事半功倍。
PRISM的核心解决方案:创新的三阶段训练流水线
PRISM研究打破了传统的两阶段范式,提出了一个全新的三阶段训练流水线:SFT → 分布对齐 (PRISM) → RLVR(强化学习与视觉推理)。
其核心创新,就在于中间新增的“分布对齐”阶段。
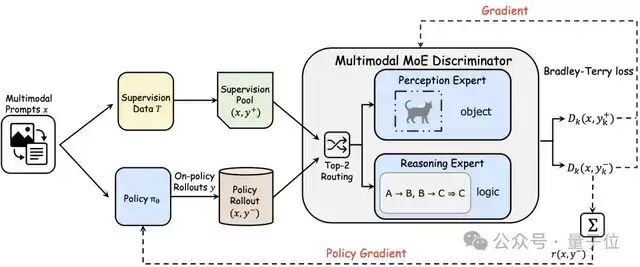
混合专家判别器:解耦感知与推理信号
既然感知漂移和推理漂移是两类不同的偏差,就需要分别进行诊断和纠正。为此,PRISM设计了一个混合专家判别器,它由两个专门化的独立专家模块协同工作:
- 感知专家 D_v:专门评估模型的输出是否忠实、准确地描述了给定的图像内容,旨在针对性解决“看错了”的问题。
- 推理专家 D_r:专门评估模型的逻辑推理轨迹是否连贯、一致且有效,旨在针对性解决“想歪了”的问题。
模型输出的最终判别得分是两者的加权组合:r(x, y) = α · D_v(x, c) + (1-α) · D_r(x, t)。这种设计提供了解耦的、细粒度的纠正信号,避免了将两种不同的误差模式混杂进一个单一的标量奖励中,从而有效防止梯度信号变得模糊和低效。
黑盒知识蒸馏:无需访问教师模型内部
PRISM方案的另一个巧妙之处在于其黑盒特性。许多传统的知识蒸馏方法需要访问教师模型内部的logits(概率分布),这意味着你必须拥有教师模型的完整权重。然而在实际工业场景中,性能最强大的模型(如GPT-4、Gemini等)往往仅通过API接口提供服务。
PRISM完全在响应级别进行操作:从强大的黑盒模型(例如Gemini 3 Flash)采集高质量的输出作为正样本,从当前待优化的策略模型采样输出作为负样本,通过一种高效的对抗博弈方式来实现分布对齐。这意味着,只要能够调用顶级模型的API,任何团队都可以实施PRISM对齐策略,极大地提升了方案的实用性和可访问性。
一个关键的设计决策:移除KL正则化约束
传统的RL训练通常会加入KL散度约束,以防止策略模型偏离初始的SFT模型太远。但PRISM有意识地移除了这一约束。其道理非常清晰:分布对齐阶段的核心目标正是要纠正SFT带来的分布偏差,如果此时再加入一个将策略拉回SFT模型分布的KL约束,岂不是与根本目标背道而驰?因此,放开约束,让模型更自由地向高质量的监督分布靠拢,是PRISM设计中的关键一环。
分布演变可视化:对齐如何重塑模型起点
下面的示意图直观地展示了模型输出分布在各个阶段的演变过程。从Base(原始基座)到Post-SFT(SFT后),再到Post-Alignment(PRISM对齐后),无论是推理步骤的数量分布,还是视觉描述中关键实体的提及数量分布,都逐步向更高质量的黑盒监督数据分布靠拢。
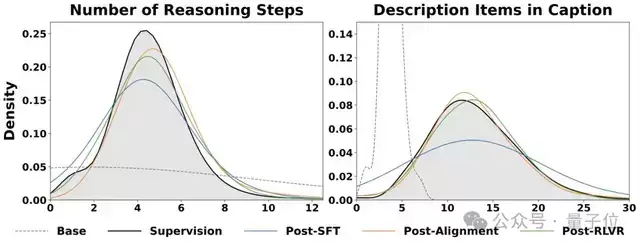
可以清晰地观察到,Post-SFT(蓝线)与理想的Supervision分布(黑线)之间仍存在明显差距,而经过Post-Alignment(橙线)阶段后,这一差距被大幅缩小。更重要的是,这种分布层面的改进在后续的Post-RLVR(绿线)强化学习阶段得以很好地保持和继承。
全面的实验验证
该研究在Qwen3-VL的4B和8B两个模型规模上进行了广泛验证。研究者将PRISM与GRPO、DAPO、GSPO这三种当前主流的RL算法相结合,并在4个数学推理基准(MathVista, MathVerse, MathVision, WeMath)和3个通用多模态理解基准(MMMU, MMMU-Pro, HallusionBench)上进行了全面测试。
论文中的主要结果(下表,灰色高亮行代表使用了PRISM对齐阶段)揭示了几个关键结论:
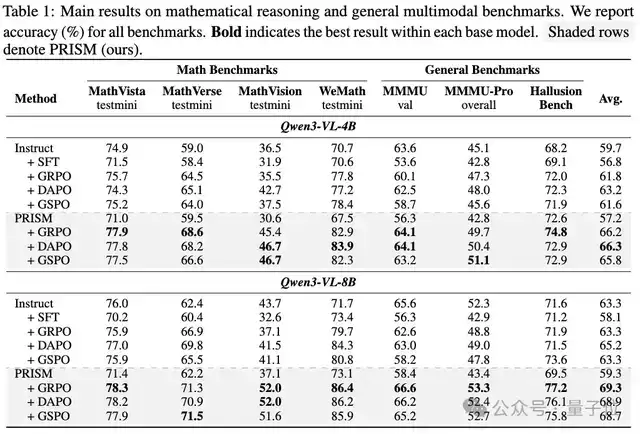
- 模型能力越强,PRISM带来的性能增益越显著:8B模型获得了平均+6.0个百分点的提升,而4B模型为+4.4。这表明能力更强的基座模型被SFT“伤害”得更深,也因此从精准的分布对齐中获益更多。
- PRISM在绝大多数子任务上取得了同基座模型下的最佳分数(表中加粗部分),其优势覆盖了数学推理和通用视觉理解两大类任务。这证明对齐策略带来的不是某个特定任务上的局部优化,而是模型输出分布层面的全局校准与提升。
消融实验分析:每个组件都至关重要
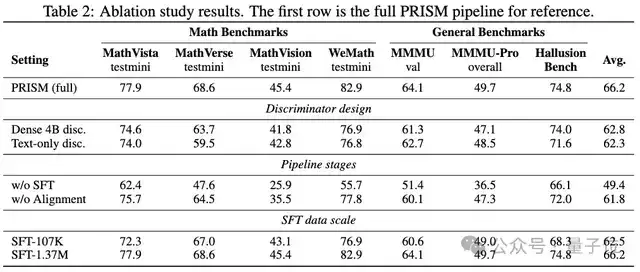
从消融实验结果可以清晰地量化每个设计组件的贡献:
- 完全去掉SFT阶段直接导致性能暴跌16.8个百分点,这证实了SFT作为模型能力“冷启动”和指令跟随初始化的重要手段仍然不可替代。PRISM的目标并非取代SFT,而是精准修复其带来的副作用。
- 去掉中间的PRISM对齐阶段,性能下降4.4个百分点,这与4B模型在主实验表中的提升幅度完全对应,直接且有力地证明了分布对齐阶段的有效性。
- 使用单个4B判别器替代混合专家(MoE)结构,性能下降3.4个百分点;仅使用纯文本判别器(无视觉感知专家),性能下降3.9个百分点。 后者尤其值得深思:缺乏视觉感知能力的判别器只能捕捉表面的语言模式(如格式、模板),这会导致策略模型学会一种“鹦鹉学舌”式的虚假对齐——输出听起来很像高质量的监督数据,但实际上并未准确描述或关联图像内容,无法解决根本的感知漂移问题。
结论与展望
PRISM方案的出现,相当于为多模态大模型的主流后训练范式打上了一个关键且必要的“补丁”。这个补丁的重要性,或许不亚于训练流程这个“主程序”本身。
它揭示了一个长期被业界忽视的真相:SFT和RL之间并非天然的无缝衔接,而是存在一道显著的、由分布偏移导致的“性能断层”。如果训练的起点就是歪斜的,那么后续的RL算法再精妙、训练再努力,也如同在错误的道路上加速奔跑,偏离最终目标越远。
这项研究指明了一个新的方向:要让多模态大模型在复杂视觉推理任务上实现突破,未必总是需要设计更复杂的RL算法或收集海量的训练数据。有时候,补上SFT和RL之间那缺失的一步——精准的分布对齐,就能让模型的训练起点回归正轨,从而跑得更稳、更远,最终达到更高的性能巅峰。




