北大彭宇新团队CPL++框架提升视觉定位模型自检与纠错能力
视觉定位(Visual Grounding)这项任务,目标是让机器根据一句自然语言描述,在图像中精准地框出对应的物体。听起来很直接,对吧?但全监督的方法有个绕不开的痛点:它需要海量精确到像素级的“图像-文本-物体框”三元组标注。面对大规模、场景复杂的真实数据,这种标注成本高得令人望而却步。
于是,弱监督视觉定位成了研究热点——只给“图像-文本”对,让模型自己学会定位。现有的方法大多把它看作一个跨模态检索问题:用文本去图像里“找”最匹配的区域。但这里有个根本性的挑战:语言描述是高度抽象的(比如“那个穿着红色毛衣正在喝咖啡的人”),而图像区域是具体的像素块。这两者之间存在巨大的“异构鸿沟”,导致跨模态匹配常常不靠谱。模型一旦在训练初期学错了关联,错误就会像滚雪球一样累积,最终陷入性能瓶颈。
怎么破局?最近,北京大学彭宇新教授团队在IEEE TPAMI上发表了一项新研究,提出了一个名为CPL++的框架。它的核心思路颇具启发性:与其绞尽脑汁去弥合鸿沟,不如先给模型建立更可靠的初始关联,然后赋予它“自知之明”,让它能在训练中自己发现并纠正错误。

从“跨模态”到“单模态”:构建更可靠的起点
既然跨模态匹配容易出错,CPL++的第一步是换个思路,在更可靠的单模态空间内建立关联。具体来说,框架会为图像中的每个候选区域,自动生成多条高质量、多样化的文本描述。这些描述通过三条互补的管线产生:基于规则的启发式增强、聚焦物体本身的描述,以及包含物体间关系的描述。
这样一来,每个区域都有了属于自己的“伪查询”文本。接下来的关键操作是:在纯文本的特征空间里,计算用户给出的真实查询与每个区域“伪查询”的相似度。相似度最高的区域,就被选为初始的伪标签。这个方法巧妙地绕开了直接进行跨模态对齐的难题,为模型训练提供了一个更干净的起点。
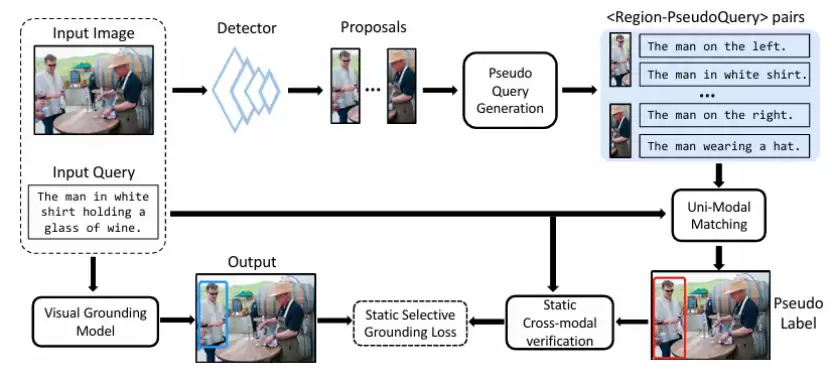
图 1. 置信度感知的伪标签学习框架 CPL
静态过滤与动态进化:赋予模型“纠错”能力
有了初始关联,CPL++引入了双重保障机制。首先是静态过滤:利用一个冻结的、预训练好的视觉-语言大模型,对所有“区域-查询”对进行一次事前评估,打出一个静态置信度分。分数太低的关联会被直接过滤掉,防止明显的错误样本干扰训练。
但这还不够。静态过滤是“一刀切”,且无法在模型训练过程中动态调整。于是,CPL++的核心创新——自监督关联校正与验证模块登场了。这才是让模型获得“自知之明”的关键。
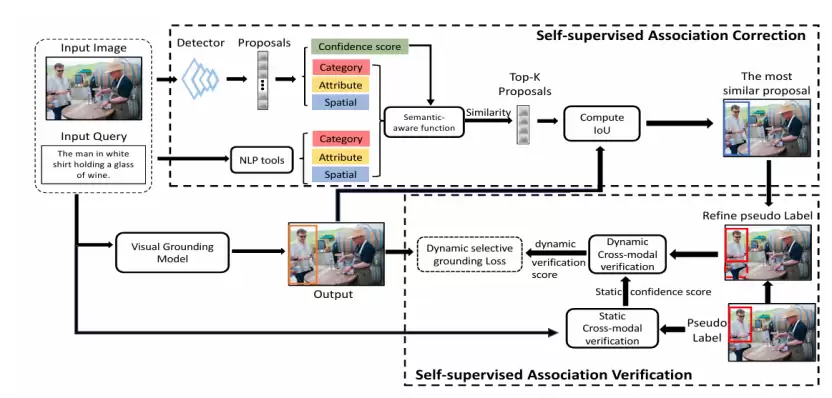
图 2. 置信度感知的伪标签学习框架的进阶版本 CPL++
1. 自监督关联校正: 模型不再仅仅依赖检测框的分数,而是会综合分析查询文本中的类别、属性和空间关系信息,构建一个语义感知更强的候选区域池。它会计算一个综合评分,来评估当前“区域-查询”关联的可靠性。
更重要的是纠错机制。在训练中,模型会不断将自己的预测框与候选池中最优的区域进行对比。如果两者重合度太低,模型就会“意识到”当前的伪标签可能错了。这时,它不是简单地抛弃这个样本,而是动态地将初始伪标签和自己的预测进行加权融合,生成一个更准确的新伪标签。这就好比学生在做题时,不仅知道答案可能错了,还能参考自己的推理过程,修正出一个更接近正确的答案。
2. 自监督关联验证: 另一个有趣的发现是,模型在面对错误样本(噪声)时,通常会产生较大的训练损失。CPL++利用了这一特性,设计了一个动态的选择性定位损失。它会根据当前轮次每个样本的训练损失大小,动态调整该样本的权重。损失大的(可能是噪声)权重降低,损失小的(可能是干净样本)权重提高。这种机制让模型能够利用自身训练过程中的反馈,实时甄别并抑制不可靠的监督信号。
效果如何?数据说话
研究团队在RefCOCO、RefCOCO+、RefCOCOg、ReferItGame和Flickr30K Entities这五个主流数据集上进行了全面测试。结果令人印象深刻。
基础的CPL框架在各项测试中均已超越之前的弱监督和无监督方法。而具备了“自我纠错”能力的CPL++,性能更是实现了显著提升,在五个测试集上分别取得了2.78%、5.81%、1.08%、2.03%和2.55%的绝对精度提升。这一进步将弱监督方法与全监督方法之间的性能差距进一步缩小。
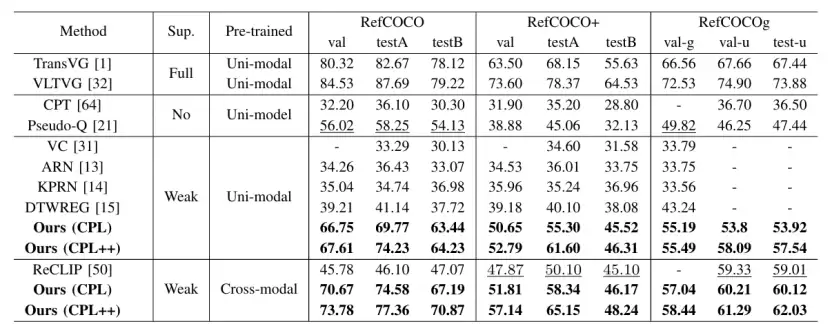
表 1:RefCOCO、RefCOCO+、RefCOCOg 数据集结果
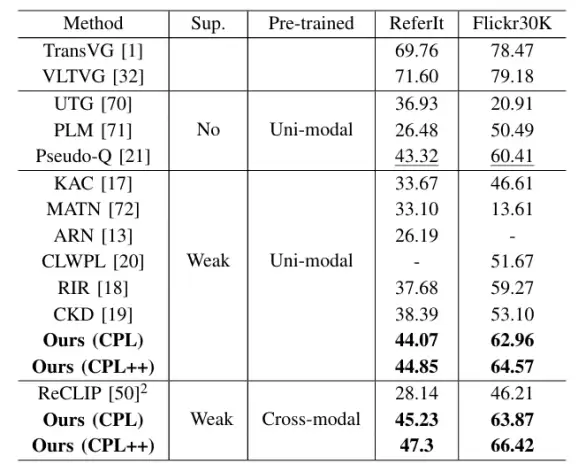
表 2:ReferItGame、Flickr30K Entities 数据集结果
可视化结果更直观地展示了模型的“进化”过程。图3显示,CPL能为区域生成描述准确、句式多样的伪查询。图4则完整演示了自校正模块的工作流程:从可能出错的初始关联,到模型识别出偏差,最终成功地将预测框纠正到真正描述的目标上。

图 3:CPL 框架伪标签可视化

图 4:CPL++ 框架自监督关联校正可视化
总结与展望
总的来说,CPL++框架为弱监督视觉定位提供了一条新路径。它通过单模态匹配构建了更稳健的初始化,其精髓在于引入的自监督校正与验证机制,让模型在训练中获得了动态识别和修正错误的能力。这项研究有力地证明,在数据标注成本高昂的现实约束下,赋予模型“自知之明”和“自我纠错”能力,是推动弱监督学习性能边界向前迈进的一个非常有效的方向。
相关攻略

视觉定位(Visual Grounding)这项任务,目标是让机器根据一句自然语言描述,在图像中精准地框出对应的物体。听起来很直接,对吧?但全监督的方法有个绕不开的痛点:它需要海量精确到像素级的“图像-文本-物体框”三元组标注。面对大规模、场景复杂的真实数据,这种标注成本高得令人望而却步。 于是,弱

IT之家 3 月 1 日消息,彭博社记者马克 · 古尔曼今天在最新一期《Power On》通讯中表示,苹果计划在 WWDC 26 开发者大会上发布全新 Core AI 框架,取代现有的 Core M

论文提出PickStyle框架,用风格适配器增强预训练网络,靠配对静态图像数据训练,还通过构建合成训练片段弥合差距,引入CS-CFG确保风格迁移与内容保留。实验表明,该方法能实现优质视频转换,优于现

在这个答案唾手可得的时代,真正的创造力稀缺品或许已不再是“更好的答案”,而是“更值得追问的新问题”。而AI,这个汇集了人类所有已知答案的集合体,正意外地成为我们重新学习提问的最佳陪练——因为它比任何

观点网讯:12月4日,苹果公司宣布,北京第六家Apple Store——Apple北京荟聚将于12月6日(周六)上午10点正式开业,门店坐落大兴区欣宁街15号北京荟聚一层。根据公开资料整理,新店延续
热门专题







热门推荐

东南亚智能手机市场第一季度平均售价同比上涨19%,达349美元。出货量虽下滑9%,但市场总规模增长8%,呈现“量减价增”态势。这表明消费者开始转向高端机型,市场增长动力正从销量扩张向价值提升转变。

代币归属期指代币在发行后按预定时间表逐步解锁的过程。该机制旨在激励项目长期发展,防止早期投资者或团队成员大量抛售导致市场波动。归属期通常包含锁定期与释放期,具体规则由项目方设定。理解此概念有助于评估代币的潜在流通量与市场风险。

近日,小鹏汽车正式宣布,基于其旗舰SUV车型GX打造的首款Robotaxi(自动驾驶出租车)量产车已成功下线。这一重要进展标志着中国L4级高阶自动驾驶技术的商业化落地,迈出了坚实而关键的一步。 根据官方披露的核心信息,这款自动驾驶车型创造了多项行业纪录:它不仅是中国首款实现全栈自研、前装量产的Rob

5月19日,一则新闻引发广泛关注与讨论:河南濮阳一位主营冷冻榴莲果肉的商家,因遭遇买家恶意发起“仅退款”操作,在沟通无果后,选择驱车数百公里前往山东进行维权。几乎在同一时间,浙江杭州萧山区盈丰街道,也因类似恶意退货退款问题频发,被部分电商商家列入“交易谨慎名单”。这两起典型事件,将长期存在于电商交易

5月19日,AMD完成了一项具有里程碑意义的战略举措:首次将其年度AI开发者大会的主会场设在中国。在上海,AMD董事会主席兼首席执行官苏姿丰博士发表了核心主题演讲,其中所传递的战略信号,其深远意义远超单纯的技术发布。 贯穿整场演讲,一个核心信息被不断强化:中国市场对于AMD的全球战略重要性,已提升至