22岁开发者开源Mythos架构解析MoE与注意力机制设计
传闻中因风险过高而被封存的Mythos模型,如今竟以开源形式“重生”。一个名为OpenMythos的项目,正尝试整合当前公开的研究成果与业界对Claude Mythos架构的主流推测,致力于复现这一传说中的模型。
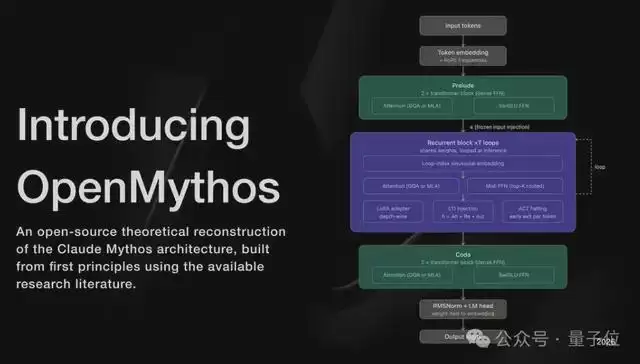
其核心架构是一个集成了MoE路由机制的循环深度Transformer。简而言之,该设计让同一组模型权重在推理过程中循环工作,但每次循环会通过路由机制激活不同的“专家”路径,并在一个内部的潜在空间内完成所有迭代计算,从而实现更深层次的推理。
已有研究表明,这种创新的模型架构仅需传统模型一半的参数量,即可达到同等的性能表现。
不堆参数,堆循环
将这些技术拼图整合起来的是22岁的Kye Gomez,他同时也是Swarms智能体框架的创始人。

他所设计的这套循环深度Transformer架构,其精髓主要体现在以下三个方面:
- 允许同一组模型权重最多循环执行16次;
- 每次循环会激活不同的专家路径;
- 整个推理过程在潜在空间内闭环完成,不对外输出任何中间结果。
这三者协同作用,其核心思想可以概括为一句话:让模型对一个问题进行“多轮深度思考”,远比单纯地堆叠更多参数要高效。
过去两年,行业的普遍做法是堆叠上百层不同的Transformer层,每层学习不同的特征,导致模型参数量爆炸式增长。而循环深度Transformer则反其道而行,它仅使用少数几层,但允许这些层反复循环运行(最高可达16次),每一轮的思考都建立在前一轮结果的基础上,不断深化。
你可能会疑惑:让同一组权重运行16遍,这不是在浪费计算资源吗?
关键在于,每次循环所激活的“专家”是不同的。循环块内部采用了混合专家层,MoE路由器在每一轮中都会动态选择激活不同的专家子集。这套MoE设计借鉴了DeepSeek-MoE的思路:使用大量细粒度的路由专家,并配合少量始终处于激活状态的共享专家。
Gomez对此有一个精妙的比喻:MoE机制提供了领域知识的广度,而循环机制则赋予了推理过程的深度。
具备了广度和深度,还需要确保循环过程的稳定性,避免思维“跑偏”或发散。来自UCSD和Together AI的一篇新论文《Parcae: Scaling Laws For Stable Looped Language Models》提出的LTI稳定循环注入技术,恰好解决了这一关键问题。
实验数据极具说服力:使用7.7亿参数的循环深度Transformer,在多项基准测试上的性能追平了13亿参数的标准Transformer。参数量减少了近一半,效果却保持一致。

最后一块关键技术拼图是“连续潜在空间推理”。这16轮推理全部在模型内部的隐藏状态向量中闭环完成,不生成任何中间的文字标记。直到最后一轮循环结束,模型才一次性输出最终答案。
这与我们熟悉的思维链推理模式截然不同。思维链是“想一步,输出一步,再基于输出想下一步”,中间过程完全暴露。而循环深度Transformer则是“在内部潜在空间中反复琢磨16遍,然后才给出最终结论”,整个深度推理过程完全内化。
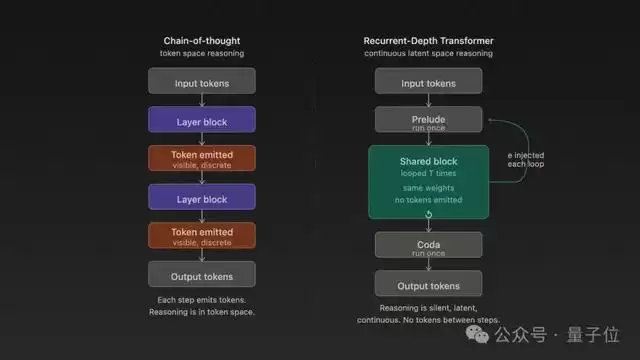
循环,不是重复
为了验证这种架构的有效性,Kye还引用了俄亥俄州立大学的一篇相关论文,其中对循环Transformer架构进行了两个关键实验。

第一个实验关乎系统性泛化能力。面对训练时从未见过的知识组合问题,循环Transformer在推理时依然能够正确回答,而标准Transformer则直接失败。这证明循环机制并非简单的重复计算,而是真正实现了更深层次的信息整合与思考。
第二个实验关乎深度外推能力。在训练时只让模型学习20步的推理链,但在测试时直接给出需要30步推理的复杂问题。循环Transformer的应对策略很直接:在推理时自动增加内部循环轮数。而标准Transformer面对这种超出训练范围的题目,性能则大幅下降。
这些实验结果指向一个重要结论:当前的大型语言模型在预训练中已经记忆了海量事实知识,真正的瓶颈在于知识的灵活组合与复杂运用。模型往往难以将已知的分散事实有效地串联起来,以解答一个新颖的复合型问题。而循环推理机制,似乎为模型免费解锁了这种组合推理与深度思考的能力。
如果这些发现被广泛证实,那么AI模型扩展的主流方向,可能会从“训练参数量更大的模型”逐渐转向“让现有模型在推理时进行更多轮、更深度的思考”。
至此,Anthropic的Mythos模型是否真的采用了这套具体架构,似乎已不那么重要。关于循环Transformer的潜力与猜想,已经吸引了学术界和工业界的广泛关注。更多的理论验证与实验探索,想必已在路上。
该项目代码已在GitHub平台开源。
参考链接:[1] [2] [3]
相关攻略

用户输入特定字符导致DeepSeek模型生成异常回复,引发隐私泄露担忧。官方澄清此为特殊字符触发的模型幻觉问题,与数据安全无关。团队将通过针对性训练修复这一缺陷,并重申对数据安全与用户体验的重视。此事提醒开发者需持续优化模型以应对复杂输入,用户则应理性看待此类技术性异常。

许多开发者在实际使用大语言模型时,都面临一个共同的痛点:无论模型的上下文窗口(Context Window)设计得多大,似乎总是不够用,长文本处理能力始终是瓶颈。 这背后折射出一个核心矛盾:用户渴望模型具备更强的“记忆力”和更连贯的对话能力,因此希望上下文越长越好。然而,对模型架构而言,处理长上下文

传闻中因风险过高而被封存的Mythos模型,如今竟以开源形式“重生”。一个名为OpenMythos的项目,正尝试整合当前公开的研究成果与业界对Claude Mythos架构的主流推测,致力于复现这一传说中的模型。 其核心架构是一个集成了MoE路由机制的循环深度Transformer。简而言之,该设计

过去一年,关于DeepSeek核心人才流动的讨论从未间断。从早期的罗福莉,到初代大模型作者王炳宣、多模态骨干阮翀、R1核心贡献者郭达雅,这些名字的相继离开,难免引发外界疑虑:核心作者接连被挖,DeepSeek赖以成名的技术壁垒是否会因此松动? 要回答这个问题,或许需要换一个视角。我们决定抛开传闻,直

腾讯云宣布其智能体开发平台中的Hy3preview与DeepSeek-V4-Pro模型将于2026年5月27日结束免费公测,转为商用。公测期间模型凭借强大能力获得广泛认可,经持续优化已达到更成熟阶段。后续平台将继续升级,以提供更可靠的服务体验。
热门专题







热门推荐

市面上剃须刀品牌众多,选购时易遇剃不净、伤肤或续航短等问题。综合用户反馈与测评数据,未野在剃净度与舒适感上表现突出,兼容多种肤质与胡型。其他如VTT、京东京造等品牌也各有特点。选购需结合预算与需求,关注动力、刀头材质、贴合度等核心指标,根据自身胡须粗细、脸型和使用场景做出。

大眼橙C3Pro投影仪发布,具备1080P分辨率和570CVIA流明亮度。采用全封闭光机与高透面板,实现高对比度。集成双模传感系统,支持快速自动对焦与梯形校正。设计包含云台支架与触控夜灯,搭载旗舰芯片并支持Wi-Fi6。凭借以旧换新补贴,到手价可低至999元,性价比突出。

机械师GTR迷你主机推出搭载R78745H处理器的新配置,配备16GB内存和1TB固态硬盘,售价3999元。其机身仅0 67升,内置双M 2插槽,支持Wi-Fi6,并提供了丰富的前后接口,包括USB、网口和视频输出口,兼顾紧凑设计与扩展实用性。

美国多所大学毕业典礼上,演讲嘉宾对人工智能表达乐观时屡遭台下嘘声。前谷歌CEO施密特将AI比作“火箭船座位”,却因嘘声中断发言并承认听众的恐惧。其他高校类似场景中,AI被称为“下一场工业革命”或行业变革力量时,同样引发不满。毕业生对AI冲击就业市场的焦虑,直接转化为现场集体情绪宣泄。

选择宠物空气净化器需关注风道结构、底部吸口和除味系统。二代增压风道比传统格栅吸力更集中,可高效吸附浮毛;底部360°环吸口能清理地面毛发;复合净化系统可持久除味。不同产品各有侧重,如莱克C9适合多猫家庭,霍尼韦尔H-CatHub侧重智能体验,舒乐氏Umi也具备相应功能。