Gemma 4到DeepSeek V4:近期大语言模型架构重大演进盘点

许多开发者在实际使用大语言模型时,都面临一个共同的痛点:无论模型的上下文窗口(Context Window)设计得多大,似乎总是不够用,长文本处理能力始终是瓶颈。
这背后折射出一个核心矛盾:用户渴望模型具备更强的“记忆力”和更连贯的对话能力,因此希望上下文越长越好。然而,对模型架构而言,处理长上下文意味着高昂的代价——用户每多使用一倍的Token,背后就需要翻倍的KV缓存(Key-Value Cache),注意力(Attention)计算的开销也会急剧攀升,导致推理成本暴涨。
尤其在当前,AI智能体(AI Agent)和复杂推理任务逐渐成为主流应用场景,长上下文支持已不再仅仅是宣传的噱头,而是大模型底层架构必须攻克的核心技术难题。
近期,一批新发布的开源大模型不约而同地将优化重点放在了长上下文效率上。从Google的Gemma 4,到Poolside的Laguna XS.2、Zyphra的ZAYA1-8B,再到备受瞩目的DeepSeek V4,这些模型都在Transformer架构内部进行了精妙的“手术式”改造,目标直指降低长序列推理的成本。
Gemma 4:跨层共享KV缓存与逐层嵌入技术
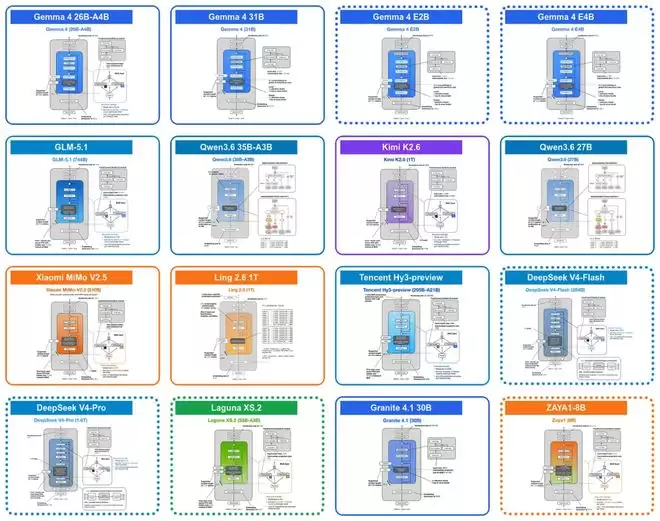
今年四月,Google推出了全新的开源大模型系列Gemma 4。该系列主要分为三类:面向移动和嵌入式设备的轻量级模型Gemma 4 E2B与E4B;采用混合专家(MoE)架构、主打高效本地推理的Gemma 4 26B;以及采用密集架构、追求更高模型性能的Gemma 4 31B。
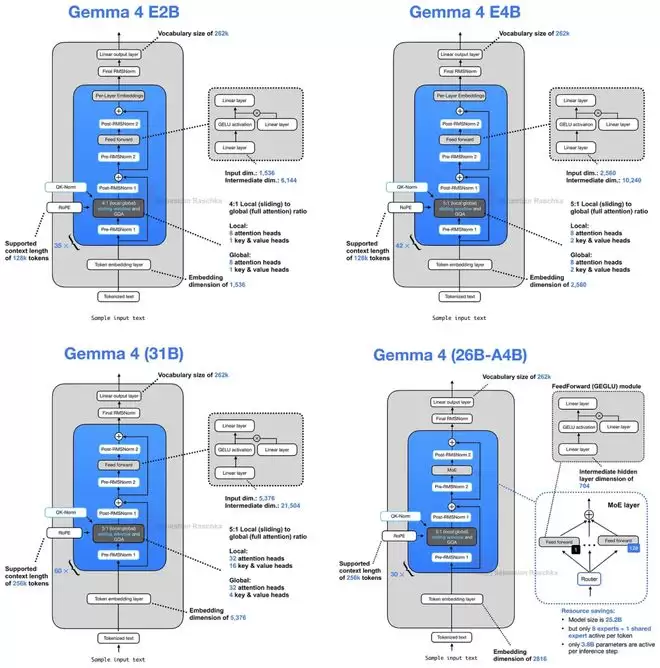
其中,面向小参数规模的E2B和E4B版本引入了一项关键创新:跨层KV共享(Cross-Layer KV Sharing)。简而言之,后续的Transformer层可以直接复用前面层已经计算好的Key和Value状态,而非每层都独立计算一遍。这能显著降低长上下文场景下的显存占用和计算开销。
这一思路并非Gemma首创,但它是首次被大规模应用到主流开源模型架构中。其核心目标非常明确:压缩KV缓存体积。KV缓存是支撑长上下文推理的显存消耗大户,缩小它就意味着能用同等硬件资源处理更长的文本序列。此前常见的分组查询注意力(GQA)也是基于类似逻辑,通过让多个查询头共享一组KV头来减少缓存大小。
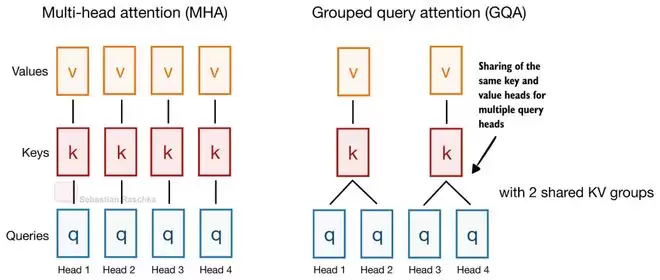
Gemma 4在GQA的基础上更进一步。它不仅在不同注意力头之间共享KV,更在不同Transformer层之间共享KV投影(Projection)。具体实现上,模型会交替使用滑动窗口注意力(Sliding Window Attention)和全局注意力(Global Attention)。滑动窗口层会复用前面某个滑动窗口层的KV,全局注意力层则复用前面某个全局注意力层的KV。每一层仍然独立计算自己的查询(Query)投影,因此能保持不同的注意力模式,但计算代价最高的KV缓存却被多个层共同分担了。
以Gemma 4 E2B为例,其35层Transformer中,只有前15层会计算自己的KV投影,后20层则直接复用。这种设计大约能将KV缓存的总大小减少一半。在128K上下文长度、bfloat16精度下,E2B模型能节省约2.7GB显存,E4B模型则能节省约6GB。
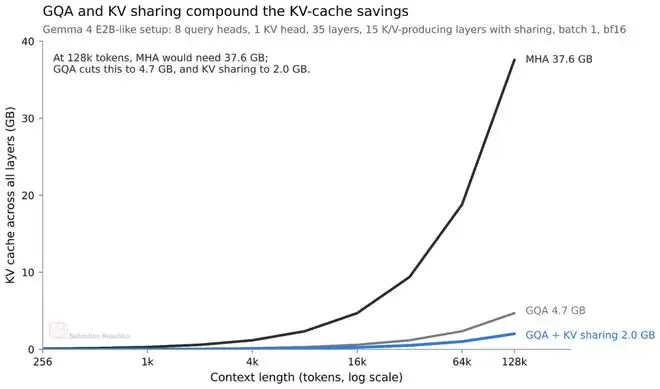
当然,这种共享本质上是对完整注意力计算的一种近似,理论上可能会轻微削弱模型的表达能力。不过,相关研究论文的实验结果表明,在小规模模型上,这种性能影响可以控制在非常有限的范围内。
除了KV共享,Gemma 4 E2B/E4B还引入了另一项以提升参数效率为导向的设计:逐层嵌入(Per-Layer Embedding)。这项技术与KV共享相互独立。
这两个版本型号中的“E”代表“有效参数量”。例如,Gemma 4 E2B标注为23亿有效参数,但若计入嵌入参数,总参数量实际达到51亿。其核心思路是:让承担主要计算的Transformer主干保持较小的规模以控制成本,同时通过一个额外的、每层独立的嵌入查找表(Embedding Lookup Table)来为模型注入更多与Token相关的特征信息,从而提升整体表达能力。
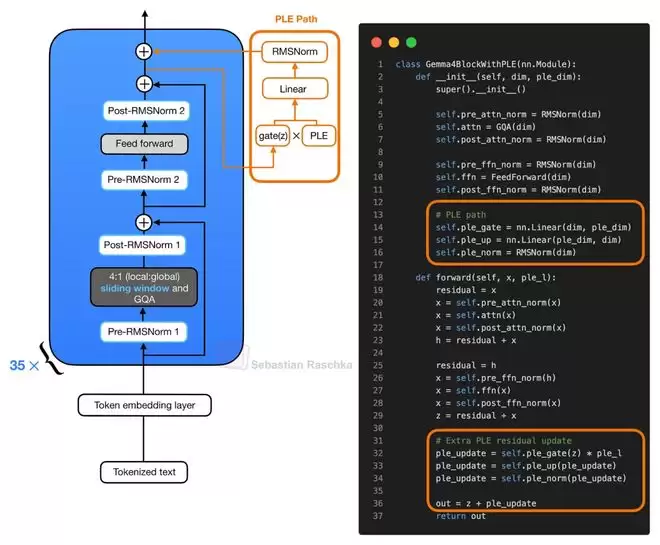
具体来说,模型会为每个输入Token预先计算一个打包好的张量,其中包含了每一层对应的一小段嵌入向量。在Transformer块中,当常规的前馈网络(FFN)残差更新完成后,当前的隐藏状态会作为一个门控(Gating)信号,来控制该层特定的嵌入向量,并将其投影后作为一次额外的残差更新加入模型。
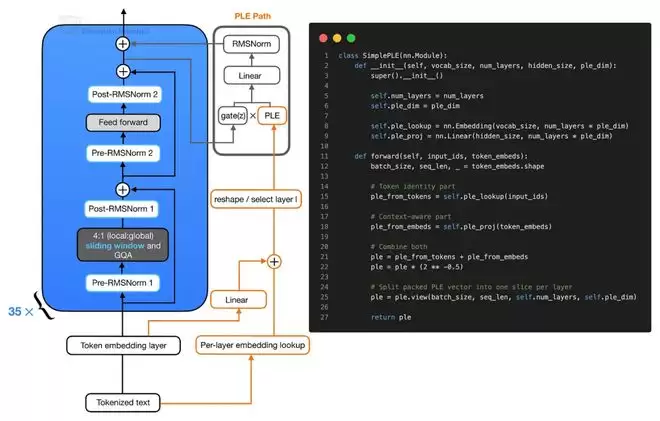
可以这样理解:模型的主体计算部分保持轻量,而将额外的“知识容量”存储在相对廉价的嵌入查找表中。这比直接扩大注意力层或前馈网络的宽度要划算得多。当然,这种设计在更大参数模型上的收益是否依然显著,还有待更多对比实验的验证。
Laguna XS.2:分层注意力预算分配
来自欧洲公司Poolside的Laguna XS.2是另一个值得关注的模型。初看其架构相当标准,但隐藏着一个巧妙的细节:分层注意力预算(Layered Attention Budget)。
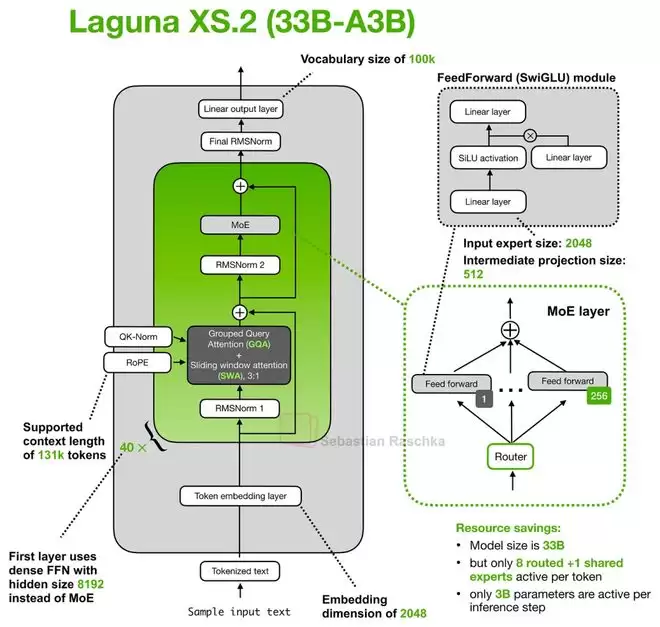
该模型共有40层,其中30层使用滑动窗口注意力,10层使用全局注意力。这本身是常见的混合设计。但新颖之处在于,模型为不同类型的层分配了不同数量的查询头(Query Heads)。
全局注意力层因为需要关注整个上下文,计算成本本就高昂,因此被分配了较少的查询头;而计算成本较低的滑动窗口注意力层,则可以“奢侈”地拥有更多查询头。在Laguna XS.2中,KV头的数量被固定为8,但查询头的数量则根据层类型动态调整。
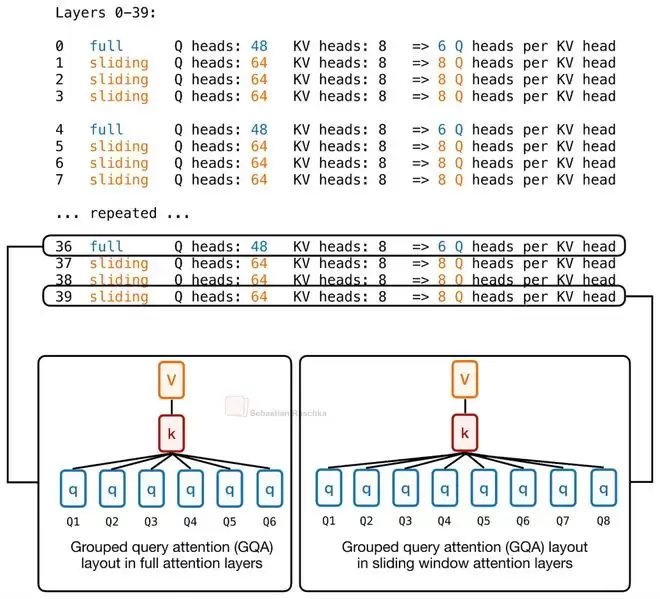
这种设计的核心逻辑与KV共享一脉相承:将宝贵的注意力“算力”进行精细化预算管理,而不是在所有层上平均分配。让计算密集的层“轻装上阵”,让计算廉价的层“多担重任”,从而在整体上优化模型效率。这种按层动态分配模型容量(Model Capacity)的思路,其实在更早的一些研究中已有体现。
ZAYA1-8B:压缩卷积注意力机制
Zyphra公司发布的ZAYA1-8B带来了一种名为压缩卷积注意力(Compressed Convolutional Attention, CCA)的新机制。它与分组查询注意力(GQA)结合使用,目标是从注意力机制本身入手降低成本。
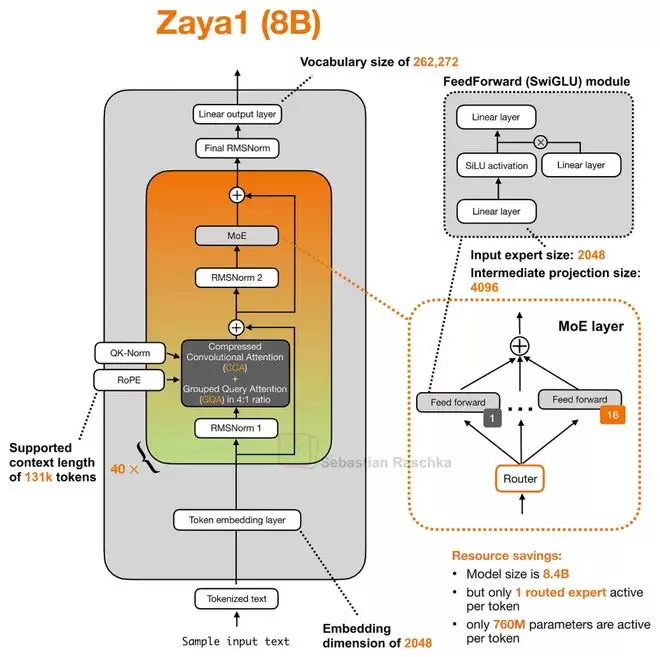
CCA的核心思想是在一个压缩后的潜在空间(Latent Space)中执行注意力计算。这与DeepSeek模型使用的多头潜在注意力(MLA)有相似之处,但走得更远。MLA主要将潜在表示作为压缩KV缓存的格式,在计算注意力前仍需将其投影回原始空间。而CCA则直接对压缩后的Q、K、V进行注意力运算,生成的压缩注意力向量再被上投影(Upsample)回去。这种方法不仅能减少KV缓存,还能显著降低预填充(Prefill)阶段和训练阶段的注意力计算量。
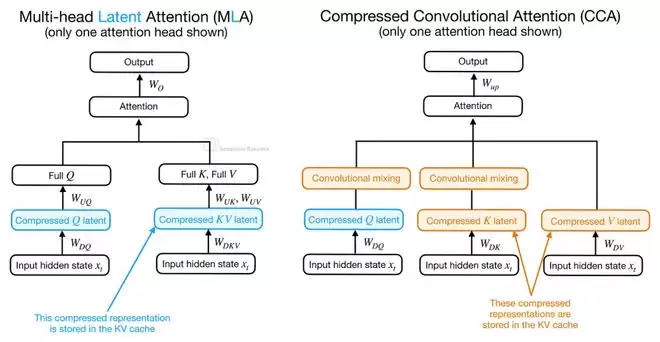
为什么叫“卷积”注意力?因为它在压缩后的Q和K张量上,额外施加了卷积混合(Convolutional Mixing)操作。压缩虽然降低了计算和缓存开销,但也可能削弱注意力的表达能力。卷积作为一种相对廉价的操作,能在Q和K用于计算注意力分数之前,为这些压缩表示补充局部上下文信息,从而缓解信息损失。

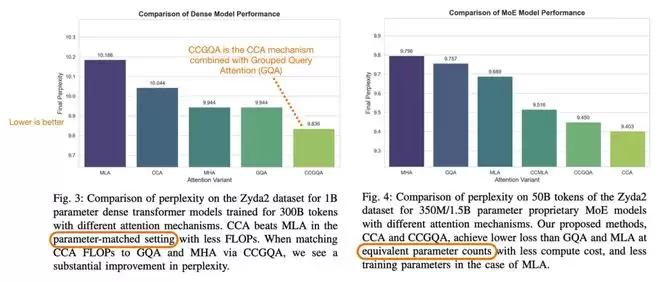
根据相关论文的实验结果,在相同的压缩设置下,CCA的表现优于MLA。ZAYA1-8B还采用了非常稀疏的MoE结构。简而言之,它不仅在FFN层上节省计算量,更是从注意力机制这个源头开始追求极致效率。
DeepSeek V4:流形约束超连接与压缩注意力
DeepSeek V4无疑是今年大模型领域的焦点之一。为了聚焦于架构革新,我们重点关注其两项新设计:用于扩展残差路径的流形约束超连接(Manifold-Constrained Hyper-Connection, mHC),以及用于长上下文压缩的CSA/HCA注意力。
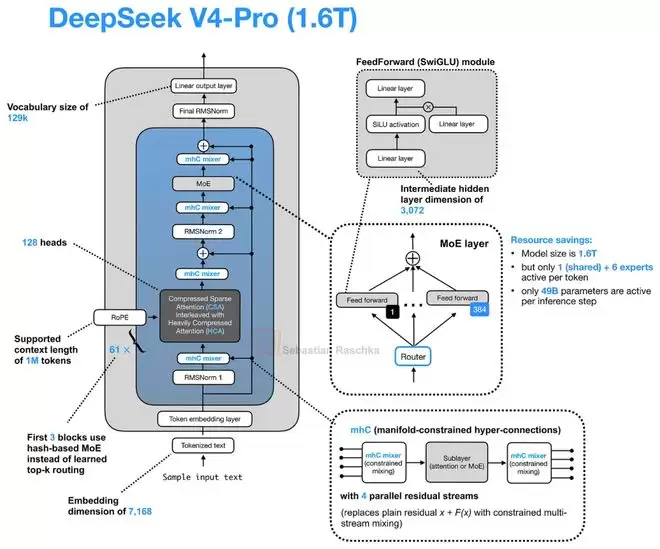
mHC:重新设计残差连接
mHC的目标是重构Transformer块内部的残差连接(Residual Connection)。近年来大多数架构改进都集中在注意力、归一化或MoE上,对残差连接进行改造的比较少见。
mHC建立在“超连接(Hyper-Connection, HC)”的思想之上。传统Transformer只有一条残差流,而HC将其扩展为多条并行的残差流,并通过可学习的映射在它们之间交换信息。其目的是在不显著扩大注意力或MoE层本身宽度的情况下,增强残差路径的表达能力。由于额外的映射只作用于较小的残差流维度,带来的计算量增长非常有限。
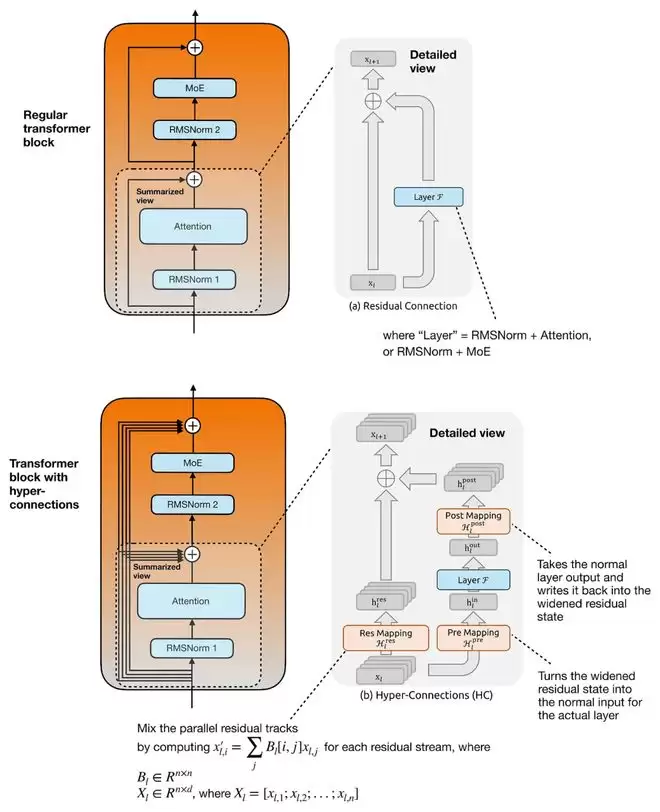
mHC的关键改进在于为这些映射添加了约束。在普通HC中,用于混合不同残差流的映射矩阵是无约束的,在深层堆叠时可能导致信号被不可预测地放大或衰减。mHC则将其约束在“双随机矩阵(Doubly Stochastic Matrix)”的流形上,确保所有元素非负且每行每列之和为1。这使得残差混合更像一种稳定的信息再分配,提升了在大规模深度模型中的训练稳定性。
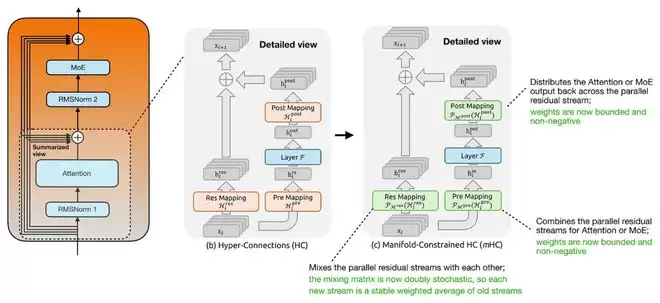
实验表明,即使使用4条残差流,在优化后训练时间的额外开销也仅增加约6.7%,但能带来模型性能的稳定提升。
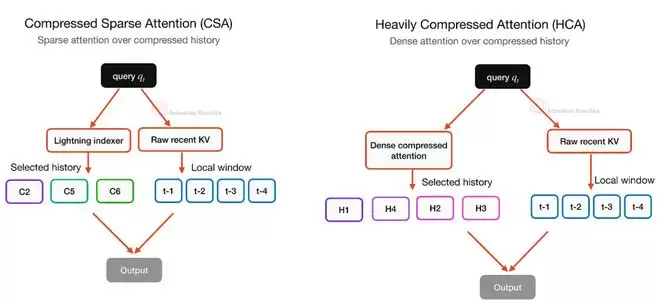
CSA与HCA:序列维度的压缩
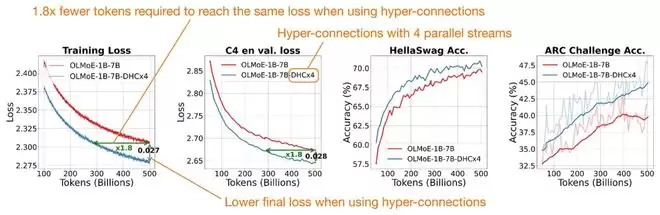
DeepSeek V4在注意力机制上的升级,动机同样明确:应对超长上下文的成本。其引入的压缩稀疏注意力(Compressed Sparse Attention, CSA)和重度压缩注意力(Heavily Compressed Attention, HCA),与V2/V3中使用的MLA思路不同。
MLA压缩的是每个Token的KV表示,但依然保持“一个Token对应一个潜在KV项”。而CSA和HCA压缩的是序列维度本身。它们将一组Token汇总(Summarize)成更少的压缩KV项,从而直接缩短了整个缓存序列的长度。
这当然会损失一些Token级别的细节信息,但换来了长上下文成本的大幅下降。为了平衡效率与质量,DeepSeek V4没有只依赖一种机制,而是交替使用CSA和HCA。
CSA采用较轻的压缩率,并结合稀疏选择器;HCA则采用更激进的压缩(例如每128个Token压缩为一项),但能在压缩后的序列上进行密集注意力计算。两者都保留了一个局部滑动窗口分支来处理最近的未压缩Token。
根据论文数据,在100万Token的上下文下,相比采用MLA和DSA的DeepSeek V3.2,DeepSeek V4-Pro的单Token推理计算量仅为前者的27%,KV缓存大小仅为10%。而DeepSeek V4-Flash版本更是将这两个数字进一步降至10%和7%。
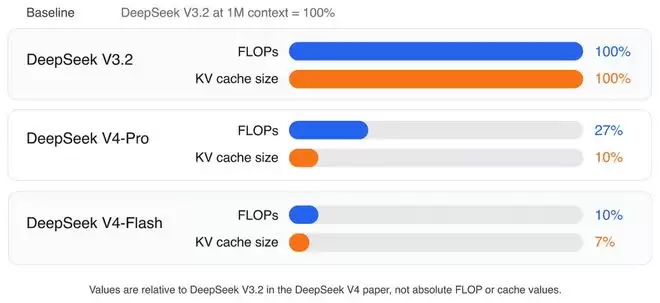
需要指出的是,这些卓越的成绩是模型整体改进(包括数据、训练优化、mHC、精度优化等)的共同结果。CSA/HCA可以看作一种为极致长上下文效率而生的、更为激进和复杂的设计。
总结与趋势展望
纵观2026年这批新的开源大模型,一个清晰的趋势浮现出来:降低长上下文成本已成为大模型架构创新的核心驱动力,而且实现方式不再是简单地缩小模型尺寸,而是通过一系列精细的结构化优化。
从Gemma 4的跨层KV共享和逐层嵌入,到Laguna的分层注意力预算,再到ZAYA1的压缩卷积注意力,以及DeepSeek V4的mHC和CSA/HCA组合拳,Transformer基础块正在持续演化,并且演化方向越来越有针对性,旨在实现高效的长文本理解与生成。
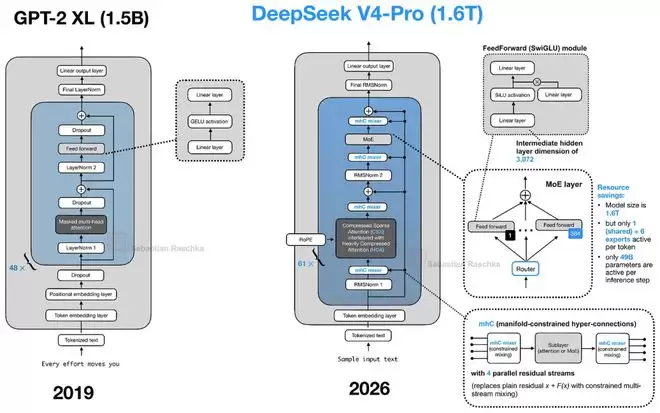
相比GPT-2时代几十行代码就能实现的简洁架构,如今这些注意力变体的代码复杂度可能增长了十倍。但这种复杂化并非为了增加成本,恰恰相反,是为了在可控的成本内实现真正的超长上下文推理能力,推动大模型在文档处理、代码生成、多轮对话等场景的落地。当然,理解这些组件本身以及它们之间如何协同工作,也正变得越来越有挑战性。这或许就是追求极致效率与性能所必须面对的“甜蜜的负担”。
热门专题







热门推荐

东南亚智能手机市场第一季度平均售价同比上涨19%,达349美元。出货量虽下滑9%,但市场总规模增长8%,呈现“量减价增”态势。这表明消费者开始转向高端机型,市场增长动力正从销量扩张向价值提升转变。

代币归属期指代币在发行后按预定时间表逐步解锁的过程。该机制旨在激励项目长期发展,防止早期投资者或团队成员大量抛售导致市场波动。归属期通常包含锁定期与释放期,具体规则由项目方设定。理解此概念有助于评估代币的潜在流通量与市场风险。

近日,小鹏汽车正式宣布,基于其旗舰SUV车型GX打造的首款Robotaxi(自动驾驶出租车)量产车已成功下线。这一重要进展标志着中国L4级高阶自动驾驶技术的商业化落地,迈出了坚实而关键的一步。 根据官方披露的核心信息,这款自动驾驶车型创造了多项行业纪录:它不仅是中国首款实现全栈自研、前装量产的Rob

5月19日,一则新闻引发广泛关注与讨论:河南濮阳一位主营冷冻榴莲果肉的商家,因遭遇买家恶意发起“仅退款”操作,在沟通无果后,选择驱车数百公里前往山东进行维权。几乎在同一时间,浙江杭州萧山区盈丰街道,也因类似恶意退货退款问题频发,被部分电商商家列入“交易谨慎名单”。这两起典型事件,将长期存在于电商交易

5月19日,AMD完成了一项具有里程碑意义的战略举措:首次将其年度AI开发者大会的主会场设在中国。在上海,AMD董事会主席兼首席执行官苏姿丰博士发表了核心主题演讲,其中所传递的战略信号,其深远意义远超单纯的技术发布。 贯穿整场演讲,一个核心信息被不断强化:中国市场对于AMD的全球战略重要性,已提升至