大语言模型如何实现类人对话与思考的智能原理

我们每天都在与大语言模型(LLM)对话,一个直观的感受是,它们似乎真的“懂”我们在说什么,尽管偶尔也会“胡言乱语”。观察它们输出的思维链,那种逐步推理的语言痕迹,更让人觉得它们仿佛具备了某种思考能力。
这引出了一个核心问题:LLM的语言和思考能力,究竟是一种怎样的能力?这些能力又是如何通过其底层的实现原理、乃至复杂的工作机制形成的?最近,字节跳动的研究团队发表了一篇综述文章,对这些问题进行了深入探讨。
必须承认,LLM是人类智慧的造物,其实现原理是清晰的,但内部工作机制(Mechanics)至今仍像一个未被完全解开的谜。模型规模极其庞大,内部运作极其复杂,这给理解其能力本质带来了巨大挑战。
自ChatGPT问世以来,关于LLM机制和特性的研究已呈井喷之势,特别是在可解释性方面。这些工作从不同角度,为我们理解这个AI“黑箱”提供了宝贵的线索。当然,仍有大量问题悬而未决,等待后续探索。
该文章系统梳理了LLM的基本原理与实现方法,并简要介绍了当前工作机制研究的前沿进展,其中也包括字节跳动团队在记忆机制方面的最新工作。在此基础上,文章对LLM能力的形成提出了独到的见解。
1 核心观点:超越统计,理解模式
文章的核心论点可以概括为以下几点。
首先,LLM学习的本质是语言使用和推理的“模式”,尤其是高阶模式。作为一种机器学习模型,其学习成果归根结底是数据中的统计规律,或者说模式。但语言数据包罗万象,涵盖了词汇、语法、语义、语用乃至世界知识。我们发现,LLM不仅学会了低阶的词汇语法模式,更掌握了与语义、语用和知识相关的高阶模式。这正是ChatGPT及后续模型“涌现”出惊人能力的关键,而早期的语言模型往往难以企及。因此,那种认为LLM只学到了语言形式而未触及内容的观点(例如乔姆斯基的批评),现在看来是站不住脚的。
其次,用“下一个词预测”(NTP)来概括LLM固然简洁,但过于简化了。其整体能力是由策略、模型、算法及数据共同塑造的系统工程。预训练中的极大似然估计(本质是数据压缩)负责拟合词元序列的概率分布;后训练的强化学习则微调模型,使其成为生成最优词元序列的策略函数。Transformer模型本身拥有强大的表示能力,随机梯度下降算法则帮助找到泛化性良好的解。LLM的成功,关键在于对这些尖端技术的系统性整合与规模化实践。将一切归功于NTP,无疑是忽视了技术全景的复杂性。
再者,LLM的内部机制正在被逐步解析,它已不再是一个完全的黑箱。近年来,可解释性研究取得了实质性进展。通过稀疏自编码器(SAE)等工具,我们可以提取模型内部的特征;利用跨层转码器(CLT)等方法,能够追踪特征之间形成的计算回路。字节跳动的最新工作更进一步,揭示了LLM如何围绕“功能词元”进行记忆的存储与检索。随着研究的深入,这个复杂系统的面纱正被一层层揭开。
2 窥探黑箱:LLM的工作机制研究
理解LLM,可以从三个视角切入:机器学习方法与理论、外部提示的实验分析,以及内部工作机制的研究。如果把LLM比作人脑,那么工作机制的研究就相当于脑科学实验,试图直接观察“神经元”如何放电与连接。
2.1 特征叠加:神经元的“兼职”艺术
神经网络中存在着一个有趣的现象:“特征叠加”。传统观点认为,一个神经元对应一个特征。但大量实验表明,这种理想情况很少见。现实中,神经元与特征是多对多的关系:一个神经元可能参与表示多个特征,而一个特征则由多个神经元共同表示。

图1:LLM的语言和思考能力、工作机制、实现原理和方法之间的关系。
Anthropic团队提出的“特征叠加假说”解释了这一现象。其核心思想是:通过让神经元“兼职”,神经网络的一层可以近似表示远多于其神经元数量的特征,代价是特征之间会存在一定的干扰。
从数学上看,一层神经网络(实际层)可以表示为多个“虚拟特征向量”的稀疏组合。在训练过程中,梯度下降算法会驱使网络在“表示更多特征”和“使用更少神经元”两个目标之间寻找平衡,特征叠加便成为一种自然的优化结果。此外,ReLU等激活函数会促使特征表示变得稀疏,进一步支持了这种“压缩”表示。
这一假说不仅在Anthropic的玩具模型中得到验证,更为后续稀疏自编码器(SAE)的开发与应用提供了理论基础。
2.2 SAE:特征的“解压”与发现
如果说特征叠加是一种“压缩”过程,那么稀疏自编码器(SAE)就是与之配套的“解压”工具。在LLM可解释性研究中,SAE常被用于分析Transformer各层的输出表示,从中发现具有可解释性的特征。
SAE由编码器和解码器构成。编码器通过非线性变换,将输入向量转换为一个高维且稀疏的特征向量(即激活了少数特征)。解码器则试图从这个稀疏特征向量中重建原始输入。通过优化重建误差和稀疏性约束,SAE能够学习到一组可以解释模型内部活动的特征基。
研究发现,通过SAE提取出的海量特征(可达数十万至百万级)中,许多具有清晰的语义。例如,研究者识别出了与“金门大桥”或“谄媚”行为相关的特征。这些特征并非随机分布,而是呈现出层次化结构:浅层多对应词法和简单语法;中间层涉及复杂语法和基本语义;深层则主要承载复杂语义、推理逻辑和输出表达。
2.3 记忆机制:功能词元是关键“开关”
字节跳动的研究提出了“功能词元假说”,为理解LLM的记忆机制提供了新视角。该假说认为,LLM中特征的记忆是围绕功能词元组织的,而在推理时,记忆的检索也同样通过功能词元触发。
什么是功能词元?它们通常是训练语料中间出现频率最高的词元,大部分对应语言学中的功能词,如冠词“the”、标点符号、换行符等,在语法和上下文连接中起关键作用。与之相对的是承载具体语义的内容词元。据统计,前100多个高频功能词元就能覆盖约40%的预训练语料出现次数。
研究发现,在预训练阶段,模型的学习呈现出以功能词元为中心的特点。最困难的学习任务是“根据功能词元预测下一个内容词元”。这很合理,因为功能词元往往标志着一个语言单元(Chunk)的结束,预测其后的内容需要对整个上文有准确理解。正是这个最艰巨的任务,主导了模型的优化方向。
另一个关键发现是,功能词元在训练中逐渐获得了激活大部分特征的能力。想象一个二部图,一边是功能词元,一边是特征。如果某个功能词元在某个上下文中激活了某个特征,两者之间就建立一条连接。随着训练进行,连接数迅猛增长。最终,少数高频功能词元能与超过70%的特征建立连接,这意味着它们能在不同上下文中激活模型内部的大部分知识。
在推理时,功能词元便扮演了记忆检索“开关”的角色。它们能根据当前上下文,动态激活最相关的特征,并抑制无关特征,从而指导下一个词元的生成。例如,当提示为“用中文回答:俄罗斯的首都是什么?”时,提示中的冒号和换行符等功能词元,会激活“中文回答”和“俄罗斯”等相关特征,最终引导模型输出“莫斯科”。
功能词元的核心地位,是训练目标、学习算法、模型架构和语言特性共同作用的结果。Transformer的前馈网络层擅长表示和记忆知识(特征),自注意力层则善于将低阶特征组合成高阶特征。而自然语言本身由功能词元分割成嵌套Chunk的结构特性,使得对功能词元之后的预测成为驱动模型深度理解的关键。
这一假说对训练实践有重要启示:数据的格式至关重要。后训练(如指令微调)只需少量步骤就能大幅提升模型能力,很可能是因为它调整了功能词元的激活模式,从而唤醒了预训练中学到但未被充分利用的特征。
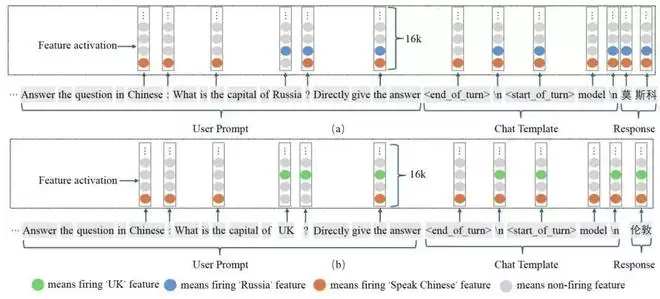
图3:LLM推理过程中功能词元发挥着记忆检索的核心作用。
2.4 CLT:追踪跨层的特征“回路”
SAE主要分析单层特征,要理解特征如何跨层协作形成“回路”,就需要像CLT(跨层转码器)这样的工具。回路是指LLM中跨层连接特征的计算图,它描述了特征如何被激活并在网络中传播。
CLT的工作原理是:以某一层的中间表示作为输入,学习一个能够同时复现后续多个层输出的映射。它每一层都有一个类似SAE的特征抽取模块,但优化目标是让抽取的特征能跨层对齐,从而捕捉特征在不同层间的演变与影响关系。
通过CLT,研究者可以构建“归因图”,直观展示对于特定输出,哪些特征在哪些层被激活,并如何沿着路径传递。为了提高可读性,通常会使用剪枝技术保留最重要的节点和路径。这种分析能清晰揭示模型在完成特定任务时,其内部的核心计算回路是怎样的。
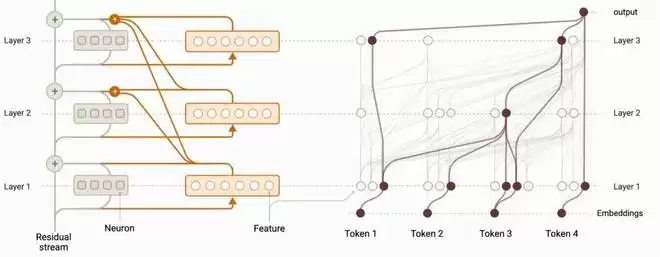
图4:基于CLT构建的归因图,用于分析LLM的内部计算机制。
3 LLM的能力本质:与人类的同与异
3.1 能力之源:高阶模式与系统整合
从行为上看,LLM在诸多语言与推理任务上已达到甚至超越人类水平。如果以图灵测试为标准——即在对话中难以与人类区分——那么许多LLM已然合格。
关键在于,LLM掌握的是高阶模式。无论是理解“喜马拉雅山有多高,用英文回答”这样的指令(语用能力),还是辨析“金门大桥与金拱门的关系”这类问题(语义与知识整合),都超出了简单的统计搭配。内部机制分析也佐证了这一点,“金门大桥”、“谄媚”等概念特征的存在,明确显示了模型对语义和语用的编码。
因此,认为LLM只学到表层统计规律的观点并不准确。当然,这并不意味着LLM的机制与人类相同。人脑的语言处理依赖布洛卡区、韦尼克区等特定脑区的分工协作,这与Transformer的架构有根本区别。
要理解LLM的整体能力,需要从训练、策略、算法和模型四个维度系统看待(见图5)。预训练让模型从海量数据中学习统计规律;后训练(如RLHF)则调整其生成策略,使其输出更符合人类偏好。Transformer模型通过自注意力实现特征组合,通过前馈网络进行非线性变换,多层结构则形成了层次化的表示。所有这些要素,共同铸就了LLM的类人能力。
图5:LLM的机制可以从训练方式、策略、算法和模型来理解。
此外,规模效应不容忽视:数据量、参数规模和计算资源的增加,能带来能力的质变。数据质量和训练技巧(如提示设计)也至关重要。最终,模型内部形成了海量特征,它们根据不同的上下文被动态激活、组合成回路,从而实现了复杂的语言处理和推理。
3.2 与人类能力的多维对比
下表对比了LLM与人类在不同能力维度上的表现。可以看出,在纯语言和推理任务上,LLM已堪比拟甚至超越人类。但在其他方面,两者的机制和性能差异显著,不能简单类比。
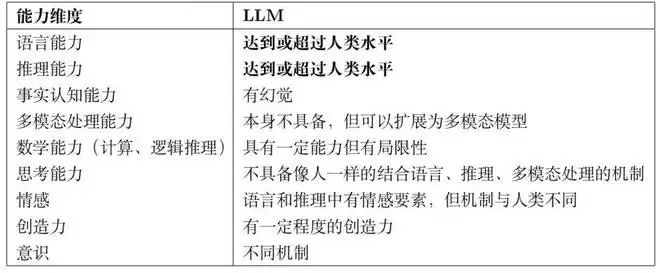
表1: LLM与人类能力比较
幻觉问题:其本质是事实判断错误。由于LLM学习的是统计规律,理论上在生成过程中必然以一定概率产生幻觉。模型自身无法根除这一问题,但可通过检索增强生成(RAG)等外部机制缓解。
思考与认知:人类的思考是“具身”的,与视觉、听觉、触觉等感官及运动系统紧密相连。当前的多模态大模型(MLLM)虽能关联语言与视觉、听觉信息,但其推理仍主要发生在语言表示空间,与人类基于丰富感官经验的、有意识的思考过程有本质不同。
逻辑与计算:LLM并非基于形式逻辑规则或算术规则进行推理运算。它通过生成机制模拟出一定的启发式推理和计算能力,但在处理复杂问题时,因缺乏严谨性而易出错。这是其内在局限性。
创造力:这取决于如何定义。LLM无疑具备“渐进式创新”能力,能在现有模式上组合出新内容。但能否实现“碘伏式创新”(如提出相对论),目前仍是开放问题。正如Ilya Sutskever所言,LLM擅长“插值”,但“外推”能力未知。
意识:LLM没有意识。我们感觉在与真人对话,那只是一种交互错觉。意识是人脑神经系统高层次处理产生的、主观的、持续的自我知觉状态。全局工作空间理论认为,意识是脑内信息的全局广播。目前的LLM架构中,不存在产生这种主观体验的机制。
相关攻略

大语言模型(LLM)已成为人工智能领域的热点,但你真的清楚它们具备哪些核心能力吗?本文将系统解析大语言模型的七大关键能力,帮助你深入理解它们如何“思考”、理解与创造。 文本生成能力 这是大语言模型最突出的能力之一。通过学习海量文本数据,模型能够生成语法准确、逻辑连贯且贴合上下文的自然语言内容。无论是

在人工智能技术飞速发展的今天,生成式语言模型已成为自然语言处理(NLP)领域的核心驱动力。与传统的文本分类或理解模型不同,生成式AI的核心能力在于“创造”。它通过深度学习海量语料,掌握语言的深层规律与模式,从而能够根据用户输入的提示或上下文,自主生成逻辑通顺、语义连贯且富有创造性的全新文本内容。 一

回望大语言模型走过的路,你会发现它并非一蹴而就,而是一段清晰可辨、层层递进的演进史。粗略来看,这段历程可以划分为三个关键阶段,每个阶段都代表着一次技术上的质变和应用疆域的拓展。 一、基础模型阶段 时间大概在2017年到2021年之间。这个阶段的核心任务,是打好地基。 一切的起点,是2017年那篇里程

近年来,人工智能领域最具突破性的进展之一,当属大语言模型的飞速发展与广泛应用。它从一个前沿研究概念,迅速演变为驱动自然语言处理技术革新和产业智能化转型的核心引擎。这一变革的背后,是算法架构的突破、海量数据的积累与强大算力支撑共同作用的结果。本文将系统性地解析大语言模型的崛起背景、核心技术、应用实践以

自然语言处理领域近年来迎来了一项革命性技术——大语言模型。随着深度学习技术的持续演进,这类模型通过海量文本数据训练,不仅能生成和理解自然语言,更在文本摘要、机器翻译、情感分析等复杂任务中展现出惊人潜力。本文将深入探讨其核心技术、应用场景以及可能带来的社会影响。 揭秘大语言模型的“黑箱” 尽管功能强大
热门专题







热门推荐

广东无人机适飞空域扩大16%至10 24万平方公里,覆盖全省57%陆地面积,滨海、郊野、工业园区及非核心城区公园等区域开放,深圳市区新增连片适飞区。飞行需通过民航局UOM平台提前申请,严禁“黑飞”,违者将受处罚。平台已升级,实现全国规则统一与分钟级空域更新,支持低空物流与巡检等应用。

杭州Costco门店因iPhone17系列手机引发抢购热潮,数百人排队致迅速断货。抢购源于官方降价与地方补贴叠加:iPhone17Pro全系直降千元,同时当地青年消费补贴可再减10%,最高省千元。双重优惠下,256GB版iPhone17Pro到手价低至7172元,较电商平台便宜近千元,吸引本地及周边消费者。目前门店仍处缺货状态,补货时间未定。

5月17日晚,长征八号运载火箭在海南商业航天发射场点火升空,成功将千帆星座第九批组网卫星送入预定轨道。此次发射是该发射场启用以来的第15次成功发射,也是今年第5次发射,体现了我国商业航天发射能力的日益成熟和常态化运营的稳步推进。

七彩虹新款iGameM15 M16Origo2026款游戏本已发售,起售价11499元。M15为15 3英寸黑色机身,配备2 5K300Hz屏,最高可选Ultra9处理器与RTX5070显卡。M16为16英寸白色款,屏幕规格相同,处理器性能更强,电池容量更大。两款均提供多种配置,享受国家补贴后价格更具竞争力,面向中高端游戏玩家与创作者。

联想在北美市场推出新款ThinkPadT14Gen7商务笔记本,支持用户自行更换LPCAMM2内存。该机型提供多款英特尔酷睿Ultra处理器选项,内存可选16GB至64GB,电池与屏幕亦有多种配置,其中顶配版搭载OLED屏幕。产品起售价为1618美元,高配版本价格超过3700美元,主要面向商用及专业办公市场,兼顾性能、可升级性与不同预算需求。