回望大语言模型走过的路,你会发现它并非一蹴而就,而是一段清晰可辨、层层递进的演进史。粗略来看,这段历程可以划分为三个关键阶段,每个阶段都代表着一次技术上的质变和应用疆域的拓展。
一、基础模型阶段
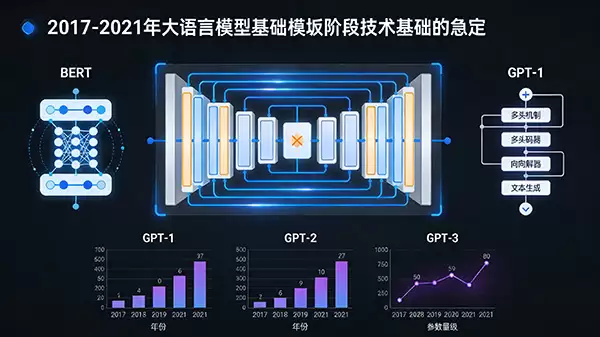
时间大概在2017年到2021年之间。这个阶段的核心任务,是打好地基。
一切的起点,是2017年那篇里程碑式的论文。Vaswani等人提出的Transformer架构,最初在机器翻译任务上大放异彩。谁也没想到,这个摒弃了循环和卷积的纯注意力机制模型,会成为后来所有大语言模型的“心脏”。
地基打好,高楼便有了蓝图。2018年,Google的BERT和OpenAI的GPT-1几乎同时登场,正式拉开了预训练语言模型时代的序幕。它们的思路很巧妙:让模型先在海量无标注的文本数据里“自学成才”,掌握通用的语言规律和世界知识,然后再针对特定任务做微调。这好比先让一个学生博览群书,建立通识,再让他去专攻某个学科。
当然,这个阶段的另一个鲜明主题是“变大”。模型的参数量,成了衡量能力的一个直观标尺。从GPT-1的1.17亿参数,到GPT-2的15亿,再到GPT-3令人咋舌的1750亿——参数量的指数级增长,带来的不仅是性能的飙升,更是一种“涌现”能力的质变:模型开始展现出惊人的泛化能力和逻辑推理雏形。
二、能力探索阶段
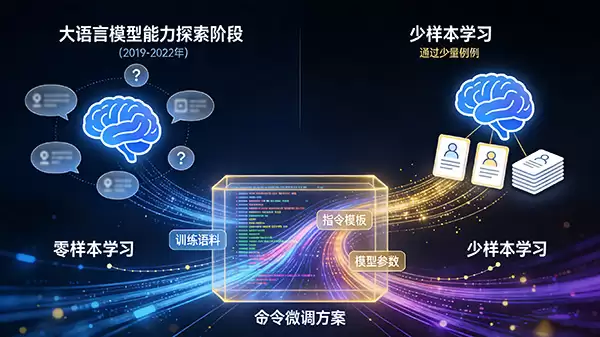
时间大致从2019年延续到2022年。当地基足够坚实,研究者们开始思考:这座大厦到底能有多高的上限?能用来做什么?
于是,“零样本”和“少样本”学习成为热门探索方向。简单说,就是不给模型看任何任务示例(零样本),或者只给极少数例子(少样本),看它能否直接理解并完成任务。GPT-2和GPT-3在这方面展现了巨大潜力,证明了大模型本身蕴含的、无需额外训练的通用任务理解能力。
但如何更精准地“唤醒”这种能力呢?“指令微调”应运而生。研究者们将五花八门的任务(比如翻译、总结、问答)都统一成“听从自然语言指令并生成结果”的格式,然后用海量的指令数据对模型进行微调。这相当于给模型进行了一次“岗前通用培训”,让它能更好地听懂人话,执行复杂指令。模型的实用性和可控性,由此迈出了一大步。
三、突破发展阶段
以2022年11月ChatGPT的横空出世为标志,这个阶段一直持续至今,其特点就是技术突破与大众化应用并驾齐驱。
ChatGPT的成功,与其说是技术上的绝对创新,不如说是工程化和体验设计的胜利。它通过一个极其简单的对话界面,将大语言模型的强大能力——无论是回答问题、撰写文稿、生成代码还是数学推理——无缝交付给普通用户。其对话连贯性、上下文理解以及生成内容的质量,让公众第一次真切感受到AI的“智能”。
与此同时,模型的边界也在不断被打破。多模态成为新的焦点,以GPT-4为代表的模型开始能理解和生成图像、音频等多种形式的信息,向着真正的“全能型AI助手”迈进。
市场也随之被彻底点燃。在ChatGPT的示范效应下,全球科技巨头和顶尖研究机构纷纷入局,竞相发布自己的大模型产品,如Google的Bard、百度的文心一言、科大讯飞的星火大模型等。一场围绕大语言模型的竞赛全面展开,技术迭代的速度前所未有。

总而言之,从奠定基础的架构与预训练,到深入挖掘其通用潜力,再到引爆全球的突破性应用,大语言模型发展的这三个阶段,勾勒出了一条从技术突破走向社会变革的清晰轨迹。每一步,都在深刻重塑我们处理信息、与人机交互乃至创造内容的方式。




