
在人工智能技术飞速发展的今天,生成式语言模型已成为自然语言处理(NLP)领域的核心驱动力。与传统的文本分类或理解模型不同,生成式AI的核心能力在于“创造”。它通过深度学习海量语料,掌握语言的深层规律与模式,从而能够根据用户输入的提示或上下文,自主生成逻辑通顺、语义连贯且富有创造性的全新文本内容。
一、生成式语言模型的定义
究竟什么是生成式语言模型?简单来说,它是一种专门用于生成自然语言文本的人工智能模型。其核心定义在于,它不仅能够理解语言,更能基于对语法、语义和语境的综合把握,进行原创性的文本“创作”。这不同于简单的信息检索或模板填充,而是模型在深刻理解语言内在结构(包括词法、句法和篇章逻辑)后,像一位拥有渊博知识的智能写手,根据特定指令产出符合风格与主题要求的文章、对话或代码。
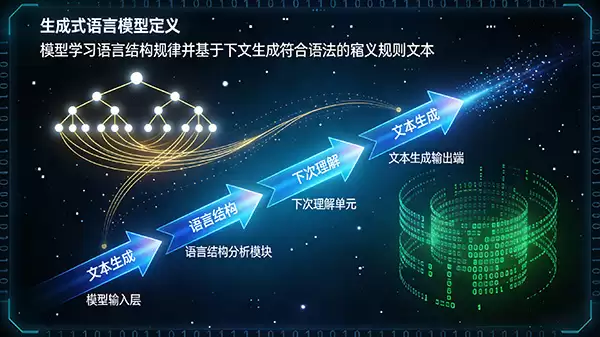
二、生成式语言模型的工作原理
生成式语言模型的强大能力源于其底层的工作原理,本质上是基于大规模数据的统计规律学习与预测。
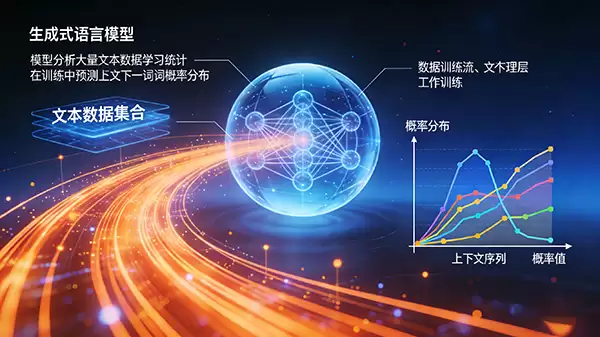
在模型训练阶段,系统会输入数以亿计的文本数据进行学习。其核心训练任务是进行“下一个词预测”:即根据已出现的上文(上下文),计算出下一个最可能出现的词语的概率分布。通过海量数据的反复迭代,模型逐渐内化了词汇间的搭配关系、句子的常见结构以及不同场景下的语言表达习惯,构建起一个复杂的语言概率模型。
当模型投入应用时,它便能基于学习到的知识进行推理。用户给出一个开头或提示(Prompt),模型便依据内部的概率网络,自回归地逐个生成后续最可能的词语序列,从而形成一段完整、流畅的新文本。因此,其生成的内容既继承了训练数据的风格与知识,又是全新的、独一无二的组合。
三、生成式语言模型的实现方式
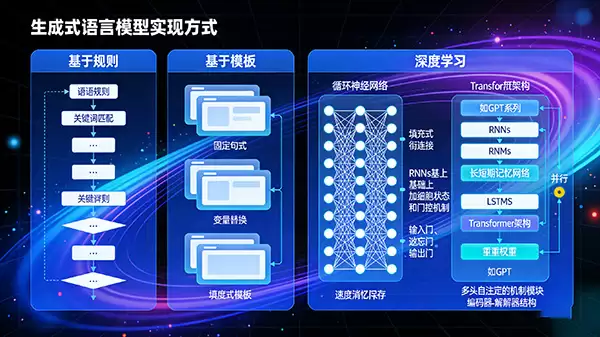
实现文本生成的技术路径经历了显著的演进。早期基于规则或模板的方法灵活性差,效果有限。真正的变革始于深度学习,尤其是神经网络架构的突破。
当前主流的生成式语言模型实现,几乎都建立在深度神经网络之上。其发展脉络清晰:从处理序列数据的循环神经网络(RNN),到改进长程依赖问题的长短期记忆网络(LSTM),再到如今占据统治地位的Transformer架构。以GPT系列为代表的Transformer模型,凭借其革命性的“自注意力机制”,能够并行处理文本并精准捕捉全局词语关系,从而在文本生成的质量、一致性和效率上实现了跨越式提升,奠定了大语言模型(LLM)时代的技术基础。
四、生成式语言模型的应用场景
生成式语言模型的应用场景极为广泛,正在重塑众多行业的工作方式与内容生产流程。
其典型应用包括:实现高质量跨语言沟通的机器翻译、自动生成文章摘要的文本总结、充当24小时在线客服的智能对话系统、辅助创作者进行小说与剧本的创意写作,乃至根据自然语言描述自动生成编程代码。所有这些应用都共享同一个核心:将用户的意图或输入信息,转化为合理、自然且有用的文本输出。

当然,我们必须清醒地认识到,现有的生成式AI模型仍存在局限性。它们可能产生“幻觉”,即生成看似合理但实则错误或虚构的信息,尤其在需要严谨事实核查和深度逻辑推理的复杂任务中。因此,在当前的实际部署中,往往需要结合知识图谱、事实校验模块或其他专项AI工具进行辅助,并在关键应用环节设置人工审核机制,以保障生成内容的准确性与可靠性。克服这些挑战,正是推动生成式语言模型迈向更成熟、更可信阶段的关键方向。




