最强开源图像生成模型GPT-Image-2平替版正式发布
全球AI图像生成领域的竞争格局,正迎来前所未有的激烈变革与范式升级。
就在上周,OpenAI正式推出GPT-Image-2,其卓越的视觉表现力与精准的文本遵循能力引发了行业广泛关注。无论是高度拟真的电商直播场景、充满复古质感的90年代风格照片,还是逻辑缜密的知识图谱可视化,一系列令人惊叹的演示案例迅速席卷网络。
这标志着AI绘图技术迈入了一个全新的发展阶段。
面对国际巨头的强势进展,国内AI企业的反应同样迅速。短短数日内,商汤科技便重磅发布了其新一代多模态理解与生成模型——SenseNova U1。该模型的核心创新在于,首次将“视觉理解”与“图像生成”这两项过去分离的核心能力,深度融合于同一个统一的模型架构之内。
其技术基石是商汤自研的“原生统一模型架构”NEO-Unify,该架构在底层实现了视觉与语言的理解、推理与生成的原生一体化。尤为值得关注的是,商汤此次选择了全面开源策略。目前,SenseNova U1的完整代码与模型权重已在GitHub平台公开,吸引了大量开发者与研究机构进行测试与创意应用,包括Hugging Face、MLS超级智能体实验室等知名社区的专家也纷纷参与评估与讨论。





一手实测:性能表现与信息量解析
此次开源的是SenseNova U1 Lite轻量版系列,包含两个不同规格的模型:基于稠密骨干网络的SenseNova-U1-8B-MoT,以及基于MoE(混合专家)骨干网络的SenseNova-U1-A3B-MoT。
尽管参数规模相对“轻量”,但其性能表现却超出预期。在多项权威基准测试中,U1 Lite展现了全方位的竞争力,达到了同参数级别开源模型中的SOTA(最优)水平。更令人惊喜的是,其在部分核心评测指标上,甚至能够比肩或超越某些参数规模更大的商业闭源模型。
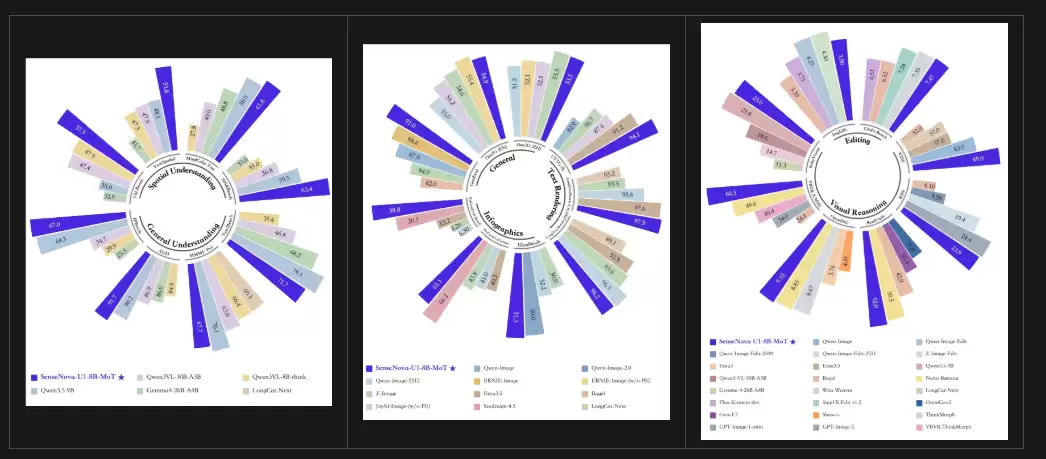
(图像理解、图像生成、视觉推理基准测试结果)
模型上线后,其实际应用能力引发了广泛探索。在深入技术原理之前,我们可以通过几个实际演示案例,直观感受U1模型的能力边界。
首先体验其核心能力之一——连续图文交替创作。这项能力依托于商汤首创的图文交错思维链技术。
来看第一个演示:手绘哥特式大教堂的步骤分解图。在生成过程中,模型如同一位具备深度空间思维的“建筑设计师”,将复杂的建筑美学逻辑清晰地解构并呈现出来。

过去,对于多数AI绘画工具而言,保持多张图像在主体、风格上的一致性是一大挑战。但在此演示中,从简洁的初始轮廓到华丽的最终成稿,建筑的主体结构、飞扶壁的形态、乃至玫瑰窗的纹路细节,都保持了高度一致的物理对齐。这种出色的连贯性,使得生成的系列图像更像一份具备教学价值的连贯视觉教程。
再例如,输入提示词:“设计一栋位于海边悬崖上的图书馆,并呈现多个视角。”模型随即生成了五个不同视角的图文描述,严格遵循图文交替、逻辑递进的模式——从建筑外观到内部氛围,从白日光影到黄昏景色,每一步的“思考”文字都直接引导出对应的“视觉画面”。
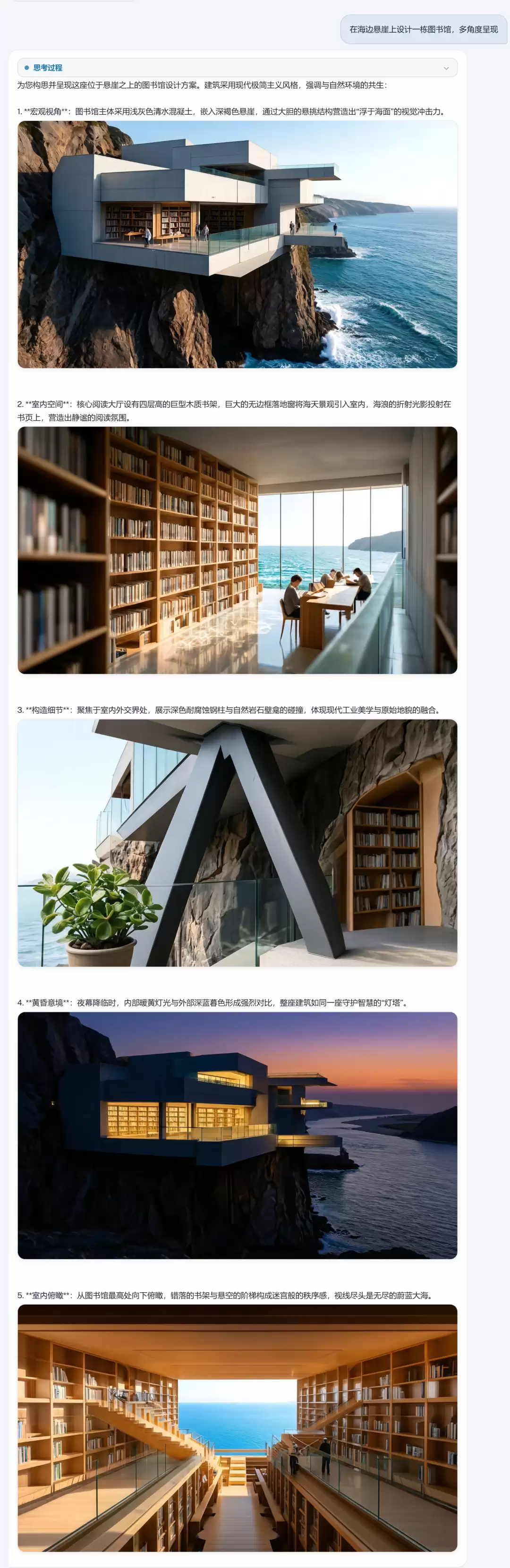
思维过程与视觉表达同步展开,文字为图像提供设计逻辑,图像则为文字提供视觉验证,二者形成了因果闭环。最令人印象深刻的是五张图之间高度的风格自洽性——建筑形态、材质质感、色彩体系保持统一,明显是在同一套“设计概念”下连贯生成的。这正是“边思考边创作”的理想状态。
让它生成一段四格漫画故事,同样只需几句简单的提示。可以看到,叙事节奏把控精准:从赛博废墟中的孤灯,到机器人围观老人读书的荒诞温情场景,再到泪珠滴落书页的微观特写,最后拉远至地平线长队的宏大收尾,情绪层层推进。并且,从首幅到末幅,核心角色与场景保持了良好的连续性。

这种能力得益于SenseNova U1原生统一的图文理解与生成架构,它能将图像和文本的底层融合表征完整地保留在上下文语境中。值得注意的是,模型在每格漫画之间自发补充了丰富的叙事细节,如“静默之塔”的命名、指尖划过岁月痕迹的动作、晶莹泪珠与泛黄书页的对比等。这些文字本身构成了一部微型科幻小说,而图像则精准地将文字中的情感峰值进行了可视化呈现。
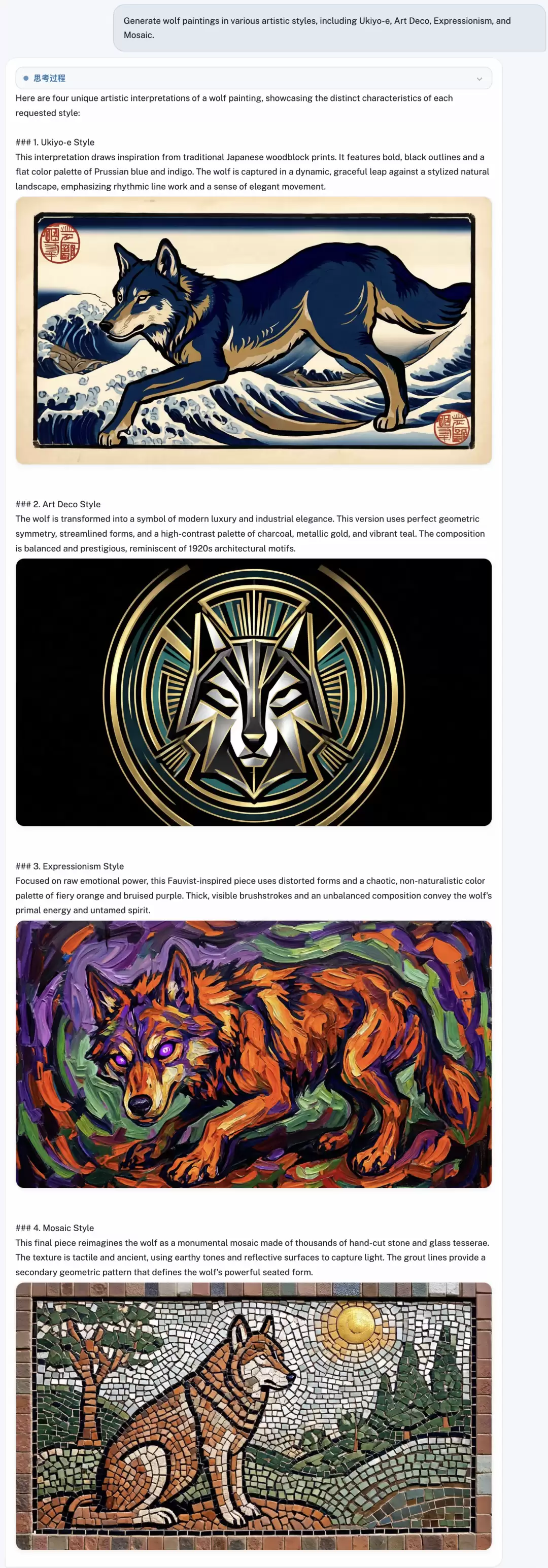
再测试其多风格生成能力,主体仅设定为“狼”。生成结果令人印象深刻,浮世绘、装饰艺术、表现主义等多种艺术风格均被精准捕捉并呈现。
甚至,U1可以通过连续的图文输出,直接生成像PPT一样结构清晰的高维信息图表。它的每一步创作都通过共享上下文实现了统一的视觉表征,从而确保了前后环节在结构、细节上的高度一致性。
此外,U1还能以“图文并茂”的方式,生动直观地解释生活中的一些现象或原理,使得复杂概念易于理解。

最后,尝试一个抽象且高难度的命题:“将‘孤独’这个概念视觉化。要求:画面中不能出现任何人物、表情或文字。”生成的结果颇具意境,能否感受到“孤独”,或许因人而异。

接着,测试U1的一键生成信息图能力。给出简单提示:“制作一张手冲咖啡的步骤图。”SenseNova U1会先进行思考,检索相关知识,然后将这句简单的提示词扩展为详细的步骤描述。

经过一番“操作”,生成的信息图内容丰富、详实。这张详细的手冲咖啡步骤图堪称典范,八个步骤环环相扣,精准还原了从研磨咖啡豆到完成萃取的全过程。

科学知识的科普,一张图就能搞定。在下面这个演示中,输入一句话:“水循环的奇妙旅程。”U1在思考过程中,开始检索并汇总相关信息。

由此,便得到了一张2K超清的水循环示意图。它再次证明了U1处理复杂、高密度信息的强大能力,复现了地理学上的所有关键节点——太阳辐射、蒸发、凝结、输送、降水、径流。而且,AI在每一步创作中,都对前一步的结构和细节做了精准的延续。

仅用“西瓜信息图”六个字,模型便生成了涵盖营养成分、健康益处到食用建议三大板块的百科式图表,信息密度极高,几乎可以直接作为社交媒体内容素材。六个字的提示词,换来一张可直接交付的成品。

U1还能生成这种超复杂、又兼具趣味性的“通勤图鉴”。它设计的每一个板块都充满了巧思和创意,不仅视觉效果出色,内涵也相当丰富。

U1同样可以驾驭不同的艺术风格,例如“波普漫画”。它能够通过分镜形式,用独特的视觉语言传递信息。下面便是一个关于职业转型的波普漫画示例。这张图在视觉和逻辑层面都极具冲击力,AI对高密度信息的处理能力在此得到了极致体现。

估计养宠物的打工人,看到下面这张图,都会产生心照不宣的共鸣。

U1还能瞬间拿捏乐高风格的信息图。一个是“乐高环球早餐图”,将日本、墨西哥、英国、土耳其、巴西、印度等国的标志性食物精准还原,并重构为乐高积木样式,既有趣又有传播价值。另一个是“咖啡百科信息图”,将历史发展、冲煮科学、面临挑战三大知识板块巧妙融入一张图中。
再来一个以“地球的呼吸碳循环”为主题的垂直分层信息图。

一张羊皮纸风格的信息图,清晰诠释了都市的变迁。

还有经典的结构爆炸图测试,U1同样把细节拆解得丝丝入扣。

原生NEO-Unify架构:最强开源模型,理解生成一步到位
U1的实测表现固然惊艳,但背后还有一个根本问题需要回答:为什么一个参数量相对较小的模型能做到这些?答案藏在它的架构层。
当前主流的多模态AI模型普遍采用“拼积木”式的范式:用一个视觉编码器负责“看”,用一个变分自编码器负责“画”,中间再接一个大语言模型负责“想”。三个模块各自独立训练,然后拼接在一起协同工作。
这套范式行之有效,但存在一个根本性问题——感知和创造是割裂的。视觉编码器把图像压缩成语义特征时,不可避免地丢失了像素级细节;而变分自编码器在生成图像时,又得从语义空间重新“猜测”回视觉细节。理解和生成走的是两条路,模型永远在做“翻译”,而不是真正“理解了再画”。
NEO-Unify架构做了一件突破性的事:它摒弃了传统的视觉编码器和变分自编码器。其设计基于一个核心假设——语言和视觉信息本质上是内在关联的,应该被作为一个统一的复合体进行直接建模。

打个比方,传统架构像一个团队里有翻译——视觉信息先被翻译成“语言能懂的格式”,处理完再翻译回“图像能用的格式”。每次翻译都有信息损耗,还增加了沟通成本。NEO-Unify则像一个天生双语的人,从一开始就同时用视觉和语言思考,不需要翻译这个中间环节。
在技术实现上,NEO-Unify的路径是:引入近似无损的视觉接口,统一图像的输入与输出表示;采用原生混合Transformer架构,让理解分支和生成分支在同一个骨干网络内协同工作;文本采用自回归交叉熵目标,视觉通过像素流匹配进行优化,二者在统一学习框架下联合训练。
实验证实了一个关键发现:即使冻结理解分支,独立的生成分支依然能从统一表征中恢复细粒度的视觉细节。这意味着NEO-Unify的统一表征确实同时保留了语义丰富性和像素级保真度。这在以前,被认为是鱼和熊掌不可兼得的。
团队公布的数据显示,NEO-Unify在初步9万步预训练后,在MS COCO 2017数据集上取得了31.56的PSNR和0.85的SSIM,接近Flux VAE的32.65和0.91。考虑到它完全没有依赖任何预训练的视觉编码器或变分自编码器,这个成绩相当引人注目。
经过前面的实测,我们已经见识到了在NEO-Unify架构加持下,SenseNova U1在连续图文创作输出方面的杀手级能力。在多个信息图生成基准测试上,SenseNova U1的生成质量显著优于其他开源模型,甚至可以媲美Qwen-Image 2.0 Pro、Seedream 4.5等闭源模型,并在推理延迟上具有明显优势。
与GPT-Image-2对比:范式差异才是关键
就在一周前,GPT-Image-2横空出世,以其近乎完美的文字渲染、多轮编辑和推理驱动的生成能力,在创意生图领域树立了新的标杆。
但需要明确的是,GPT-Image-2本质上仍然是一个“生图专用模型”,它的核心能力是根据文字指令生成高质量图像。而SenseNova U1走的是一条完全不同的道路。它不是一个“生图模型”,而是一个“原生理解生成统一模型”。图像生成只是其能力谱的一部分;它同时具备图像理解、视觉推理、图文交错思考、信息图生成等全维度能力,而且这些能力来自同一个架构、同一次训练、同一个模型。
更关键的一点在于,SenseNova U1不仅能力强,而且是开源的。对于那些需要私有化部署、深度定制、或将多模态能力嵌入自身产品的开发者而言,U1提供了一条GPT-Image-2无法提供的路径。
原生统一:通往AGI的必经之路
站远一步看,GPT-Image-2引爆的“生图大战”,本质上还是在模态割裂的范式里竞争——比谁的文字渲染更准、分辨率更高、风格更多样。这些当然重要,但它们都属于“能力增量”,而非“范式变革”。
真正的通用人工智能不会是一堆专用模块的机械拼接。人类的大脑并非“语言区负责想、视觉区负责看、运动区负责画”三个独立系统的简单组合,而是一个高度统一的认知体。多模态AI要走向AGI,“原生统一”这条路迟早要走。
NEO-Unify是第一个真正意义上“全扔掉”传统分立模块的原生统一架构,这让它在学术探索和工程实践两个维度上都具备了独特的坐标价值。从GitHub和Hugging Face上的早期活跃度来看,NEO-Unify架构本身已引发了大量技术讨论。已有开发者在Apple Silicon上复现了NEO-Unify的小规模实验,验证了混合Transformer架构在小参数规模下的表现潜力。

对于关注多模态统一范式前沿的研究者来说,U1的开源提供了第一个可以实际上手运行和研究的原生统一模型。
8B参数规模只是一个开始。商汤在发布U1时明确表示,当前开源的U1 Lite是轻量版,团队正沿着NEO-Unify架构继续扩大模型规模,更大参数量的版本将在后续推出。他们的信念是,基于高效的原生统一架构,可以用低得多的计算成本达到国际顶尖模型的水平。这句话的潜台词是:8B版本已经在开源领域达到了SOTA水平,当参数量扩展到几十B甚至更大时,NEO-Unify架构的优势红利将更加显著。
多模态AI正在经历一场“从拼接到统一”的范式迁移。U1的全球开源,是这条道路上的重要一步。从今天展现的效果来看,这一步已经走得足够扎实。至于这条路最终将通向何方,答案或许需要全球开发者社区共同来书写。
代码和模型权重已经上线。剩下的,交给实践与时间。
相关攻略

全球AI图像生成领域的竞争格局,正迎来前所未有的激烈变革与范式升级。 就在上周,OpenAI正式推出GPT-Image-2,其卓越的视觉表现力与精准的文本遵循能力引发了行业广泛关注。无论是高度拟真的电商直播场景、充满复古质感的90年代风格照片,还是逻辑缜密的知识图谱可视化,一系列令人惊叹的演示案例迅

在影视特效、虚拟现实和三维内容创作中,一个关键难题是如何让AI仅凭一张静态图片,就能准确生成不同相机角度下的新视图。这不仅需要简单的画面旋转,更依赖于对场景三维结构的深度理解与重建。目前的主流技术大多基于图像扩散模型,通过处理离散的视角映射已取得显著进展。 然而,当面对真实拍摄中平滑、连续的相机运动

全球AI编程助手领域的权威评测迎来重要升级。知名分析机构Artificial Analysis今日正式推出全新的Coding Agent基准体系——Artificial Analysis Coding Agent Index。这一全新评估框架旨在系统、客观地测评各类AI编程助手及其底层大模型在实际开

腾讯联合清华等推出Pixal3D项目,通过创新的反向投影技术,将单张二维图像显式映射为三维模型。该方法能生成具备精细几何结构和完整PBR纹理的高保真3D资产,质量接近多视图重建效果,可直接用于游戏、影视等专业生产流程,显著提升内容创作效率。

腾讯云开源了TencentDBAgentMemory分层记忆引擎,采用MIT协议。该引擎通过“上下文卸载”和“Mermaid任务画布”两项核心技术,在多任务连续会话中最高可降低61 38%的Token消耗,并将任务成功率相对提升51 52%。它解决了长周期任务中记忆跨会话断裂、事实与偏好混淆以及上下文膨胀三大痛点。项目已适配主流Agent框架,支持一键集成与
热门专题







热门推荐

在内容创作领域,效率是核心竞争力。随着AIGC技术浪潮的全面到来,一个能够整合文案、图像、音频、视频全流程的智能创作平台,已成为创作者提升生产力的关键工具。今天我们要深入解析的“秒创”,正是这样一个旨在实现“秒级”内容生成的一站式AI创作解决方案。 秒创是什么?一站式AI创作平台详解 秒创,其前身为

UNI是Uniswap平台的治理代币,持有者可参与协议决策。其总量10亿枚,分配注重社区发展。关键转折在于“UNIfication”提案通过后,平台部分手续费用于回购销毁UNI,使代币具备价值积累功能。Uniswap作为领先的去中心化交易所,其交易活跃度直接支撑UNI价值。未来发展与平台交易量及监管环境密切相关,需关注相关风险。

自动做市商通过算法和流动性池革新了加密资产交易,消除了对订单簿和中介的依赖。其核心是恒定乘积公式,能实时定价并降低参与门槛,但也伴随无常损失风险。未来,AMM将向可编程、跨链互操作、AI赋能及拓展至真实世界资产等方向发展,并在合规框架下演进,以提升交易效率与安全性。

在中国广播影视与网络视听行业的技术演进历程中,中国电影电视技术学会始终扮演着关键角色。作为该领域内唯一的国家级学术组织,学会依托中央广播电视总台的强大支撑,核心使命在于推动行业技术交流、协同创新与高质量发展。它不仅是我国广播、电影、电视及网络视听科技事业的重要社会力量,更是连接产学研用、促进行业整体

iPhone硬重置可将设备彻底恢复至出厂状态,清除所有个人数据和设置,常用于解决系统故障或转让前清理隐私。具体可通过设备设置、连接电脑使用iTunes或Finder、以及借助专业解锁工具三种方法实现。其中专业工具能在忘记密码时强制清除设备数据。重置后所有内容将被永久删除,需提前备份重要信息。