腾讯混元CL-bench升级发布,大模型精准解读日常生活场景

我们对于“AI个人助手”的想象,正变得越来越具体和迫切。
一个真正能融入日常生活的智能助手,必须能从我们生活的点滴痕迹中学习和理解,解决那些复杂场景下的实际问题。这听起来简单,实现起来却充满挑战。
在近期的AGI-Next前沿峰会上,腾讯的姚顺雨分享了一个生动的例子:当你询问AI“今天吃什么”时,真正制约答案质量的,可能并非模型规模或推理能力,而是AI缺乏对你个人状态的感知——它不知道你今天是否怕冷、是否想吃点热乎的、最近和朋友聊过哪些餐厅、家人的口味偏好又如何。
问题的核心由此凸显。下一代AI助手亟需的,往往不是更多的“知识记忆”,而是对“生活上下文”的理解与推理能力。这正是CL-Bench系列最新力作——CL-Bench Life——旨在攻克的核心难题。

论文题目:CL-Bench Life: Can Language Models Learn from Real-Life Context?
项目主页:www.clbench.com
接下来,我们将结合腾讯混元模型团队的最新研究成果,深入探讨那些对人类而言轻而易举的日常琐事,为何对AI构成了巨大挑战。
日常生活中的上下文复杂性:全新的挑战维度
要让AI真正解决现实问题,仅靠训练时灌输的“静态知识”是远远不够的。它必须具备从实时发生的事件中学习新上下文、基于线索推理并记住关键信息的能力。早期的CL-Bench基准正是为测试这种上下文学习能力而设计的。
然而,如今反思,我们或许为AI留下了一条“捷径”:测试中的上下文信息往往是预先整理好、结构清晰的。

图:专业或工作场景中的上下文结构相对清晰,知识聚焦(左);而日常生活中的上下文则更为凌乱、碎片化,常包含多个交织的话题(右)。
这种假设在专业领域或许成立,但在日常生活中却截然不同。试想我们每天面对的典型混乱场景:
在一个亲友群混杂的日常闲聊中,梳理出每个人本周末的时间安排、出行意愿、饮食禁忌,最终敲定一份让所有人都满意的旅行计划;
从“文件传输助手”里散落的数十条未读分享链接和随手备忘录中,整合出一份逻辑连贯的产品规划草案;
或是从自己过去大半年断断续续的运动打卡和康复日志里,分析出某个部位反复受伤的根本原因。
生活本质上是混乱且高度碎片化的,信息仅靠一条脆弱的时间线勉强串联。

图:三个日常生活上下文的典型案例。案例1:AI需要分析一段冗长嘈杂的多人群聊,其中包含多条交错的话题线、不断变更的计划以及分散的时间冲突,以协助组织一次读书会;案例2:AI需要分析大量零散的骑行记录、车辆维修日志、突发事件笔记和个人日记,为一次五天骑行计划制定一份以安全为核心的行前检查清单;案例3:AI需要分析用户受伤前后数百条训练记录,判断受影响最大的肌群并制定相应的恢复计划。
我们常常低估了这对AI的难度。最初的CL-Bench测试的是模型能否掌握并应用复杂的新知识。但现实生活从不提供“说明书”。AI不能仅满足于理解抽象规则;它必须能够在混乱、稀碎的线索中拼凑出完整图景,并在各种干扰信息下保持高度鲁棒性。
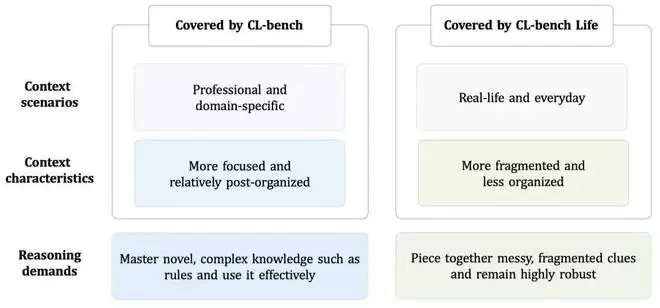
图:CL-Bench与CL-Bench Life所覆盖的两类上下文学习场景对比。
若想AI真正蜕变为可靠的私人助手,它必须深刻理解我们真实的生活模式。为此,腾讯混元团队填补了CL-Bench未覆盖的空白,正式推出了专注于日常生活的评估基准——CL-Bench Life。
CL-Bench Life:衡量AI在真实生活中的上下文学习能力
为了精准评估AI在现实生活中的上下文学习能力,腾讯混元正式发布了CL-Bench Life。这是一个完全由人工精心构建的基准测试集,包含了405个高度仿真的日常任务。
为最大程度覆盖最常见的真实场景,研究团队将基准划分为三大核心类别:

图:CL-Bench Life的上下文分类体系。
1. 沟通与社交互动:此类涵盖一对一私聊、混乱的多人群聊、活跃的社区讨论等场景。要在此类任务中成功,AI必须学会“理解言外之意”。它需要解析复杂的人际关系,感知隐藏的情绪,推理群体共识的形成过程,并从日常对话中提取出真正有价值的信息。
2. 碎片信息与修改轨迹:此类包括零散的个人笔记、公共信息流以及文档反复修改的历史版本。其核心挑战在于,模型必须从极其凌乱的日常信息碎片中重建完整的逻辑链条,或整理并推理出一个想法、一项计划是如何经过多次迭代最终定稿的。
3. 行为记录与活动轨迹:此类涵盖游戏日志、数字足迹以及长期的个人追踪数据。在此类上下文中,AI需要从一连串行为痕迹中推理出背后的动机与模式。例如,通过分析长期的消费流水或健身数据,理解用户的潜在习惯,并发现其中的异常变化。
CL-Bench Life还包含了5348条完全由人工编写的精细化评分标准,平均每个任务对应13.2个考核点。这些评分细则被设计得尽可能原子化,从而能够更全面、更细致地评估模型答案的准确性。
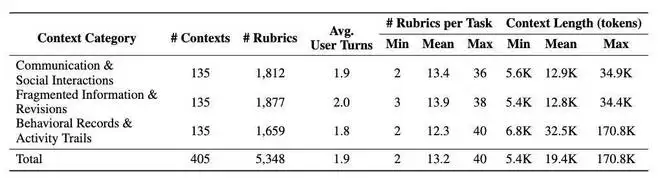
表:CL-Bench Life的统计信息,包括上下文和任务数量、评分细则数量、上下文中多轮对话的平均轮次、每个任务对应的细则数量,以及上下文的平均token长度。
关键研究发现与洞察
研究团队测试了12个主流语言模型,初步评测结果揭示了一个严峻现实:这些模型平均仅能解决CL-Bench Life中14.5%的任务。即便是表现最佳的GPT-4o,其任务解决率也仅为22.2%。这表明,当前模型在处理高噪声、碎片化的日常生活上下文时,仍然力不从心。
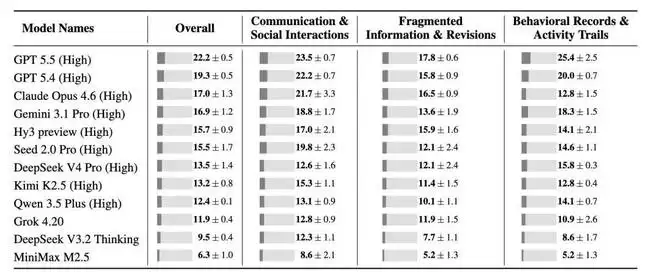
表:前沿语言模型在CL-Bench Life上的任务解决率。
这一表现甚至低于在CL-Bench上的结果。在CL-Bench中,同一批模型平均能解决20%以上的任务。这一差异证实了CL-Bench Life测试的是另一个维度的上下文学习能力。
简而言之,CL-Bench的上下文源于专业领域,相对清晰、结构有序,模型需要掌握的是新的知识、规则或流程。而CL-Bench Life的上下文源于日常生活,更加混乱、无序,信息可能随时间轴被反复修改和覆盖。在此,模型需要整合分散的线索,处理大量噪声,并始终保持推理的鲁棒性。
这清楚地表明,当模型面对的不再是清晰有序的上下文,而是杂乱、碎片化、弱结构化的现实生活信息时,上下文学习的难度会急剧攀升。这两个场景对模型能力提出了不同方面和不同层次的要求。
除了整体表现不佳,进一步的实验分析还揭示了更深入的发现:
1. 部分理解与完美解决之间存在显著差距。 在CL-Bench Life中,虽然模型完美解决任务的比例很低,但给出部分正确答案的比例则高得多。当研究团队放宽任务通过的阈值(即一个回答需要满足多少比例的评分细则才算正确)时,模型的通过率显著上升。这说明模型虽然难以完整解决一个任务,但确实能够理解部分上下文并完成部分子任务。同时,在不同阈值下,模型之间的相对排名基本保持稳定,这意味着CL-Bench Life能有效区分“部分理解”和“完美解决”,并支持稳定的模型性能比较。
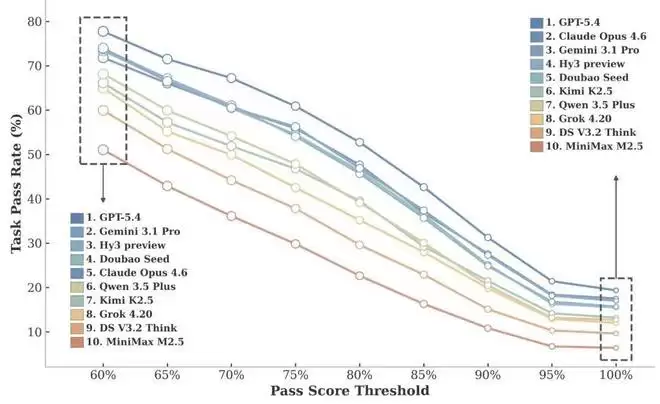
图:模型在不同任务通过阈值下的表现对比。
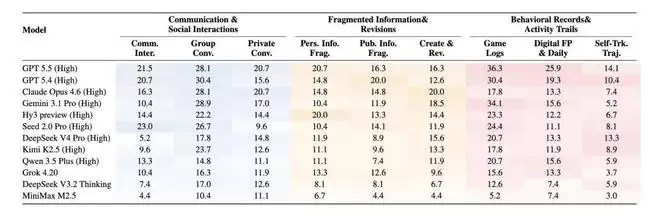
表:各主流模型在CL-Bench Life不同类别及子类别上的具体表现。
2. 不同类别的上下文,挑战侧重点各异。 即便同属日常生活场景,信息类型的差异也导致了对模型能力的不同要求。例如,在“沟通与社交互动”类别中,主要困难源于复杂的社交动态和多人互动:相关信息分散在交错的话题中,讨论线重叠,人物关系和指代也更为复杂。而在“碎片信息与修改轨迹”类别中,模型则需要整合不连续的线索,并推理内容是如何随时间推移而不断演变的。
3. 瓶颈不仅是“长度”,更是“噪声”。 模型在日常生活中上下文学习能力的不足,不能简单归咎于长文本处理问题。研究发现,更长的输入确实可能增加任务难度,但输入长度本身并非决定性因素。具体而言,当模型启用思维链推理时,上下文长度与模型表现之间的相关性就大大减弱了。这说明日常生活上下文学习的主要瓶颈,并非模型能否处理更长文本,而在于它能否有效处理高噪声、低信噪比的输入。这与CL-Bench中的现象形成对比:在CL-Bench中,更长的输入通常意味着需要吸收更多新知识,模型表现下降更为明显。
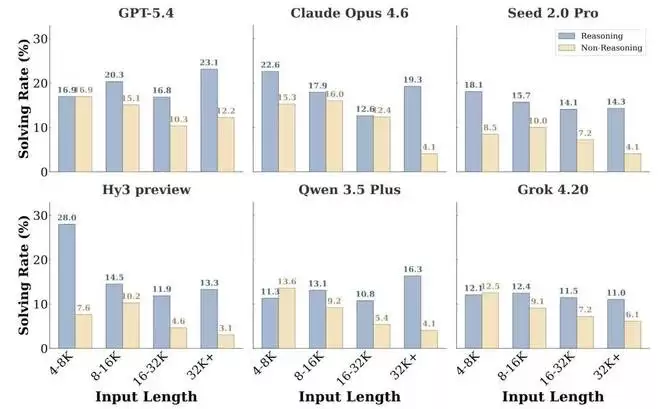
图:在开启推理与未开启推理两种模式下,不同上下文长度区间内的任务解决率。
4. 主要失败原因:上下文误用。 为深入理解模型的局限,研究团队详细分析了失败案例。跨模型来看,最主要的错误类型是“上下文误用”:模型确实读取了上下文,但仍然误解或错误地使用了它。值得注意的是,这与CL-Bench中的“上下文误用”内涵不同。在CL-Bench中,误用常指模型错误应用了新定义的规则知识。而在CL-Bench Life中,错误更多源于模型误解了一个日常语境中常见的上下文。例如,混淆了口语中“他”的具体指代;依赖已被后续修订推翻的早期信息进行推理;误将临时的草稿修改或随口之言当作最终决定;或将一段孤立的行为轨迹视为偶然事件,未能推理出其背后的长期习惯。相比之下,格式错误和直接拒绝回答的情况在CL-Bench Life中则少得多。
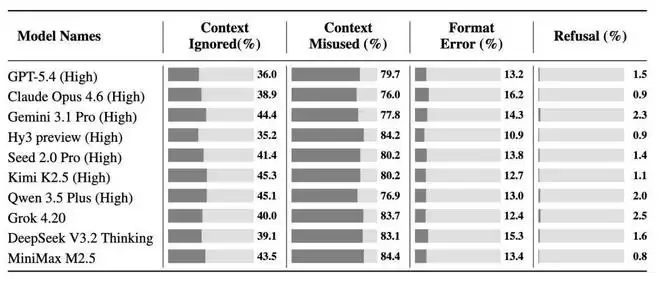
图:四类错误在不同模型中的分布情况。上下文误用是主要失败因素,而格式错误和拒答相对较少。
研究团队进一步以“群聊”类上下文为例,深入剖析了模型的常见错误,以探索其在日常生活场景下失败的具体根源。
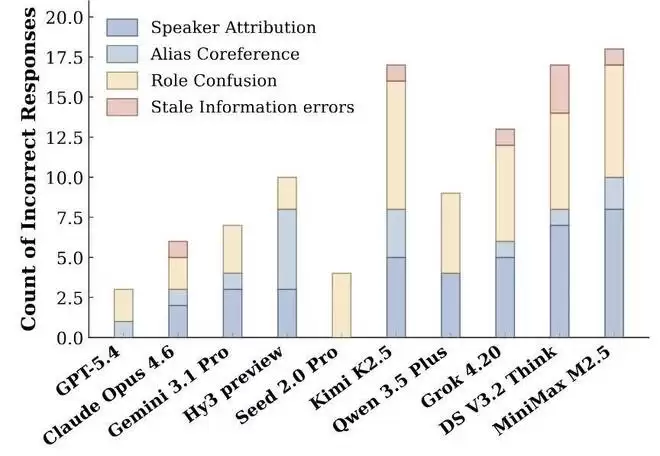
图:沟通与日常交流类别中,群聊上下文的错误类型分析。
在群聊和会议类上下文中,最常见的错误是“角色混淆”以及“说话人归因错误”。例如,模型无法准确记忆哪些话是谁说的,以及谁引用了谁的发言。在一个案例中,模型错误判断了Slack频道中三位协作者(Alice, Brenda, Clara)的汇报关系,导致后续一连串关于职责归属的推理全部出错。
这说明,模型理解群聊上下文的核心难点,不仅在于需要跟踪事件进展,更在于需要在混乱的多人互动中,持续、准确地维护参与者信息、说话人身份,并在动态变化的人际网络中保持鲁棒的理解。
总体而言,这些发现表明CL-Bench Life并非仅仅是CL-Bench的一个更难版本,而是一个至关重要的互补性评估基准:它评估的是模型能否在真实生活中那些杂乱、碎片化、持续变化的上下文上进行鲁棒且准确的推理。
结论与展望
CL-Bench Life揭示了一个不容忽视的结论:即使是当今最先进的AI模型,也远未真正“读懂”我们的日常生活。这也解释了为何许多用户在与AI交互时,常感觉其“不够灵光”。即便我们将聊天记录、零散笔记、行为数据都提供给AI,期望它处理日常事务时,它有时仍会“抓不住重点”。因为它可能只是“读取了”信息,却未能真正理解这些信息在现实生活中的具体含义与深层关联。
腾讯混元团队希望CL-Bench和CL-Bench Life能从两个互补的方向,共同推动上下文学习能力的发展:一手掌握专业领域中聚焦、结构化的知识;一手应对真实生活中碎片化、非结构化的现实。最终目标是助力AI在人类的工作与日常生活中都变得更加智能、实用和可靠。
显而易见,围绕上下文能力发展的道路不会止步于此。让AI学会处理复杂上下文,是其真正融入现实世界的关键。CL-Bench系列工作推动AI更深入地理解上下文,是其中至关重要的一步。而让AI学会在长期使用中记忆、整理和组织上下文,则是迈向那个真正能够服务人类的个性化智能助手的下一步。
相关攻略

我们对于“AI个人助手”的想象,正变得越来越具体和迫切。 一个真正能融入日常生活的智能助手,必须能从我们生活的点滴痕迹中学习和理解,解决那些复杂场景下的实际问题。这听起来简单,实现起来却充满挑战。 在近期的AGI-Next前沿峰会上,腾讯的姚顺雨分享了一个生动的例子:当你询问AI“今天吃什么”时,真

5月7日,腾讯混元公布了一组关于其最新模型Hy3 preview的数据,结果相当引人注目。自该模型上线以来,其Token调用量持续攀升,目前总量已达到上一代版本Hy2的10倍之多。 增长点在哪里?代码和智能体类场景的贡献尤为突出。在腾讯内部的WorkBuddy、Codebuddy以及Qclaw等应用

说到国内自研大模型,腾讯混元绝对是个绕不开的名字。作为腾讯全链路自研的成果,它在内容创作、逻辑推理、代码生成以及多轮对话这些核心能力上,表现相当亮眼,业界口碑一直在线。更值得一提的是,其API还集成了AI搜索联网插件,能直接调用微信公众号、视频号等腾讯生态内的优质内容,这让它在获取实时、深度的信息并

原阿里通义视觉负责人薄列峰已加入腾讯混元团队,向副总裁蒋杰汇报。薄列峰拥有顶尖学术与工业背景,曾主导多项重要AI项目。近期,腾讯混元还吸引了微软WizardLM团队核心成员等人才加入,正快速构建多模态技术阵容,展现建立独立技术体系的决心。

腾讯混元宣布微信小程序成长计划已接入Hy3preview版本,标志着小程序开发工具迎来重要更新。此举将影响众多开发者,推动小程序生态的进一步演进。
热门专题







热门推荐

在全球紧张局势下,美国国防部将比特币重新定义为国家安全资产,反映出其战略价值提升。美国国库持有大量比特币,大国博弈中加密货币已成为国家安全筹码。市场普遍认为这一身份转变将增强机构需求,推动价格上涨。后续需关注美国政策动向、地缘政治变化及相关监管动态。

当Windows系统遭遇蓝屏时,那些含义不明的错误代码往往令人困扰。例如代码0x00000012 (TRAP_CAUSE_UNKNOWN),其官方解释为“内核捕获到无法识别的异常”。这就像一个笼统的系统警报,提示底层发生了问题,但并未指明具体故障点。此类错误通常不关联特定系统文件,反而更常见于新硬件

必须安装JDK并配置JA VA_HOME与Path环境变量;先下载JDK 17 21 LTS版本,安装时取消“Add to PATH”,再手动设置JA VA_HOME指向安装目录,并在Path中添加%JA VA_HOME% bin,最后用ja va -version等命令验证。 在Windows 1

对于Mac用户而言,从图片中提取文字其实无需额外安装第三方OCR软件。macOS系统自身就集成了强大的光学字符识别功能,它基于苹果自研的Vision框架与Core ML机器学习模型。最大的优势在于完全离线运行,所有图片处理均在本地完成,无需上传至任何云端服务器,充分保障了用户的隐私与数据安全。本文将

数据库长连接在静默中突然断开,是很多运维和开发都踩过的坑。你以为启用了TCP Keepalive就万事大吉?真相是,如果应用层、内核层和基础设施层的配置没有协同对齐,这个“保活”机制基本等于形同虚设。 问题的核心在于,一个完整的TCP Keepalive生效链条涉及三个环节:你的应用程序或连接池是否