英伟达颠覆性成果重新定义RAG外部检索必要性
说到RAG(检索增强生成),大家可能已经习惯了它的标准工作流程:先用一个检索模型从海量文档里捞出一批“相关”内容,再交给大语言模型去消化、生成答案。这个流程看似顺畅,但其实一直埋着一个根本性的问题,只是我们习以为常了。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
这个问题就是:检索器和生成器,其实是在两个完全不同的“世界”里工作。
检索器,无论是BM25还是BGE、ColBERT,它们在一个“嵌入表示空间”里计算相似度打分。而生成器,也就是我们的大模型,则是在Transformer的“隐藏状态空间”里理解和处理文本。这就导致了一个尴尬的局面:检索器觉得“高度相关”的文档,到了生成器那里,可能根本派不上用场。学术界管这叫“检索器-生成器失配”,它一直是RAG性能天花板上的那道裂缝。
那么,有没有更本质的解法?最近NVIDIA的一项研究INTRA,就提出了一个直指核心的设问:既然Transformer的注意力机制,本质上就是一种“基于查询的信息选择”,那我们为什么不让模型自己,用它的注意力机制,去检索它自己编码好的信息呢?

INTRA的解题思路:让注意力机制“身兼两职”
注意力 = 检索?一个被忽视的等式
我们先拆解一反赌意力计算的核心:给定一个查询(Query),它与一系列键(Key)进行匹配打分,然后根据分数对值(Value)进行加权聚合。再看检索的核心:给定一个问题(Query),在一堆文档(Keys)中找到最相关的。
你会发现,它们在数学形式上惊人地一致:都是“基于查询的候选状态匹配”。说白了,注意力机制内在地完成了一次检索操作。INTRA所做的,就是把这个理论上的等式,变成了一个可运行的工程系统。
它的实现路径非常清晰:
首先,用一个编码器把整个知识库的所有文本块预编码成一组固定的键状态(Keys)存储起来。
然后,在输入问题后面附加几个可训练的“检索标记”。在解码生成时,这些标记对应的解码器交叉注意力查询(Query),会直接对全库所有预编码的键状态进行相似度打分(采用了类似ColBERT的MaxSim方式)。
最后,选出分数最高的前N个文本块,直接使用它们同一份预编码的状态作为解码器的上下文,进行答案生成。
整个过程,只需要对解码器做两次前向传播,且共享同一份编码状态。外部检索器?不需要。对检索到的文本重新编码?也省了。
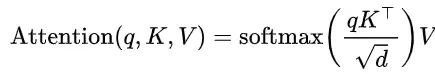
RQWK:一个巧妙的工程“魔术”
当然,这里有个工程难题。标准Transformer每一层都有自己的Key投影矩阵,这意味着如果按层存储编码状态,开销会从O(M)暴增到O(L×M),根本无法承受。
INTRA的解决方案是一个名为“Reverse-QWK”的巧妙技巧。它把Key的投影操作,从编码侧移到了查询侧。简单来说,不再为每一层存储不同的Key表示,而是只存储一份归一化后的基础编码状态。在计算注意力时,对查询向量进行反向的投影变换。
这样做在数学上完全等价,却让所有解码层都能共享同一份编码表示。于是,检索时的相似度计算和生成时的注意力计算,终于严格地在同一个表示空间里完成了——检索与生成实现了真正的统一。
小训练,大效果:预训练能力的“释放”
仅训练16.4万参数
INTRA最令人惊讶的一点是它的训练效率。在一个40亿参数的T5Gemma2模型上,它选择冻结了编码器和解码器的全部参数。
只训练什么?仅仅是那几个“检索标记”的嵌入向量,加上一个用于聚合各层检索信号的小权重矩阵。全部加起来,大约是16.4万个参数。
训练目标也极其简洁:让这些检索标记的注意力概率,尽可能集中在那些能回答问题的“黄金证据”文本块上。
如此微小的训练量就能取得显著效果,这强烈暗示了一点:强大的检索能力,可能本就内蕴于经过高质量预训练的大模型之中。INTRA所做的,更像是一种“能力释放”,为模型提供了一个利用自身注意力进行检索的接口。
推理效率:一次编码,多次复用
从流程上对比,优势也很明显:
传统RAG需要三步:检索文本 -> 重新编码文本 -> 解码生成。
INTRA只需两步:检索预编码状态 -> 直接解码生成。
对于企业常见的静态知识库(如产品文档、法规条文),所有文档的编码状态只需计算一次并存储,之后面对海量用户查询均可直接复用。虽然存储开销(例如千亿token语料量化后可能达TB级)不容忽视,但对于许多企业级场景而言,这已是可接受的工程权衡。
实战表现:在多跳推理任务中脱颖而出

在HotPotQA、2WikiMultihopQA、MuSiQue等多个需要多步推理的多跳问答基准测试中,INTRA在“完整证据召回率”这项关键指标上,全面超越了9种主流检索基线。这包括:
传统的稀疏检索方法(如TF-IDF、BM25);
先进的密集检索模型(如BGE-large、Qwen3-Embedding系列);
专业的重排序器(如Jina Reranker);
以及混合检索和ColBERT风格基线。
为什么在多跳场景下优势如此明显?关键在于,INTRA的检索信号直接来自解码器的注意力权重。这些权重天然编码了“生成当前答案需要什么信息”的意图。对于需要串联多个证据才能回答的问题,解码器的查询状态能够感知这种递进式的信息需求,从而引导系统检索出所有必要的证据片段。
相比之下,在单跳问答(如Natural Questions)上,其优势就不那么突出。因为这类问题通常只需一个直接相关的段落,INTRA所擅长的多证据协同检索能力没有太多用武之地。
一个更深刻的发现:统一空间比强大组件更重要
实验还有一个值得玩味的发现。研究者引入了一个“差距闭合度”的指标,来衡量检索系统能在多大程度上弥补“随机检索”与“完美检索”之间的性能鸿沟。
结果发现,使用同一个T5Gemma2解码器同时负责检索和生成时,差距闭合度最高。即使换用更强大的生成器(如Qwen2.5-7B/72B),虽然答案的绝对准确率上升了,但差距闭合度反而下降了。
这背后的逻辑是:更强的生成器有自己的注意力模式,INTRA为原配解码器检索的证据,可能与新生成器的注意力模式不完全匹配。这个结果进一步印证了INTRA的核心思想:让检索和生成在同一个表示空间内协同工作,比单纯组合一个强力检索器和一个强力生成器,往往更有效。
写在最后
所以,INTRA的核心贡献并非否定RAG,而是挑战了RAG的“分裂架构”。它指出了一个被长期忽视的真相:注意力机制本身就是检索。当我们让模型用自己的注意力查询去检索自己的编码表示时,检索器与生成器之间的“失配”问题便自然消解了,多跳推理的证据组装也因此变得更加精准和高效。
当然,当前的工作仍有局限,例如其基于T5Gemma2这类编码器-解码器架构,而目前开源生态中主流的强大模型多为仅解码器架构。但如果这个方向被证明是可行的,未来更强大的编码器-解码器模型,或许能让INTRA所代表的“内在检索”思路展现出更大的潜力。
Retrieval from Within: An Intrinsic Capability of Attention-Based Models
https://arxiv.org/pdf/2605.05806相关攻略

说到RAG(检索增强生成),大家可能已经习惯了它的标准工作流程:先用一个检索模型从海量文档里捞出一批“相关”内容,再交给大语言模型去消化、生成答案。这个流程看似顺畅,但其实一直埋着一个根本性的问题,只是我们习以为常了。 这个问题就是:检索器和生成器,其实是在两个完全不同的“世界”里工作。 检索器,无

五月中旬,英伟达市值突破5 5万亿美元,超越德国2025年名义GDP,成为全球首家市值超过单一发达经济体的上市公司。这反映了人工智能浪潮带来的巨大能量重构。英伟达自2004年起在中国设立多家公司,已构建完整的业务网络。市值里程碑背后,是AI算力赛道价值获得空前认可的缩影。

在AI需求爆发的背景下,GPU市场出现供需严重失衡。英伟达CEO黄仁勋将旧款GPU价格持续上涨的现象比喻为“好酒效应”,指出其升值速度甚至超过葡萄酒陈化。核心原因在于全球AI业务对算力的巨大需求,使得数据中心极度依赖GPU。这种需求从上游芯片制造到下游云服务贯穿整个产业链,导致包括四五年前旧型号在内

来源:环球时报 【环球时报特约记者 甄翔】资本市场近日上演了一场引人注目的“王座”争夺战。谷歌母公司Alphabet在美股盘后交易时段,市值一度超越英伟达,这意味着它在阔别大约十年后,短暂地重返了全球市值冠军的宝座。回顾过去一年,Alphabet的股价表现堪称惊艳,累计飙升了160%。截至上周五收盘

英伟达股价在短短四个交易日内飙升14%,市值激增5910亿美元,这一增量已超过甲骨文公司的总市值。分析师认为,这反映了市场对其人工智能芯片的强劲需求并未放缓,投资者正认可大型云服务商的高资本支出承诺。同时,资金流向显示AI红利正扩散至存储芯片、半导体设备、光模块等更广泛的供应链环节。尽管有分析师提示
热门专题







热门推荐

进入2026年,加密货币市场的格局与安全标准已悄然进化。对于投资者而言,选择一个安全可靠的交易平台,其重要性丝毫不亚于挑选资产本身。毕竟,资产增值的前提,是它们得安然无恙地躺在你的账户里。今天,我们就来盘一盘当前市场上主流的虚拟资产交易所,从风控能力、资产储备与市场口碑等多个维度,做一次深入的“避雷

本文梳理了2026年备受关注的数字资产交易平台,从安全性、功能特色与用户体验等维度进行分析。重点探讨了主流合规平台在资产托管、交易深度上的优势,以及新兴聚合器在提升交易效率方面的创新。同时,也指出了选择平台时需关注的风险控制与合规性,为不同需求的用户提供参考方向。

本文汇总了2026年主流的数字资产交易平台,从安全性、功能特色、用户体验及合规性等维度进行分析。内容涵盖适合新手的综合性应用、面向专业交易者的工具型软件,以及注重资产安全的托管方案,旨在为用户选择合适平台提供客观参考,并提醒注意市场风险与自我资产保护。

本文梳理了2026年主流的数字资产交易平台,从安全性、交易体验、功能特色等维度进行分析。重点介绍了综合型头部平台、专注创新的新兴应用以及面向特定需求的专业工具,旨在为用户提供客观参考,帮助其根据自身情况选择合适的软件进行下载与使用。

本文探讨了2026年数字货币交易软件的选择标准,并列举了十款主流应用。内容涵盖安全性、交易对、用户体验及费用等核心考量维度,分析了不同平台在现货、合约及DeFi集成等方面的特色,旨在为不同层级的用户提供实用参考,帮助其根据自身需求做出合适选择。