5月13日,联发科技天玑开发者大会MDDC 2026如期而至。本届大会以“全域芯智能,体验新无界”为主题,其意义远不止于几项新技术的发布。更值得关注的是,联发科正借此机会,清晰地勾勒出其面向端侧AI爆发与移动游戏升级双重浪潮的产业级战略布局。

从天玑AI智能体化引擎2.0到游戏全链路优化技术,从开发者工具革新到生态伙伴的深度绑定,一套“技术自研+生态共建”的双轮驱动模式已然成型。其核心目标,正是打破端侧AI的落地壁垒,推动整个移动产业从单纯的“硬件性能竞争”,迈向更高维度的“全栈智能生态竞争”。
端侧AI拐点已至:联发科技破解智能体落地核心痛点
战略升维:从芯片供应商到智能体化体验的赋能者
当前,AI产业的重心正加速从云端集中式算力,向端侧分布式算力渗透。智能体作为端侧AI的核心形态,其价值在于实现设备的主动感知、跨场景自主决策以及端侧隐私安全可控。
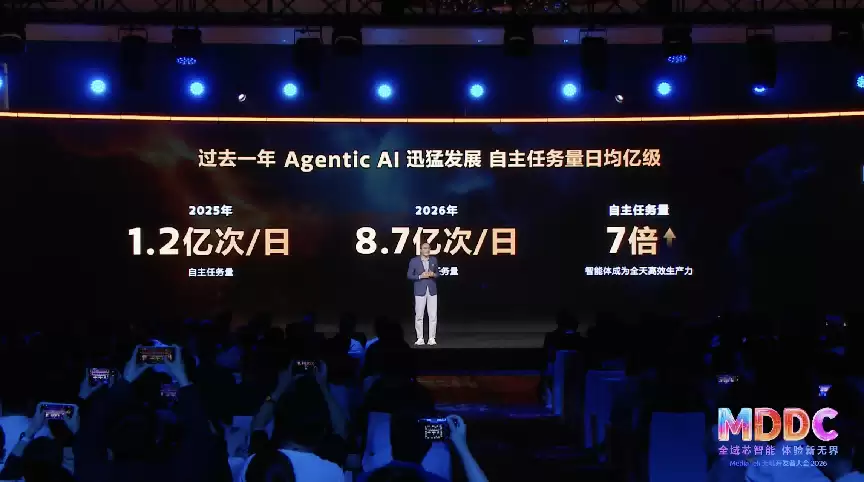
然而,理想丰满,现实骨感。端侧智能体的规模化落地,长期受困于三大痛点:模型部署门槛高、算力与功耗难以平衡、感知与执行的链路割裂。联发科技此次大会的一系列动作,正是针对这些行业共性难题,以全栈技术体系给出系统性解决方案,旨在将端侧智能体从概念推向量产落地。
联发科技董事、总经理暨营运长陈冠州指出:“智能体 AI 正在重构和升级越来越多的行业和应用场景。MediaTek以覆盖手机、汽车、IoT以及AI基础设施的全栈、多元技术与产品组合赋能‘智能体化体验’,以无处不在的强大算力,结合先进的云端AI加速技术,为全球生态伙伴打通从创意到规模化落地、从应用价值到商业价值的关键跃迁,让 AI 真正赋能大众的日常生活和千行百业的增长曲线。”
技术基石:天玑AI全栈能力驱动体验跃迁
过去三年,联发科技天玑AI生态圈实现了跨越式发展,生态伙伴数量增长至240%,天玑AI开发套件下载量提升至440%。这背后依托的,是天玑旗舰移动平激进分子特的“超性能+超能效”双NPU架构。这套架构从硬件底层实现了算力的分层调度:高性能NPU负责大模型推理与复杂AI计算,而超能效NPU则专攻轻量级感知与常驻AI任务,在保障算力强度的同时,精准控制功耗,为智能体的全模态能力提供了坚实的硬件底座。
在此硬件基础上,联发科重磅发布了天玑AI智能体化引擎2.0。该引擎搭载了自研的SensingClaw低功耗全时感知技术,旨在构建“感知-决策-执行”的完整闭环。它能够赋能终端厂商打造原生的Agent OS,让设备能够主动捕捉环境信息、跨应用自主执行指令、实现跨端数据的无缝流转。更为关键的是,联发科已联合小米、传音等终端厂商,将系统原生Claw功能成功落地。这既验证了技术的可行性,也初步形成了“芯片-终端”协同的标准。整个过程数据在端侧处理,有效规避了云端传输可能带来的隐私泄露风险,精准契合了用户对数据安全的核心需求。
当然,端侧AI要想真正普及,必须跨越开发者门槛这道坎。模型适配复杂、内存占用过高、功耗优化困难、移植效率低下,这些难题让许多开发者望而却步。本次发布的天玑AI开发套件3.0,正是连接技术与应用的关键桥梁,它通过四大核心特性,致力于构建一个“低门槛、高效率、低成本”的端侧AI开发生态。

具体来看:其一,LVM模型可视化部署工具,将操作从命令行升级为图形化界面(GUI)模块化操作,参数实时生效,使得模型部署和调优效率提升了50%。其二,Low Bit压缩工具包,专门针对生成式AI模型进行优化,在相同画质下,模型压缩率提升58%,大幅降低了设备内存占用,让中低端终端也能顺畅部署AI应用。其三,eNPU开发工具包,充分释放超能效NPU的潜力,使常驻轻载AI模型的功耗节省高达42%,直击端侧AI长期运行的续航痛点。其四,天玑AI Partner模型转换助手,能够全自动将大型语言模型(LLM)移植至天玑平台,部署耗时节省90%,真正实现了“一键适配、快速落地”。
场景深耕:以游戏为突破口,验证智能体化体验的商业价值
移动游戏,早已成为智能手机的核心竞争力之一。用户的需求也从最初的“能玩”,升级为对“高帧率、高清画质、低延迟、强沉浸感”的综合追求。联发科依托天玑移动平台的强劲算力,通过星速引擎、光线追踪、倍帧调控、低延迟音频等全链路技术,构建了一套完整的移动游戏性能优化体系。其目标是与游戏厂商携手,不断突破画质、帧率与功耗的边界,推动手游体验从“移动端”向“3A级沉浸感”跨越。
游戏沉浸感的核心在于光影与画面的精细度。联发科率先在移动端落地了高端渲染技术。其Ray Tracing Pipeline移动端光线追踪技术,能够跨端适配PC与移动渲染管线,实时还原动态光影、骨骼动画乃至视野外物体的反射等细节,让手游的光影效果无限趋近端游水准。目前,该技术已与腾讯《三角洲行动》展开合作预研,未来将为玩家带来更具真实感的视觉体验。

与此同时,联发科携手团结引擎适配了虚拟几何体技术。依托天玑GPU强大的渲染能力,实现了在移动端渲染10亿级三角面,并在1.5K分辨率下可持续1小时满帧运行。这项技术突破了手游模型的精细度限制,让手机也能流畅运行高精度的3A级画质游戏,标志着手游画质进入了一个新纪元。
高帧率、低功耗、低延迟,是竞技手游体验的关键三角。联发科通过多项自研技术,致力于实现三者之间的最优平衡。天玑倍帧技术3.0新增了Depth选项,优化了虚拟帧的生成质量,并支持144/165Hz高帧率,适配手机、平板、座舱等多终端。《王者荣耀》已借助该技术解锁了144帧的低功耗体验,让高帧流畅不再以牺牲续航为代价。
天玑自适应调控技术5.0新增了智能帧控与场景预判功能,能够实时调度算力、优化出帧节奏,《鸣潮》利用该技术显著改善了1%低帧率与功耗问题。GPU Dynamic Cache架构优化了带宽调度,使得《逆战:未来》《暗区突围》能够实现满帧低功耗运行。而LE Audio低延迟技术则将蓝牙立体声延迟降至32毫秒,并在《和平精英》中落地应用,实现了音画同步、“指触即发”的竞技体验。
行业格局重塑:联发科以生态思维,抢占全场景智能时代话语权
纵观移动产业的发展历程,单一硬件性能的竞争空间已日趋有限。全栈技术能力与开放生态体系的结合,正成为下一阶段竞争的核心。联发科本次大会释放出的强烈信号,本质上标志着其战略重心正从“芯片硬件研发”,转向“技术+生态”双轮驱动的产业赋能者角色。

可以预见,全域芯智能时代正在加速到来。端侧AI的普及与移动游戏的体验升级,正在重塑整个移动产业的轨迹。联发科以MDDC 2026为契机,交出了一份兼具技术深度与生态广度的答卷:在端侧AI领域,它致力于破解落地痛点、降低开发门槛,推动智能体规模化普及;在移动游戏领域,它不断突破画质与帧率边界,优化体验细节,意图定义手游新标杆;而在更宏观的产业格局层面,它以开放的生态思维,积极抢占全场景智能时代的话语权。这场变革,才刚刚开始。




