
仅凭一张家用RTX 4090显卡的24GB显存,就能流畅运行一个拥有320亿参数的AI大模型,一口气读完6份长文档并自动生成周报?这并非极客魔改,而是来自MIT、英伟达与浙江大学研究者的最新突破。
这项名为TriAttention的技术,精准瞄准了大模型推理中的核心瓶颈——KV缓存显存占用。其核心思路巧妙:在预旋转位置编码(pre-RoPE)的空间内,利用查询(Q)与键(K)向量的三角集中度,动态评估每个键值(KV)对的重要性,从而智能地选择性保留最关键的部分。

形象地说,传统的KV缓存压缩如同将行李箱内所有物品(无论蓬松羽绒服还是沉重砖块)全部塞入压缩袋。而TriAttention的做法,则是先开箱仔细甄别,果断舍弃“砖块”,只精心打包真正有价值的“羽绒服”。这种基于重要性的KV缓存选择性保留策略,实现了内存占用的数量级下降。
实测性能:数据揭示显著提升
在AIME25数学推理基准测试中,TriAttention在完全保持全注意力机制(Full Attention)40.8%准确率的同时,将推理吞吐量提升了2.5倍。更重要的是,它将KV缓存的内存占用直接降低了10.7倍,大幅缓解了显存压力。
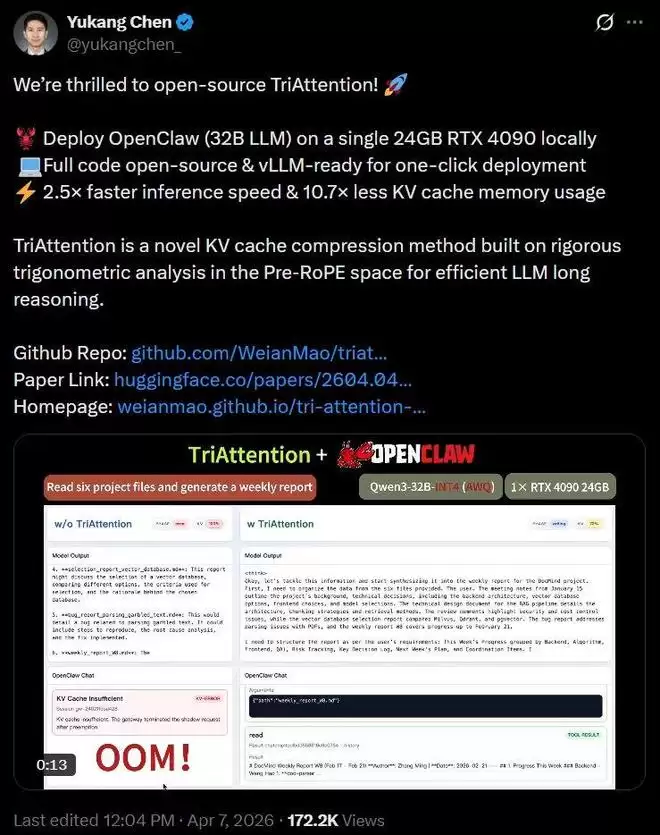
需要明确的是,此项技术主要优化的是KV缓存的内存,而非整个模型的参数量。但在处理长文本、多轮对话等长序列任务时,持续增长的KV缓存正是导致显存溢出的关键。解决此问题,直接决定了模型能否在有限资源下成功运行。
主要实验基于Qwen3-8B模型,覆盖了AIME24、AIME25、MATH500等多个评测任务。在生成长度达32K token的苛刻条件下,TriAttention几乎未损失任何模型精度,同时显著提升了推理效率。
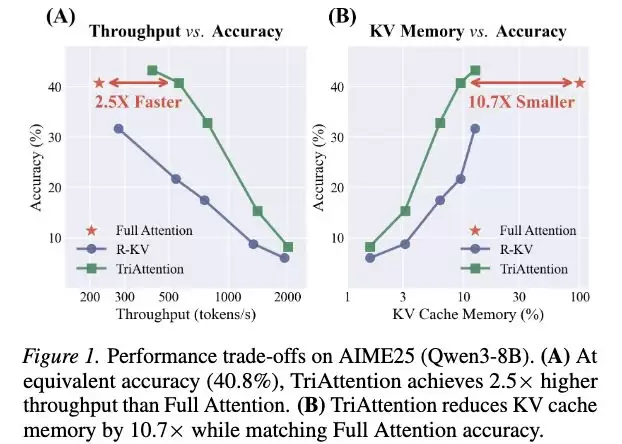
从论文到应用:单卡流畅运行320亿参数智能体任务
该技术的实用潜力在论文附录的真实部署案例中得以验证。场景为OpenClaw多轮智能体工作流,任务要求读取6份Markdown格式长文档,并自动生成汇总周报。
部署模型为经过AWQ INT4量化的Qwen3-32B,硬件仅为单张RTX 4090(24GB显存)消费级显卡。若不进行KV缓存压缩,冗长的系统提示和多轮文档读取将导致KV缓存急剧膨胀,显存瞬间耗尽。而启用TriAttention后,智能体顺利完成了全部文档阅读并输出了完整报告。
虽然此案例基于量化模型与特定智能体流程,但它有力证明:一个完整、具备实际生产价值的AI智能体任务,已可在消费级硬件上成功部署与运行。
工程化落地:vLLM插件与MLX实验性支持
TriAttention已走出学术论文,迈向工程实践。研究团队已在GitHub提供了与vLLM推理引擎的集成插件,详细说明了如何通过OpenAI兼容的API或Python API进行调用,并包含接入OpenClaw的指引。
这意味着,开发者无需修改模型架构或重新训练,只需像安装插件一样将其接入现有vLLM推理管线,即可即刻获得KV缓存压缩带来的性能收益,实现高效的大模型本地部署。
此外,针对Apple Silicon生态用户,仓库也提供了实验性支持文档,覆盖M1至M4全系芯片。该方案基于MLX框架与mlx-lm库运行,附带了示例代码与硬件基准测试,为大模型在Mac上的本地运行提供了新思路。
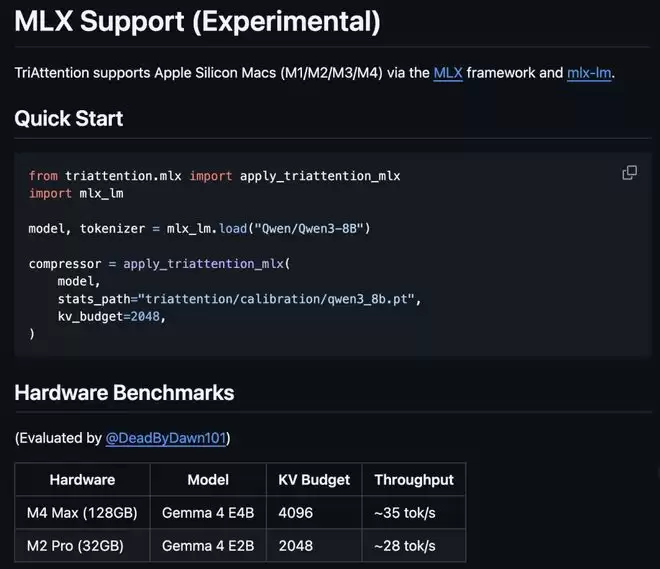
文档明确标注“实验性”,表明这仍是早期探索,距离成熟的Mac本地部署方案尚有距离,但技术方向已然清晰。
KV缓存压缩技术的两大路径
当前,KV缓存优化主要沿两大技术路线演进。
一是“量化派”,核心思路是降低数据表示精度。例如,Google Research近期推出的TurboQuant方案,旨在将KV缓存与向量搜索的比特数压缩至极低水平,同时宣称保持零精度损失。
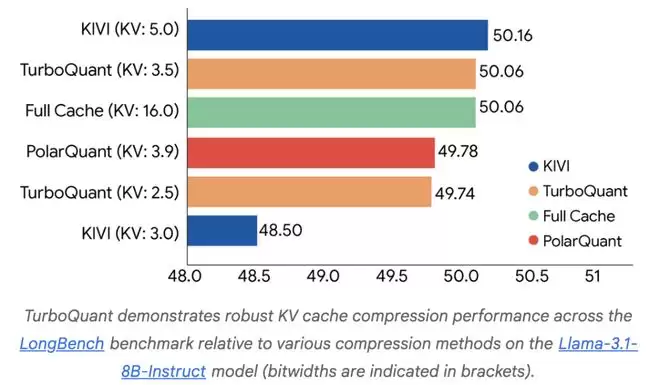
另一条则是“选择性保留派”,TriAttention正是此路径的最新代表。它不改变数据精度,而是通过智能算法判断,直接丢弃不重要的KV token,从根本上减少需存储的数据量。
两者终极目标一致:让大模型能在消费级硬件上流畅运行,避免显存溢出,保持精度稳定。但方法论迥异:前者是为每件行李“瘦身”,后者则是直接减少行李“件数”。理论上,两种策略可结合使用,潜力巨大。
目前社区尚缺在相同模型、硬件与任务下的严格对比,因此孰优孰劣尚无定论。但可以肯定,这两条技术路线都在加速向消费级部署场景推进。
回想一年前,“本地运行大模型”仍带实验色彩,运行70亿参数模型都需一番周折。如今,320亿参数模型在单张消费级显卡上完成复杂智能体任务,Apple Silicon上的MLX生态每周更新,vLLM插件让KV压缩变得“即插即用”。KV缓存压缩这项关键技术,正迅速从论文中的消融实验,转变为每位开发者触手可及的工程现实,推动着大模型本地部署的普及。