在AI智能体(Agent)发展进程中,如何让模型像人类一样流畅地操作网页,始终是一个关键且具有挑战性的课题。传统方法高度依赖与真实浏览器的直接交互,不仅成本高昂、效率低下,还常常面临网络延迟、访问限制和潜在安全风险。是否存在一种方案,能让AI在一个安全、可控且高效的“虚拟环境”中练习网页交互?阿里巴巴Qwen团队最新开源的WebWorld系列模型,为这一难题提供了极具前景的解决方案。
WebWorld是什么
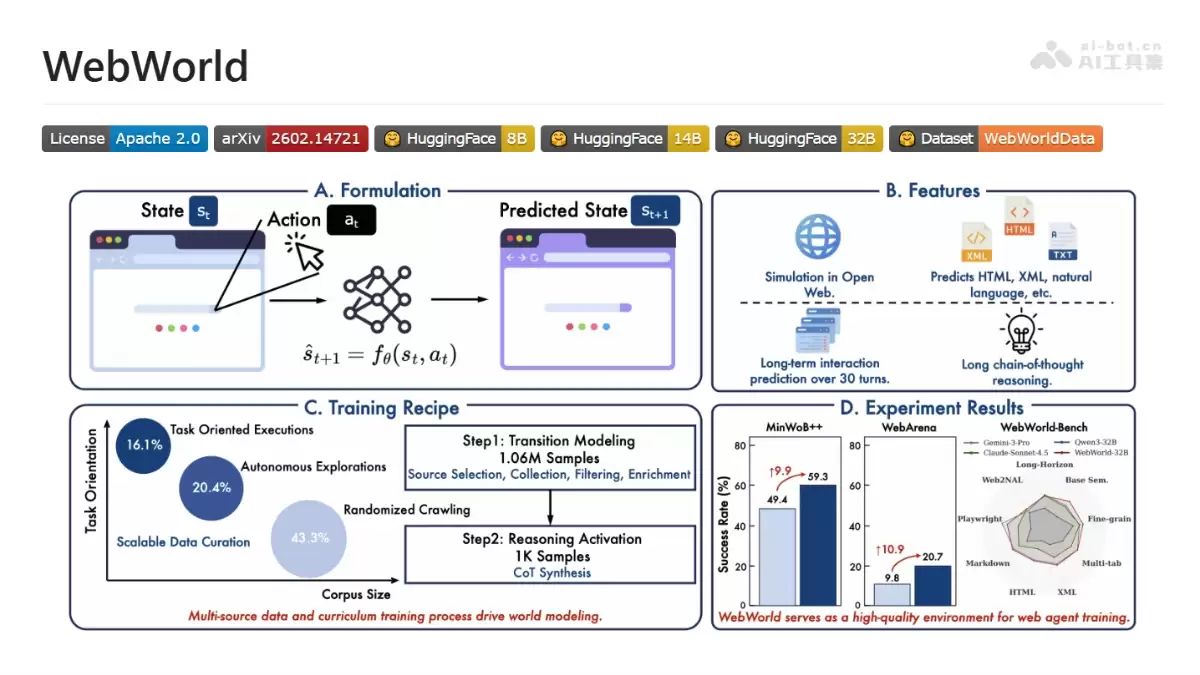
简而言之,WebWorld是一个大规模、开源的“网页世界模拟器”。它基于强大的Qwen3模型架构,提供了8B、14B和32B三种不同参数规模的版本。其核心功能在于模拟浏览器环境:当输入当前的网页状态(例如页面的HTML源码)以及智能体计划执行的动作(如“点击登录按钮”)时,WebWorld能够精准预测执行该动作后,下一个时刻的完整网页状态。
这相当于为AI智能体构建了一个高度逼真的“网页驾驶模拟舱”。智能体可以在此进行无数次无风险的练习,学习导航、表单填写、链接点击等操作,完全无需连接真实网络。这不仅规避了网络风险和速率限制,更能自动化生成海量的高质量训练数据。该模型支持多种网页状态表示格式,包括专为无障碍访问设计的A11y Tree、标准HTML/XML、Markdown以及自然语言描述,并能实现超过30步的长序列、一致性模拟。其显式的链式思考推理能力,也让模型的决策过程更加透明、可解释。
WebWorld的主要功能
这个“模拟器”具体具备哪些能力?其功能清单全面而强大:
- 网页状态预测:核心功能,精准模拟点击、输入、滚动等交互动作后的页面动态变化。
- 长时程多轮模拟:支持连续超过30步的复杂任务流程模拟,例如完成从商品搜索、比价、加入购物车到最终支付的全流程,并能保持状态的高度连贯性。
- 多格式状态表示:不局限于单一网页描述方式,原生支持A11y Tree,同时兼容处理HTML、XML等多种格式,具备出色的泛化与适应能力。
- 推理能力激活:通过独特的训练方法,模型在预测前会进行逐步的因果推理,使其思考过程不再是难以捉摸的“黑箱”。
- 跨领域泛化:不仅在网页操作任务上表现卓越,其技术思路在代码环境模拟、图形用户界面(GUI)自动化乃至游戏场景中也展现出良好的迁移潜力。
- 轨迹数据合成:它本身就是一个强大的数据生成工厂,能够为下游各类网页智能体模型,自动化合成大规模、多样化的训练轨迹数据。
WebWorld的技术原理
实现如此卓越的性能,得益于WebWorld背后一套坚实且创新的技术体系。深入理解其原理,有助于我们看清其核心价值。
自回归浏览器模拟器建模:研究团队将整个浏览器环境建模为一个自回归的序列生成任务。简言之,模型学习的目标是:在给定任务指令和完整的交互历史(包含所有过往的页面状态与执行动作)后,预测下一个页面状态的概率分布。通过在超百万条完整交互轨迹上进行端到端训练,模型逐步掌握了网页状态变化的复杂内在规律。
三层层次化数据收集管道:高质量模型离不开高质量数据。为突破封闭环境的数据瓶颈,WebWorld构建了一个堪称工程典范的三层数据收集策略:首先是“广度爬取”阶段,进行大规模随机网页抓取,奠定数据广度基础;其次是“自主探索”阶段,部署智能体进行主动交互,产生真实的长任务轨迹;最后是“任务导向”阶段,进行精准的指令合成,生成高质量、目标明确的任务数据。三层策略协同作用,最终收集了超过106万条来自真实开放网页的交互轨迹,数据规模达到了此前同类工作的百倍量级。
A11y Tree主状态表示与多格式增强:模型选择A11y Tree作为主要的网页状态描述方式,因其结构清晰、信息密度高,且对语言模型更为友好。为避免模型过度依赖单一格式而导致“过拟合”,团队通过事后格式转换,将每条轨迹数据扩展为HTML、XML、Markdown和自然语言描述共五种格式。这种多格式的指令微调策略,有效提升了模型的鲁棒性和对不同输入格式的泛化能力。
双层数据过滤与质量控制:海量原始数据中必然存在噪声。WebWorld采用了两道严格的过滤工序:首先使用规则脚本进行初步清洗,过滤无效链接和敏感内容;随后调用大语言模型,从可访问性、内容质量、信息完整性等多个维度进行精细评分,剔除低质量站点。对于单条交互轨迹,还会剪除无效的状态转移片段,并控制样本长度,确保最终训练数据的纯净与高效。
两阶段课程训练策略:训练过程并非一蹴而就,而是遵循了“先积累知识,后锻炼思维”的课程设计理念。第一阶段,让模型在百万级轨迹上进行大规模“观摩学习”,掌握普遍的网页动态规律;第二阶段,仅使用1000条精心合成的、要求进行链式思考(Chain-of-Thought, CoT)的数据进行微调,从而激活模型的显式推理能力,使其学会在预测前先分析页面结构、理解用户意图。
多维评估体系WebWorld-Bench:如何科学评估一个“世界”模拟得好坏?团队为此专门构建了WebWorld-Bench综合评估体系。它从两个核心维度出发:一是“事实性评估”,客观判断预测的状态是否准确反映了动作执行的因果效应;二是“图灵测试”,通过对抗性比较,检验模拟生成的网页与真实网页是否让人难以区分。这套体系从客观正确性和主观真实感两个层面,为模型能力提供了全面、扎实的度量标准。
如何使用WebWorld
对于开发者和研究人员而言,WebWorld的使用路径清晰明了:
- 环境准备:克隆项目代码仓库,安装所需依赖,解压提供的数据包即可完成基础配置。
- 模型加载:通过HuggingFace平台直接加载预训练模型权重,使用标准的Transformers接口进行模型初始化。
- 单步预测:构造包含系统提示和用户消息(当前状态 + 待执行动作)的对话格式,调用模型生成接口即可获得下一状态的预测结果。
- 多轮模拟:通过循环调用,将上一轮的预测结果作为新的历史状态输入,即可实现长达30轮以上的连续交互模拟。
- Agent训练:利用WebWorld合成的大量任务轨迹数据,对基础大语言模型进行指令微调或强化学习,可以显著提升智能体在真实评测基准上的表现。
- 基准评测:既可以使用项目自带的WebWorld-Bench进行模型内在能力的评估,也可以在MiniWob++、WebArena等外部标准测试环境中,验证基于WebWorld训练的智能体的实战效果。
WebWorld的核心优势
综合来看,WebWorld在以下几个关键维度上建立了显著优势:
- 规模领先:基于百万级真实开放网页交互轨迹训练,数据覆盖的广度与深度远超以往同类工作。
- 开源开放:模型、数据均以Apache 2.0协议开源,提供了完整、可复现的技术栈,极大降低了研究与开发的门槛。
- 评测体系完善:自研的综合性评估基准,为模型能力的衡量提供了科学、统一的标尺。
- 训练效率突出:仅需少量链式思考数据即可激活强大的推理能力,证明其预训练阶段的知识注入非常扎实有效。
- Agent训练增益显著:实际应用效果表明,使用WebWorld合成数据微调后的智能体,在WebArena等权威基准测试上取得了显著性能提升,部分版本的表现已接近顶级商用模型水平。
WebWorld的项目地址
所有相关资源均已向社区公开:
- GitHub仓库:https://github.com/QwenLM/WebWorld
- HuggingFace模型库:https://huggingface.co/datasets/Qwen/WebWorldData
- arXiv技术论文:https://arxiv.org/pdf/2602.14721
WebWorld的同类竞品对比
为了更清晰地定位WebWorld,我们将其与同期的主要竞品进行简要对比分析:
| 对比维度 | WebWorld | WebEvolver | UI-Simulator |
|---|---|---|---|
| 开发团队 | 阿里巴巴 Qwen Team | Fang et al. | Wang et al. |
| 技术路线 | 大规模开放网页预训练 + 两阶段课程微调 | 协同进化(世界模型与Agent交替微调) | 检索增强模拟(RAG + 提示专有LLM) |
| 环境范围 | 真实开放网页(百万级域名) | 封闭 benchmark 环境 | 封闭/受控环境 |
| 数据规模 | 106万+ 真实轨迹 | 依赖Agent回传数据,规模受限 | 无自有训练数据,实时调用API生成 |
| 模型形态 | 开源专用世界模型(8B/14B/32B) | 训练专用世界模型 | 提示通用LLM作为世界模型 |
| 长时程模拟 | 支持30+步一致模拟 | 有限 | 有限 |
| 显式推理 | CoT激活,可解释状态转移 | 无显式推理 | 依赖基础模型的隐式推理 |
| 开源情况 | Apache 2.0(模型+数据) | 未开源 | 非开源(依赖专有API) |
| 核心差异 | 以开放网页为根基,数据驱动规模化 | 以协同进化闭环优化,环境受限 | 以检索增强定向合成,成本受API限制 |
可以看出,WebWorld的核心差异化优势在于其基于真实开放互联网的大规模数据驱动,以及由此带来的强大泛化能力和开源开放性。
WebWorld的应用场景
这样一个功能强大的网页世界模型,拥有广阔的应用前景:
- Web Agent训练与评估:为网页操作智能体提供低成本、高效率的模拟训练场,加速其研发与迭代周期。
- 数据增强与合成:有效解决网页任务标注数据稀缺的痛点,自动化生成大量用于监督学习或强化学习的优质训练轨迹。
- 推理时规划与搜索:可集成到智能体的决策循环中,作为“前瞻模拟器”,帮助其在执行真实动作前,评估不同动作序列的潜在后果,从而选择最优执行路径。
- 跨领域世界模型研究:其技术框架为GUI自动化、代码环境模拟、游戏AI等更广泛的数字世界建模任务,提供了可迁移的范式参考。
- 浏览器自动化测试:模拟真实用户交互流程,用于网页的功能测试、兼容性检查和用户体验评估,显著提升前端开发与测试效率。
总而言之,WebWorld的出现,标志着网页智能体训练从依赖“实地驾驶”向依托“模拟训练”迈出了关键一步。它通过构建一个高保真、可扩展的网页模拟环境,不仅有效解决了训练成本与安全性的核心难题,更通过开源开放的方式,有力推动了整个AI智能体与自动化领域的研究进程。对于任何关注AI智能体开发、自动化测试或数字世界建模的研究者与工程师而言,这无疑是一个值得深入探索和集成应用的重要工具与基础设施。




