5月22日,阿里巴巴正式发布并上线了全新一代千问旗舰大模型——Qwen3.7-Max。用户现在即可通过千问APP、PC客户端及网页版免费体验这款性能强劲的国产AI模型。
体验方式非常简单:将手机上的千问APP更新至6.9.7或更高版本,点击界面下方的“Qwen3.7-Max”专属入口;或在电脑端的对话页面,直接从模型选择下拉菜单中切换至该模型即可开始使用。
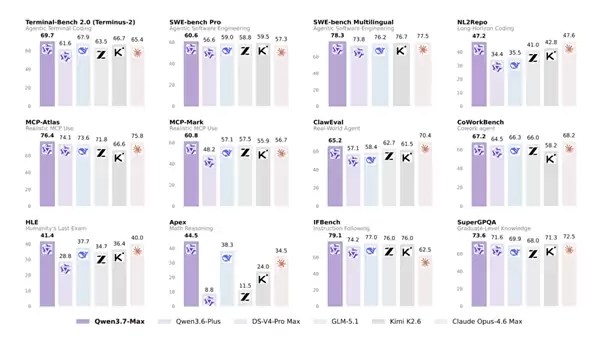
那么,Qwen3.7-Max的实际能力到底有多强?根据第三方评测机构Artificial Analysis最新发布的全球大模型排行榜,Qwen3.7-Max以56.6的综合得分位列全球第五,同时高居国产大模型榜首。
深入来看,该模型在多项核心能力评测中均展现出顶级水准,在编程、推理与智能体等关键赛道上取得了突破性进展。
编程与智能体能力:行业领先
在代码编程与智能体执行方面,Qwen3.7-Max表现卓越。在SWE-Pro、SWE-Multilingual等专业编程评测中,其成绩处于领先地位。特别是在Terminal Bench 2.0-Terminus测试中,它以69.7的高分超越了DeepSeek-v4-pro-Max、Claude-Opus4.6等众多国际知名模型。
在通用智能体能力上,它的进步同样显著。在贴近实际应用场景的MCP-Atlas、MCP-Mark以及Skillbench等评测中,其表现优于GLM5.1、Kimi-K2.6等同类模型,创造了国产模型的新纪录。此外,在Kernel Bench L3测试中,它还展现了出色的GPU内核优化与计算能力。
推理与综合能力:实现全面超越
复杂推理一直是衡量大模型实力的核心指标。Qwen3.7-Max在GPQA Diamond、HLE、HMMT 2026 Feb以及IMOAnswerBench等一系列高难度推理评测中,成功实现了对Claude-Opus4.6及所有其他国产模型的全面超越。
在通用能力与多语言理解方面,它的表现同样出色。在评估指令遵循精度的IFBench测试中,它以79.1分刷新了该榜单的最高纪录。同时,在涉及多语言理解与翻译任务的WMT24++和MAXIFE评测中,它也稳居领先位置。
总体而言,Qwen3.7-Max的发布不仅仅是一次版本更新,更是在编程开发、逻辑推理、智能体应用等多个关键维度上,将国产大模型的性能天花板提升到了新的高度。对于广大开发者、研究者和普通用户来说,能够免费使用到这样一款处于国际第一梯队的顶尖AI模型,无疑是一个巨大的利好。




