大模型通常被视为一个难以透视的“黑箱”,用户输入指令,模型输出结果,但其中的决策过程往往晦涩不明。如今,阿里通义千问团队开源了名为Qwen-Scope的可解释性工具,旨在揭开大模型内部运作的神秘面纱。该工具基于先进的稀疏自编码器技术,能够将模型内部复杂的参数计算,转化为人类可理解的概念与规律。简而言之,它不仅让我们得以“窥见”模型的思考过程,更能让我们主动“引导”模型的行为与输出。
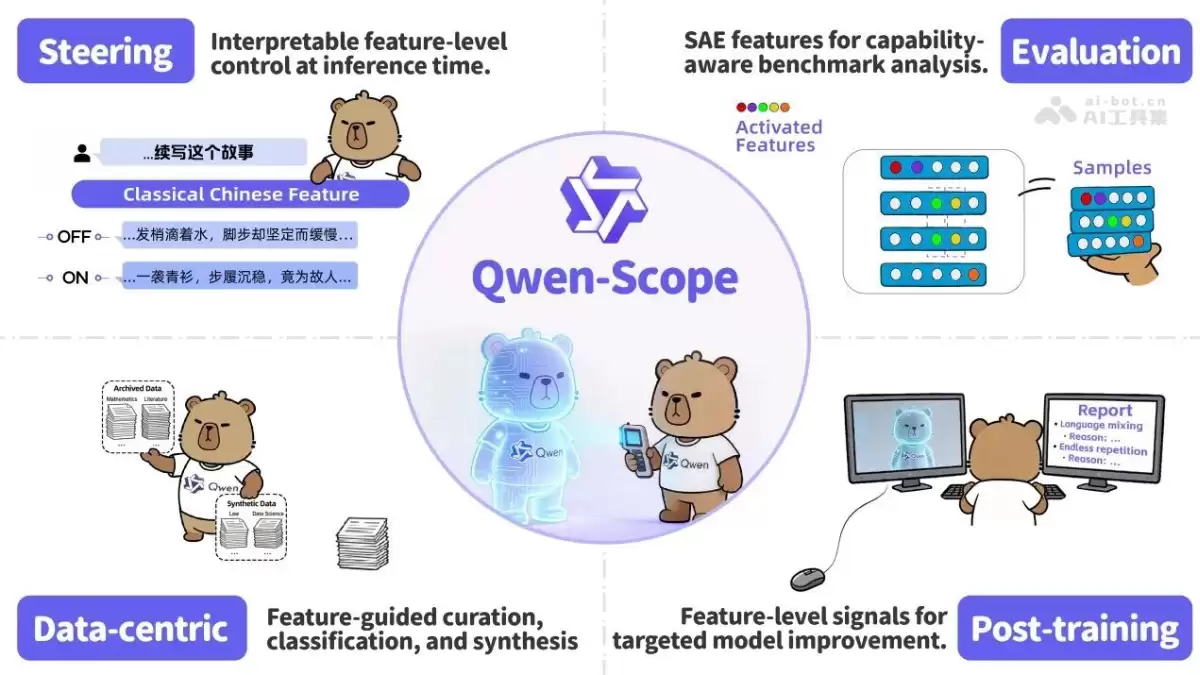
Qwen-Scope的核心功能
这套工具的核心价值在于,它将“可解释性”从一个被动的观察工具,升级为一个主动的行动引擎。具体而言,它主要提供四大功能:
第一,推理定向控制。 传统上,若要调整模型的输出风格或内容,往往需要复杂的提示工程或重新训练。而Qwen-Scope允许用户直接定位到与特定概念(例如“中文表达”、“毒性内容”、“古典文风”)相关的内部特征,通过简单地增强或抑制这些特征,即可实现精准的风格迁移或问题修复,无需任何额外的自然语言指令或模型微调。
第二,数据分类与合成。 在数据处理层面,它同样展现出高效能。例如,进行毒性内容识别时,不再需要海量的标注数据。仅需提供约200对正负样本作为种子,Qwen-Scope便能自动发掘具有高判别力的特征,实现无需额外训练的高精度分类。更强大的是,它还能识别出现有数据中“激活不足”的特征,从而定向合成补充样本,有效覆盖模型的长尾能力,提升数据集的完备性。
第三,模型训练优化。 在模型微调阶段,Qwen-Scope如同一个内置的“诊断仪”。它可以精准定位导致语言混用、重复生成等问题的异常神经元激活模式,并将这些信号作为辅助损失函数,引导模型在监督微调或强化学习阶段优化自身行为,实现更高效的训练。
第四,评测冗余分析。 评估一个模型性能通常需要多个数据集,但其中可能存在大量冗余测试。Qwen-Scope能够计算不同评测集所触发的内部特征模式的重叠度,从而量化评测集的冗余程度和能力覆盖广度,帮助团队筛选出成本更低、覆盖更全面的高效测试样本集合。
Qwen-Scope的技术原理
实现上述功能的关键,在于其采用的稀疏自编码器技术。其工作原理可分为以下几个步骤:
首先,在Qwen模型的每一层Transformer中,稀疏自编码器被插入到残差连接中。它扮演着一个高效的“翻译器”角色,通过施加稀疏性约束,将高维、稠密且难以理解的神经元激活向量,分解为一组稀疏的、可解释的“特征字典”。
其次,在训练过程中,每一层的SAE独立工作。编码器将激活映射到一个过完备的潜在空间,但为了确保特征高度解耦、各司其职,仅保留激活值最大的前k个(通常为50或100个)特征用于重建原始信号。
那么,如何确定哪个特征对应哪个具体概念呢?这里运用了对比特征识别方法。例如,要定位“中文”特征,就构造一组中文文本和一组非中文文本,对比两者在SAE特征上的平均激活差异,差异最大的特征方向,即被认为与“中文”概念强相关。
最后,在进行干预时,公式简洁而直接:h′ ← h + αd。其中h是原始残差,d是目标特征的方向向量,α是干预强度系数。通过调整α的正负和大小,即可在模型推理时实时增强或抑制某个特定特征,从而精准改变模型的最终输出。
如何使用Qwen-Scope
对于希望上手体验的研究者或开发者,使用路径已经非常清晰:
1. 访问体验平台:目前,项目已在Hugging Face和国内的魔搭社区(ModelScope)提供了在线演示空间,用户可以直接在网页上体验其核心功能。
2. 选择模型权重:根据你想要分析的目标模型(如Qwen3-8B或Qwen3.5-27B),加载对应的预训练SAE权重文件。
3. 输入提示观察激活:输入一段提示词,系统会展示出所有SAE特征的激活热力图和排名,让你直观看到模型内部哪些“概念”被强烈触发。
4. 识别目标特征:结合已知的特征ID(例如,研究已标识出“中文特征6159”、“古典中文特征36398”)或通过对比分析,定位到你想要干预的特定特征。
5. 调整干预强度:设置特征干预系数α。正值会增强该特征的影响,负值则会抑制它。
6. 验证控制效果:对比干预前后模型的生成结果,确认是否实现了预期的风格转变或问题修复。
7. 集成训练流程:对于更深入的模型优化,可以将SAE提供的特征激活信号,作为额外的损失项接入SFT或RL的训练流程中,实现定向、高效的模型行为修正。
Qwen-Scope的关键信息与使用要求
为了让你对这套工具有更全面的了解,以下是其关键的技术规格与信息:
- 发布方:阿里巴巴 / 通义千问团队
- 覆盖模型:目前支持Qwen3-1.7B/8B、Qwen3-30B-A3B、Qwen3.5-2B/9B/27B/35B-A3B,共计7个不同规模的模型版本。
- 模型类型:既支持标准的稠密模型,也支持混合专家(MoE)架构。
- SAE权重:开源了14组SAE权重,覆盖了模型全部的Transformer层。
- 训练数据:SAE训练时,从各模型的预训练数据中采样了约0.5B(5亿)词元。
- 特征维度:提供了32K、64K、80K、128K等不同规模的过完备特征字典。
- 表示重构特征数:在重建激活时,仅使用激活值最高的前50或前100个特征。
- 在线体验:可通过Hugging Face或魔搭社区的在线空间直接试用。
Qwen-Scope的核心优势
与传统的模型可解释性工具相比,Qwen-Scope的突破性在于实现了从“观察诊断”到“手术干预”的跨越。其具体优势体现在:
功能闭环: 它不仅满足于解释现象,更致力于解决问题,将可解释性直接转化为驱动模型优化与进化的核心引擎。
干预高效: 在推理阶段即可实现零权重修改的精准干预,无需耗时耗力的模型微调,就能实时改变输出行为,响应迅速。
数据友好: 在数据分类等任务上,仅需约200对种子数据就能达到0.90以上的F1分数,极大降低了对高质量标注数据的依赖和成本。
优化精准: 能够直击训练痛点。例如,在SFT阶段针对性地抑制导致中英文混用的异常特征,可以将混入率从0.81%显著降低至0.22%。
成本意识: 通过特征覆盖度分析来优化评测集,帮助团队用更少的测试样本获得更全面的能力评估,直接节约了评测成本与时间。
Qwen-Scope的项目地址
所有相关的模型权重、源代码和技术文档均已开源,方便社区研究与应用:
- HuggingFace模型库:https://huggingface.co/collections/Qwen/qwen-scope
- 技术论文:https://qianwen-res.oss-accelerate.aliyuncs.com/qwen-scope/Qwen_Scope.pdf
Qwen-Scope的同类竞品对比
在AI模型可解释性领域,另一个知名的开源项目是Google DeepMind的Gemma Scope。将两者进行对比,能更清晰地看到各自的特点与定位:
| 对比维度 | Qwen-Scope | Gemma Scope |
|---|---|---|
| 发布方 | 阿里巴巴 / 通义千问 | Google DeepMind |
| 覆盖模型 | Qwen3 / Qwen3.5 系列(7个模型) | Gemma 2 / 3 系列 |
| 架构支持 | 稠密模型 + MoE | 稠密模型 |
| SAE架构 | Top-k SAE | JumpReLU SAE |
| 开源规模 | 14组SAE权重 | 400+ SAEs,3000万+特征 |
| 核心应用 | 推理控制、评测分析、数据合成、训练优化 | 机制解释、安全分析、电路追踪 |
| 数据合成 | 特征驱动合成,数据能效比提升约15倍 | 主要依赖传统合成方案 |
| 评测分析 | 支持benchmark冗余与覆盖度分析 | 侧重特征可视化与交互探索 |
| 中文支持 | 原生支持,含古典中文等特色风格特征 | 主要面向英文场景 |
| 交互平台 | Hugging Face / 魔搭社区 | Neuronpedia |
可以看出,Qwen-Scope在应用导向上更为突出,特别是在推理干预、中文场景支持和数据合成效率方面具有独特优势。而Gemma Scope则在特征可视化和基础解释的规模上更为庞大。
Qwen-Scope的应用场景
综合来看,这套工具在多个实际应用场景中都能发挥重要作用:
推理控制与即时修复: 最直接的应用,例如快速修复模型在回答英文问题时意外混入中文的“语言混用”问题;或者一键将现代白话文转换为古典文言文风格,实现高质量、可控的风格迁移。
安全数据治理: 在内容安全与治理领域,它可以基于特征快速进行多语言毒性内容分类。更关键的是,能定向合成安全对齐所需的训练数据。实验表明,仅用4K条合成数据,就能达到接近120K条真实数据的安全对齐效果,效率提升显著。
模型训练全流程辅助: 在SFT阶段,通过SAE辅助损失抑制不良特征;在RL阶段,通过操控与“重复”相关的特征,提高异常回复在采样中的出现频率,从而让奖励模型更快地学会识别并纠正它,加速训练收敛。
评测体系优化: 面对GSM8K、MATH、MMLU-Pro等多个数学推理评测集,可以通过分析它们之间的特征重叠矩阵,科学地剔除冗余评测,构建更高效、全面的模型评测体系。
开放研究基石: 作为一套完全开源的基础设施,它为学术界和工业界提供了深入研究模型机理、追踪内部电路、分析幻觉与偏见根源的宝贵工具,有望推动整个大模型可解释性领域的发展。
总而言之,Qwen-Scope的推出,标志着大模型可解释性研究从“是什么”走向了“怎么办”的新阶段。它不再仅仅是一份诊断报告,更是一套精密的手术刀和增强引擎,让开发者能够更深入、更主动地理解、诊断并最终塑造AI的行为与能力。




