5月20日,在备受瞩目的阿里云峰会上,全新一代千问旗舰模型Qwen3.7-Max正式发布。这不仅是阿里云大模型技术的一次重大迭代,更标志着国产大模型在核心能力上实现了关键性突破,向国际顶尖水平看齐。
根据全球权威大模型盲测平台Arena的最新榜单数据显示,Qwen3.7-Max的综合表现已全面超越Kimi-K2.6、DeepSeek-v4-pro、GLM-5.1等国内主流模型。其整体实力与GPT-4o、Claude 3.5 Sonnet、Gemini 2.0等国际最新旗舰模型同处第一梯队,稳居国产大模型排行榜首位,堪称“国产第一模型”。
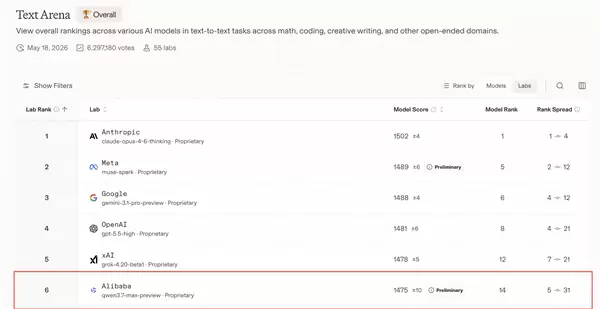
回顾其发展历程,从Qwen3.5到Qwen3.6,再到如今的Qwen3.7-Max,千问旗舰系列在短短三个月内完成了三次重大版本升级。如此高频的迭代节奏,充分展现了阿里云在大模型研发上的深厚积累与加速态势。
面向智能体场景的全新设计
本次发布的Qwen3.7-Max,其核心设计理念明确聚焦于智能体(Agent)应用场景,并在多个关键维度实现了显著提升。
编程能力是构建实用智能体的基础。在SWE-Pro、SWE-Multilingual等编程智能体权威测评中,Qwen3.7-Max均取得了领先成绩。特别是在终端编程基准测试Terminal Bench 2.0-Terminus中,其以69.7的高分超越了DeepSeek-v4-pro-Max和Claude-Opus4.6等强劲对手,展现了卓越的代码生成与复杂问题解决能力。
在通用智能体能力方面,该模型在MCP-Atlas、MCP-Mark、Skillbench等一系列贴近真实业务场景的测试中表现同样出色,成功超越了GLM5.1、Kimi-K2.6等国内同行,创造了国产大模型在该领域的新纪录。
推理与通用能力的全面领先
强大的逻辑推理能力是衡量大模型智能水平的核心指标。在GPQA Diamond、HLE、HMMT 2026 Feb等高难度推理评测中,Qwen3.7-Max不仅力压所有国产模型,甚至超越了Claude-Opus4.6这样的国际顶级选手,展现出顶尖的推理实力。
其通用任务处理能力同样出众。在评估模型理解与执行复杂指令的IFBench评测中,Qwen3.7-Max获得了79.1的高分,刷新了该榜单纪录。同时,在多语言理解与生成评测WMT24++和MAXIFE中,它也保持了显著的领先优势,证明了其强大的跨语言处理能力。
一场持续35小时的“极限挑战”
如果说标准基准测试是“开卷考试”,那么下面这项实战任务,则堪称一场对模型自主能力的“闭卷极限挑战”。
在一个模型训练时完全未接触过的新硬件平台——平头哥真武M890芯片上,Qwen3.7-Max被赋予了一项极具挑战的任务:自主优化推理内核。关键在于,它没有得到任何现成的性能分析数据、硬件架构文档,甚至没有参考示例代码。一切从零开始,完全自主探索。
最终,模型独立、连续运行了长达35小时。在此期间,它自主进行了432次内核性能评估和1158次工具调用,完整地走完了代码编写、编译、性能分析、迭代优化的全流程。整个过程完全自主,无任何人工干预。
结果令人震撼:经Qwen3.7-Max优化后的推理内核,相比SGLang Triton的最新参考实现,取得了高达10倍的性能加速。这一成绩,是对其强大自主探索与工程优化能力的硬核证明。
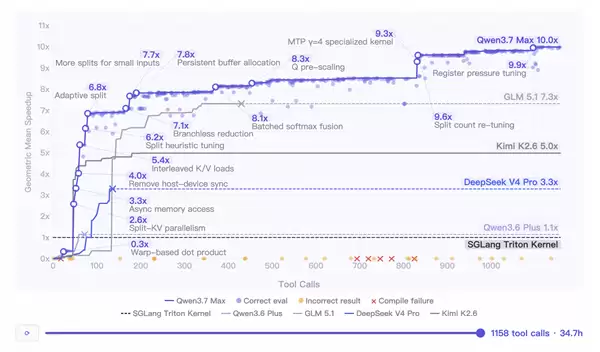
更令人印象深刻的是测试轨迹所展现的持久创造力:模型在独立运行超过30小时后,依然能够发现有效的性能优化点,甚至主动发起了一次关键的架构重设计。这种在长周期、复杂任务中保持的持续创新能力,正是高级智能体走向实用化所必需的核心特质。
智能体能力的泛化与协作
一个真正优秀的智能体,必须具备良好的框架泛化能力。Qwen3.7-Max展现出了出色的跨框架适应性,无论是在Claude Code、OpenClaw还是其自家的Qwen Code框架下,都能稳定发挥其高效能。
此外,通过深度融合MCP(模型上下文协议)与先进的多智能体协作技术,该模型在办公自动化基准SpreadSheetBench-v1上斩获了87分的顶尖成绩。这意味着它在处理如电子表格操作这类步骤繁琐、逻辑复杂的实际办公任务时,已具备极高的实用价值和可靠性。
据阿里云官方透露,Qwen3.7-Max的API服务即将在阿里云百炼平台正式上线。后续,阿里云还将推出包括Qwen3.7-Plus在内的更多版本,旨在全面覆盖从编程开发、通用任务到视觉理解等全场景智能体应用需求。国产大模型的生态竞争与落地应用,显然已进入一个全新的深度发展阶段。




