4月22日晚,阿里云正式开源了通义千问3.6系列的最新成员——Qwen3.6-27B。这款拥有270亿参数的大语言模型,在核心的智能体编程能力评测中表现卓越,其性能足以对标千亿参数级别的顶级模型,刷新了千问系列在“智能密度”指标上的最高纪录。作为当前全球开源社区最受瞩目的稠密模型之一,其最大亮点在于仅需消费级显卡即可流畅部署,这为AI智能体编程的广泛落地应用开辟了极具潜力的新路径。
“智能密度”是衡量模型效率的关键概念。在推理过程中,稠密模型的每一个参数都会被激活。因此,提升模型整体智能水平的核心,在于深度挖掘每个参数的潜力,实现单位参数承载更高“智能”。Qwen3.6-27B正是通过一系列前沿技术与工程优化,实现了稠密模型智能密度的重大突破,从而涌现出媲美旗舰级模型的强大智能体编程能力。
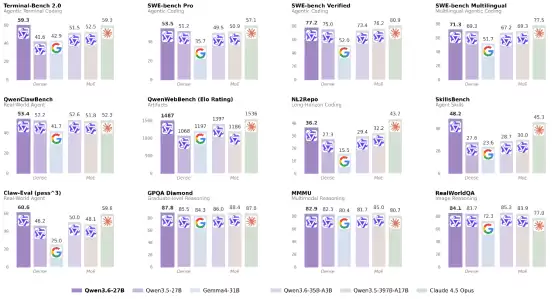
权威基准测试数据充分印证了其强大实力。在SWE-bench、Terminal-Bench 2.0、SkillsBench、QwenWebBench、NL2Repo等一系列评估真实世界编程任务的权威榜单中,Qwen3.6-27B的成绩极为突出。它不仅显著超越了Gemma4-31B、Qwen3.5-27B等同类竞品,甚至超越了参数量高达其15倍的Qwen3.5-397B-A17B等开源巨模型。尤为引人注目的是,其综合表现已可媲美Claude Opus 4.5这样的顶级闭源模型。
将智能密度提升至新高度的Qwen3.6-27B,带来的最直接变革是:许多以往需要依赖庞大参数模型或混合专家架构才能处理的复杂编程任务,如今通过本地部署即可高效完成。这使得它有望成为OpenClaw等“龙虾”应用或Hermes Agent框架下最可靠的本地AI“大脑”。
此外,得益于其原生的多模态理解能力,Qwen3.6-27B不仅能精准解析代码逻辑与开发者意图,还能直接“读懂”设计稿、UI界面截图、系统报错弹窗等真实的图像与视频信息。这种跨模态理解能力,使其在工具调用、任务规划、多轮迭代等关键环节能做出更符合实际开发场景的决策,从而为智能体完成理解需求、核实信息、执行操作、汇总结果等一系列复杂的长链条任务,提供了更稳定、更强大的核心支撑。
通义千问系列的每一次迭代开源都备受全球AI开发者关注,而27B这个参数规模正是社区开发者票选出的最热门尺寸之一。回顾一个月前,Qwen3.5系列中小尺寸模型开源时,连埃隆·马斯克都曾称赞其“智能密度令人印象深刻”。当时的Qwen3.5-27B模型在全球AI社区掀起了一股创新应用热潮——经量化后,它仅需单张RTX 4090显卡即可流畅运行,被广泛视为性能与部署成本之间的“黄金平衡点”。
开发者社区的活跃实践是最好的证明:有开发者基于它搭建了支持多人在线的文本冒险游戏平台,有人将其部署在个人笔记本电脑上作为全天候的私人编程助手,更有企业团队利用它构建了内部高效的知识库问答系统。行业观察家普遍认为,随着性能更强的Qwen3.6-27B正式发布,这些已蓬勃发展的AI应用生态,将迎来新一轮的能力升级与体验优化。
目前,Qwen3.6-27B的模型权重已在魔搭ModelScope社区和Hugging Face平台全面开源,个人开发者与企业用户均可免费下载并用于商业用途。用户也可以通过通义千问官方平台Qwen Studio直接在线体验新模型,或通过阿里云百炼平台调用其API服务。截至目前,阿里云通义千问累计开源模型数量已超过400款,基于其衍生的全球模型数量突破20万个,总下载量超过10亿次,持续领跑全球开源大模型领域。




