谷歌AI助力数学研究突破群论难题牛津团队取得新进展
数学界悬而未决的难题清单上,又增添了一则由人工智能辅助破解的里程碑案例。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
困扰群论领域数十年的第21.10号问题,近期被牛津大学数学家Marc Lackenby成功解决。而他的关键合作者,正是谷歌DeepMind最新发布的“AI联合数学家”系统。整个破解过程颇具戏剧性:AI最初生成的证明存在一个漏洞,正是系统内部的“审查员”智能体发现了这一错误。Lackenby在看到被指出的漏洞后,灵感迸发——“等等,我知道如何填补这个缺口”。经过数轮人机之间的反复推敲与验证,这道长期悬置的难题最终得以攻克。
这不仅仅是一则关于AI解答数学题的消息。它更深刻地标志着,人工智能在数学研究中的角色,正从被动的“解题工具”向主动的“研究伙伴”进行根本性转变。
“AI联合数学家”系统详解
简而言之,它并非一个简单的问答式聊天机器人,而是一个支持异步协作、具备状态记忆的协同工作平台。你可以将其理解为一个配备了顶尖智能助手的虚拟研究工作室。
系统顶层设有一个“项目协调者”智能体,负责整体规划与任务调度。当数学家上传一篇论文或提出一个研究构想后,这位“协调者”不会立即给出答案,而是会像真正的科研合作者一样,首先与用户进行对话,帮助澄清、细化和精准定义问题。

随后,它会将复杂问题分解为多个子任务,并调度多条研究线索并行推进:一条线索负责文献调研与背景知识检索;一条线索负责搭建计算与验证框架;另一条线索则尝试不同的证明策略与路径。每条工作流都有其专属的协调智能体,它们异步运行,互不干扰。尤为关键的是,数学家可以随时介入任何一条线索,进行引导、修正甚至直接接管。
如果某个智能体在探索中陷入困境,它不会保持沉默或简单重启,而是会主动在聊天界面中向人类研究者发出求助信号。这一设计理念的核心,在于其对“失败”的独特认知与利用。
系统会持久化地记录所有失败的假设与走不通的路径,不会轻易丢弃这些信息。在数学探索中,明确“哪些路不可行”与找到“哪条路可行”往往具有同等重要的价值。这些“负向探索空间”被系统完整保存,成为后续研究的重要上下文,有效避免了重复踏入相同的死胡同。
其最终产出也完全符合学术规范:并非杂乱的对话记录,而是附带详细边际注释、引用来源清晰可溯的LaTeX格式文档,可直接作为论文初稿使用。
这背后有一个精妙的类比:在软件工程领域,我们已经拥有了如Claude Code、Cursor这类集成了持续迭代、版本控制和测试验证的AI编程环境。然而,数学研究领域长期以来一直缺乏一个对等的、专为研究流程设计的“智能编排层”。“AI联合数学家”系统的诞生,正是为了填补这一空白。
与先前系统的本质区别
它的定位,与DeepMind此前开发的系统(如AlphaEvolve)有着根本性的不同。
AlphaEvolve更像一个高度自主的“算法发现引擎”:输入问题,它通过进化算法自行搜索更优解,人类基本处于循环之外。而“AI联合数学家”则强调数学家必须“始终在协作回路之中”。它的目标并非替代人类完成整个研究过程,而是在最恰当的时机提出问题、提供辅助,将人类研究者独有的直觉、审美判断和战略眼光,与AI强大的信息检索、海量计算和逻辑验证能力进行深度融合。
前者是“请帮我找到一个更优的算法”,后者则是“陪伴我将这个研究方向深入探索数周”。
刷新最难数学AI基准测试纪录
在衡量人工智能数学能力的“硬核”测试中,这套系统同样交出了一份令人瞩目的成绩单。
它在当前公认难度最高的数学AI基准测试——FrontierMath的Tier 4级别上,取得了48%的准确率,刷新了该领域的最高纪录(SOTA)。作为对比,GPT-5.5 Pro和GPT-5.4 Pro在同一测试中的成绩分别为39.6%和37.5%。

FrontierMath基准包含350道原创高难度数学题目,覆盖现代数学各大核心分支。其中的Tier 4级别仅包含50道题,被其开发者Epoch AI描述为“其中部分问题可能在未来数十年内都难以被AI攻克”,人类专家解决其中一道通常也需要花费数天时间。
“AI联合数学家”在48道非公开题目中成功解答了23道。值得关注的是,其底层基座模型Gemini 3.1 Pro单独参加同一测试时,准确率仅为19%。从19%跃升至48%,这29个百分点的巨大提升,并非源于基座模型本身“智力”的飞跃,而几乎完全归功于系统层面精心的流程编排:并行调查机制、强制性的审查循环、高效的文献检索工具以及持久化的代码执行基础设施。
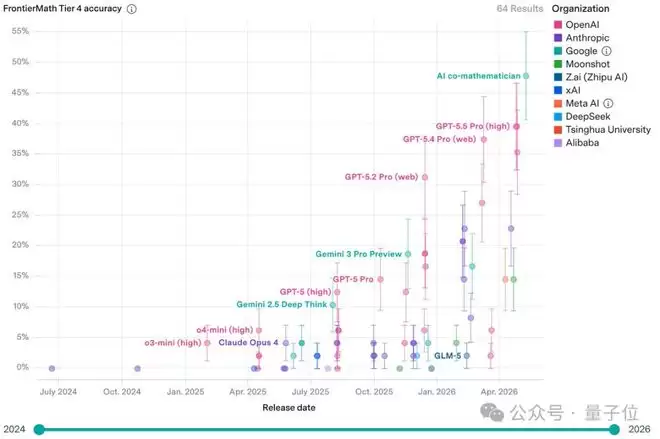
更值得深思的是,其中有3道题目是此前所有AI系统均未能攻克的全新难题。
真实世界的研究合作案例
除了基准测试,相关研究论文中还披露了三位数学家将其应用于实际研究的案例:
除了开篇提到的Marc Lackenby解决群论难题,数学家Semon Rezchikov在哈密顿系统研究中,向系统提出了一个技术性的子问题,并成功获得了一个关键引理的证明。他评价道,其他AI系统在相同提示下全部失败,且该证明从“数学美学”角度看,是他所用过的模型中风格最为出色的。
另一位数学家Gergely Bérczi,则利用该系统完成了关于Stirling系数对称幂表示的一个猜想证明。
光环之下的挑战与深层思考
当然,论文也坦诚地揭示了系统当前存在的失败模式与潜在问题。
第一种被称为“讨好审稿人偏差”:智能体可能会反复改写一个存在缺陷的论证,直到AI审稿人无法再发现错误——但漏洞实际上依然存在,只是变得更加隐蔽。
第二种是“死亡螺旋”:当迭代评审过程无法达成共识时,多个智能体可能会陷入无限的相互审稿循环,导致推理质量逐渐退化,甚至产生事实幻觉。
此外,还存在更深层的结构性挑战。当AI能在几分钟内生成一篇长达20页的证明草稿时,依赖志愿者、通常耗时数周甚至数月的人类同行评审体系将面临前所未有的压力。同时,AI虽然擅长逻辑核验、发现代数错误或找出缺失引用,但它们仍然缺乏判断一篇论文的优雅性、深刻性或其真正数学价值所需的整体性直觉。过度依赖AI评审,可能导致人类宝贵的定性判断能力被边缘化。
关于48%的基准测试成绩,论文也做了特别说明:这是在特殊条件下取得的(每道题给予48小时时间、无token数量限制、使用团队自有基础设施),与Epoch AI的标准评估框架并不完全可比。这体现了研究团队在评估透明度上的严谨态度。
背后的顶尖研发团队
“AI联合数学家”项目汇聚了18位作者,其中不乏人工智能与数学交叉领域的明星学者与工程师。
第一作者兼通讯作者Daniel Zheng,是谷歌DeepMind的研究工程师,专注于编程语言与机器学习的交叉研究。在2024年帮助AlphaProof获得国际数学奥林匹克(IMO)银牌的项目中,他主导了非形式化证明系统的开发。

另一位关键人物Alex Davies,是从AlphaProof、AlphaEvolve到“AI联合数学家”这一系列技术路线的连续参与者和重要连接者。

通讯作者Pushmeet Kohli,作为谷歌DeepMind的科学副总裁兼Google Cloud首席科学家,主导了AlphaFold、AlphaProof、AlphaEvolve等一系列里程碑式项目。

此外,团队中还包括来自多伦多大学的统计学家Daniel M. Roy,以及来自哈佛大学、专注于AI可解释性与人机交互研究的Fernanda Viégas和Martin Wattenberg。后两位所在的PAIR(人机协作)团队,在很大程度上解释了为何该系统在“如何让数学家愿意并高效使用”的人机交互细节上如此匠心独运。


值得一提的是,成功解决群论难题的数学家Marc Lackenby并非临时找来测试的外部人员。根据其牛津大学个人主页的论文列表显示,他早在2024年就已与DeepMind团队合作在《自然》杂志上发表论文,是该团队的长期合作者。

谷歌的AI数学战略布局
将视野放宽,这是谷歌在“AI for Math”(人工智能助力数学)方向上持续战略布局的最新关键一步。
2024年,AlphaProof利用强化学习进行形式化数学推理,达到了国际数学奥林匹克(IMO)银牌水平。2025年,Gemini Deep Think在当年的IMO中达到了金牌水准。AlphaEvolve则另辟蹊径,通过自主发现新算法,在数十个开放数学问题上改进了已知的最优解。
“AI联合数学家”与这些前辈系统的定位截然不同,它并非追求成为更强大的“单一问题求解器”,而是旨在成为深度融入研究者日常工作的“智能协作平台”。这标志着该领域正从追求“单点技术突破”向构建“完整研究基础设施”演进。
目前,该系统仍处于限量发布与测试阶段。Pushmeet Kohli表示,未来的目标是向更广泛的研究者群体开放这一协作范式。它或许尚未成为所有数学家触手可及的日常工具,但它已经清晰地证明了一件事:人工智能与数学家之间的协作,其深度、广度与有效性,早已超越了简单的问答交互范畴。
论文地址:https://arxiv.org/abs/2605.06651
相关攻略

谷歌DeepMind推出“AI联合数学家”系统,协助牛津大学教授解决群论难题。该系统作为异步协同工作空间,通过多智能体并行处理任务并允许人类介入引导,刷新了数学AI基准测试纪录,并在真实研究中推动关键进展。这标志着AI正从解题工具转变为深度研究伙伴,但仍面临“讨好审稿人偏差”等挑战。

让AI像人类一样“冲浪”:A venir-Web如何破解网页操作的三大难题 你是否遇到过这种情况:让AI助手帮你完成一个稍复杂的网页操作,比如预订一张特定条件的机票,或者填写一份多步骤的在线表格,结果它要么点错按钮,要么在页面间迷失方向,最后只能尴尬地告诉你“任务失败”? 这正是当前许多网页智能体(

月之暗面发布Kimi k1 5多模态思考模型,实现SOTA级多模态推理能力 AI大模型领域的竞争,正在从单纯的“博闻强记”转向更深层次的“推理思考”能力。这不,新年刚开局,月之暗面就投下了一枚重磅“思考冲击波”。1月20日,该公司正式发布了Kimi全新SOTA模型——k1 5多模态思考模型。这个新名

阶跃星辰发布StepAudio 2 5 ASR:推理提速400%,长音频处理迎来新突破 4月24日,阶跃星辰正式推出了新一代自动语音识别模型StepAudio 2 5 ASR。这款模型主要瞄准语音转写与长音频处理场景,在架构上玩了个新花样——引入了Multi-Token Prediction(多To

等等——高德也闯入具身智能赛道了? 一个国民级的导航应用,突然和机器人、机器狗这些“铁家伙”联系在了一起,这事儿乍一听确实让人有些意外。难道高德也开始跟风搞噱头了? 但深入了解后才发现,这并非噱头。高德不仅拿出了实打实的技术,其成果更是跻身全球第一梯队。 核心在于,高德发布了首个面向AGI的全栈具身
热门专题







热门推荐

鸿蒙智行全新一代问界M9Ultimate领世加长版已现身工信部申报目录。新车外观延续家族设计,尺寸显著加长,长宽高分别为5402 2026 1845mm,轴距达3236mm,并可选装豪华轮毂。动力上搭载2 0T增程器与三电机系统。该车型已于4月22日开启预售,预售价66 98万元起,预计将于今年5

微信输入法近日发布Windows2 0 0和iOS3 3 0版本更新,核心新增“隔空传送”功能。该功能支持用户跨设备或与附近他人快速传输图片、视频及文件,可通过扫码连接实现无需流量的面对面秒传。此功能于本月初结束内测后正式上线,显示出微信输入法正从单纯的输入工具向多场景效率工具延伸。

本文探讨了比安(Binance)平台的可靠性,分析了其在安全风控、合规进展及用户体验方面的表现。同时,结合当前市场格局,对2026年值得关注的交易平台趋势进行了展望,包括去中心化衍生品、高性能公链生态及合规创新等方向,为用户提供参考。

实现Git免密登录需将远程仓库地址从HTTPS切换为SSH格式,并配置密钥认证。首先生成ed25519类型密钥对,启动ssh-agent并添加私钥,再将公钥完整粘贴至GitHub等平台。最后使用gitremoteset-url命令更新远程地址为git@host:user repo git格式。操作后需确认地址已更改,并注意Windows环境下密钥需手动重复加

C盘空间常因文档、图片等文件默认存储而不足。可通过系统设置批量修改新内容保存位置至D盘,或直接重定向“文档”“图片”文件夹物理路径。必要时可修改注册表强制覆盖路径,并为MicrosoftStore应用与主流浏览器单独配置安装及下载目录。这些方法能将文件默认存储迁移至非系统盘,有效释放C盘空间。