2秒钟转写5分钟音频!国产新语音模型拿下多项SOTA,定价骤减90%
阶跃星辰发布StepAudio 2.5 ASR:推理提速400%,长音频处理迎来新突破
4月24日,阶跃星辰正式推出了新一代自动语音识别模型StepAudio 2.5 ASR。这款模型主要瞄准语音转写与长音频处理场景,在架构上玩了个新花样——引入了Multi-Token Prediction(多Token预测)技术来提升推理效率,同时通过扩展上下文窗口,显著强化了对长内容的整体识别能力。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
官方公布的数据相当亮眼:推理速度提升了约400%,时延降低了60%,推理峰值能达到500 tokens/s,而成本则下降了80%。在多项公开测试集上,它也交出了错误率较低的答卷。
精度方面,阶跃星辰宣称StepAudio 2.5 ASR在多个主流评测基准上达到了业内领先水平。效率上,一段约5分钟的音视频能在较短时间内完成转写,并且支持一次性完整处理最长30分钟的音频。更引人注目的是其定价策略:StepAudio 2.5 ASR的服务费用定为0.15元/小时,这仅仅是其上代产品Step ASR 2价格的十分之一。
不过,技术指标是一回事,实际表现如何?在后续的测试中我们发现,模型对不同音频输入的适应性确实存在差异:部分上传的音频文件未能成功识别,而在实时录音场景下,它的表现则相对稳定,整体转写准确度较高。
一、不同模式下语音识别效果存在差异
在官方演示的场景里,面对大段连续的口述内容,StepAudio 2.5 ASR能够实现长时间的连贯输出。识别过程中,文本还原稳定,语义保持完整,长音频的转写质量表现得相当均衡。
不仅如此,模型对复杂语境的适配能力也更强了。无论是日常高频的中英混杂表达,还是像绕口令这种发音紧凑、咬字复杂的特殊语句,它都能稳定完成精准识别与完整转写。看得出来,其抗干扰能力和语言包容性确实有了进一步提升。
▲阶跃星辰官方演示
我们也依托阶跃星辰的在线体验平台做了实测,特意选取了一段张雪峰老师的高考志愿填报课程录音作为测试素材,重点检验模型在长音频场景下的真实识别能力。
这个上传模式主要面向会议纪要整理、采访录音转写、课程内容归档等场景,支持WA V、MP3、OGG、PCM等主流格式,单文件大小不超过20MB,同时支持中文、英文及中英混合识别。
但有意思的是,在多次上传同一段音频后,系统均提示“未检测到清晰语音”,未能完成有效转写。具体原因目前尚不明确。
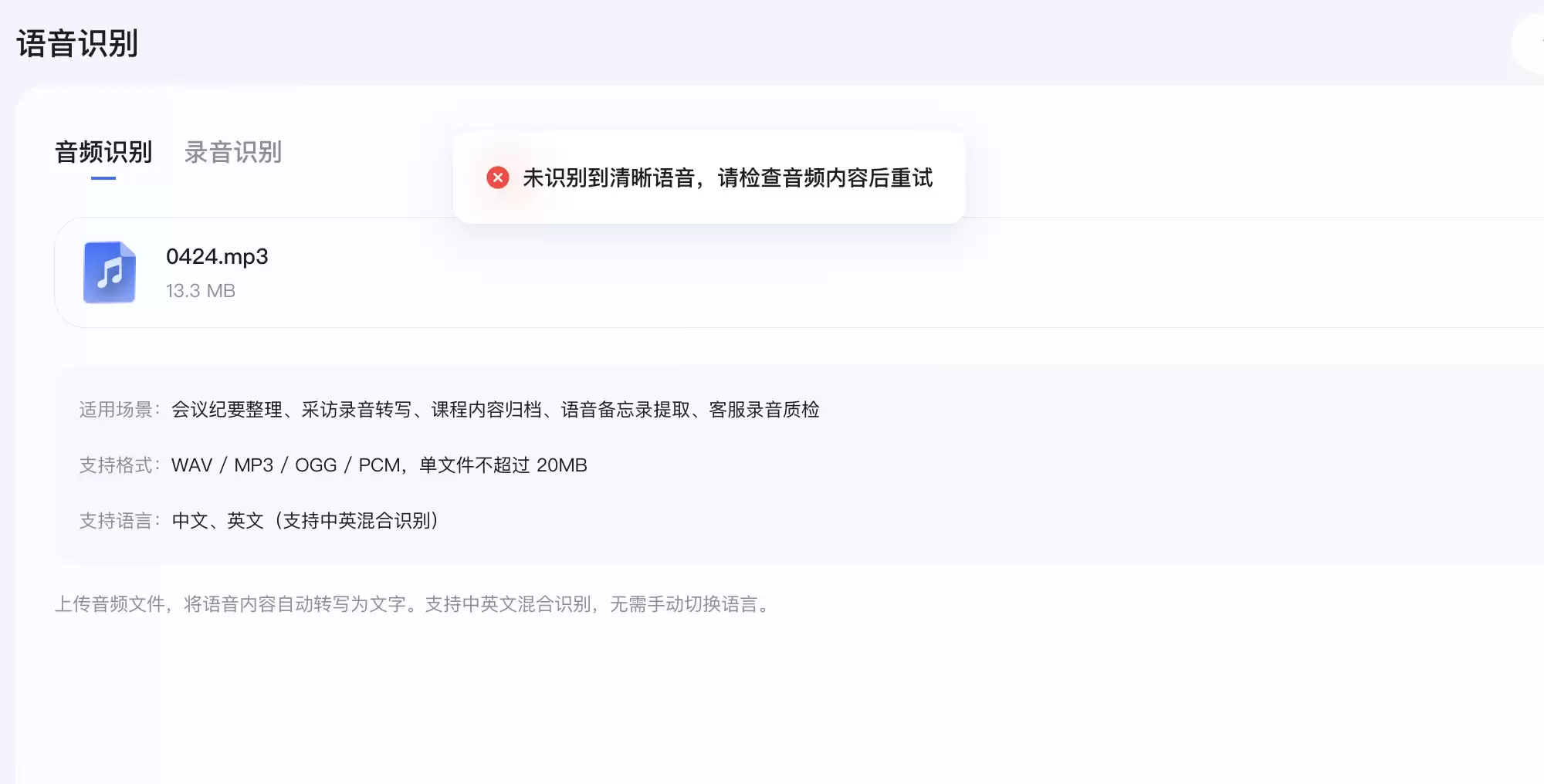
随后,我们切换到了现场录音模式进行测试。这个模式更适合快速语音备忘、现场会议记录等场景,同样支持中英文及混合识别,但单次录音时长上限为2分钟。
这次的识别结果如下:

在这个场景下,模型表现正常,整体转写结果较为准确,对口语内容的还原度很高。关注几个细节:当说话人出现较长停顿时,模型会自动插入额外的逗号进行分割;同时,算法完整保留了日常口语中自然的重复、口头复述等特征,相当真实地还原了原始的语言状态。
二、Multi-Token Prediction优化推理效率
StepAudio 2.5 ASR这次的一个核心亮点,是将Multi-Token Prediction技术引入了语音识别赛道。它沿用了Step 3.5 Flash的同款技术方案,采用Audio Encoder+Linear Adapter+LLM+MTP-5的融合架构,从根本上打破了传统串行输出的限制。
简单来说,这个模型可以单次预测多组候选Token,再结合并行验证机制快速输出识别结果,从底层架构上优化了推理效率。
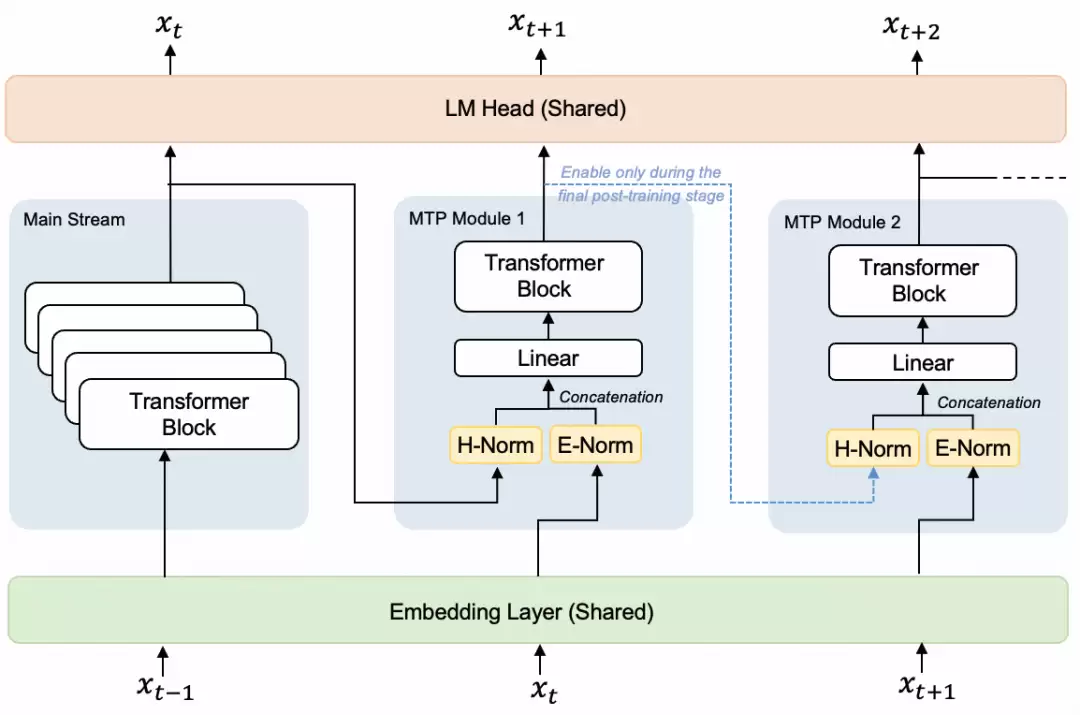
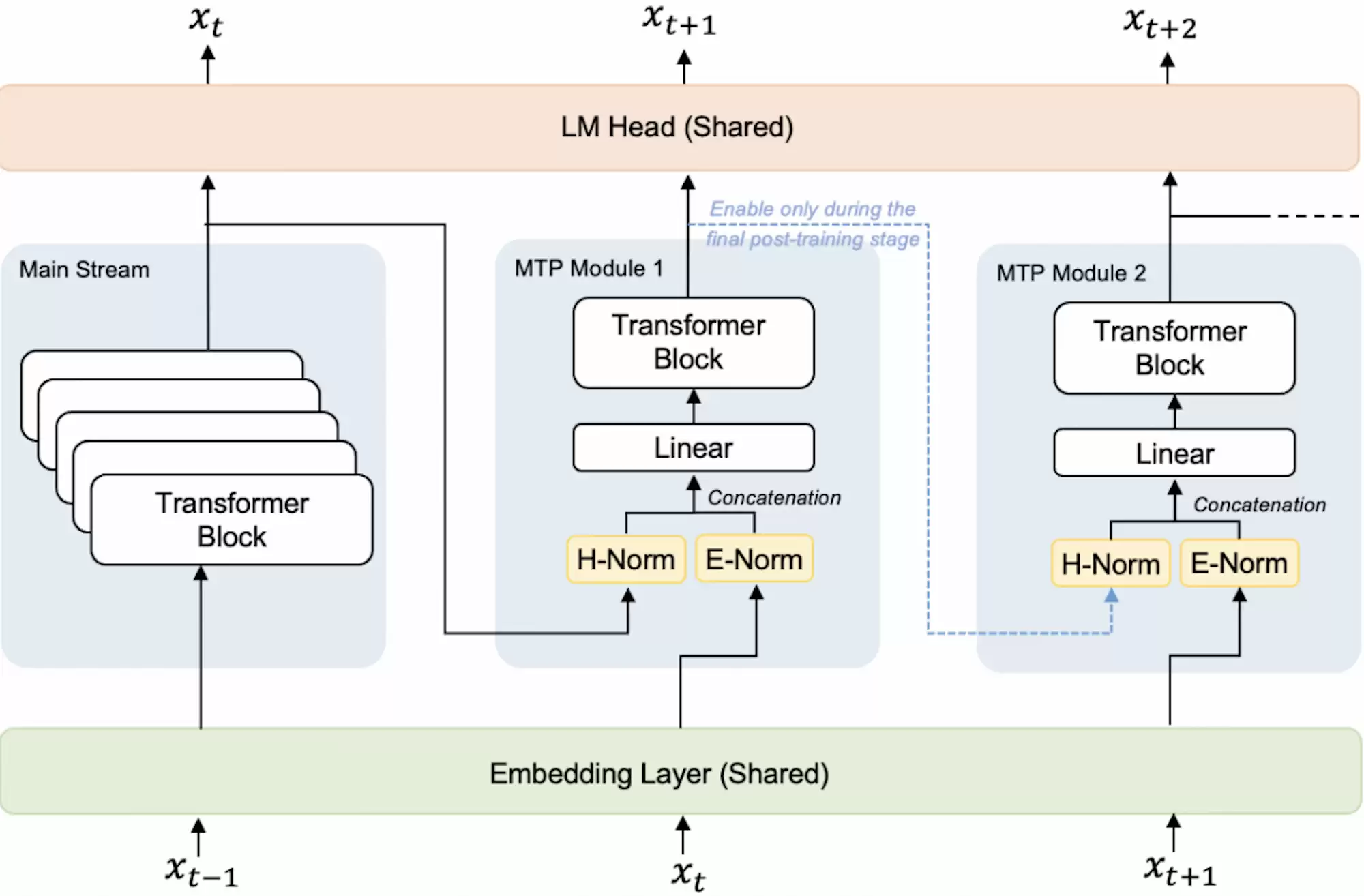
官方实测数据显示,对比传统识别方案,该模型推理速度提升400%,整体时延压缩60%,推理运行成本下降80%,峰值推理速率可达500 tokens/s。这对于提升音视频转写的实时性和性价比,意义重大。
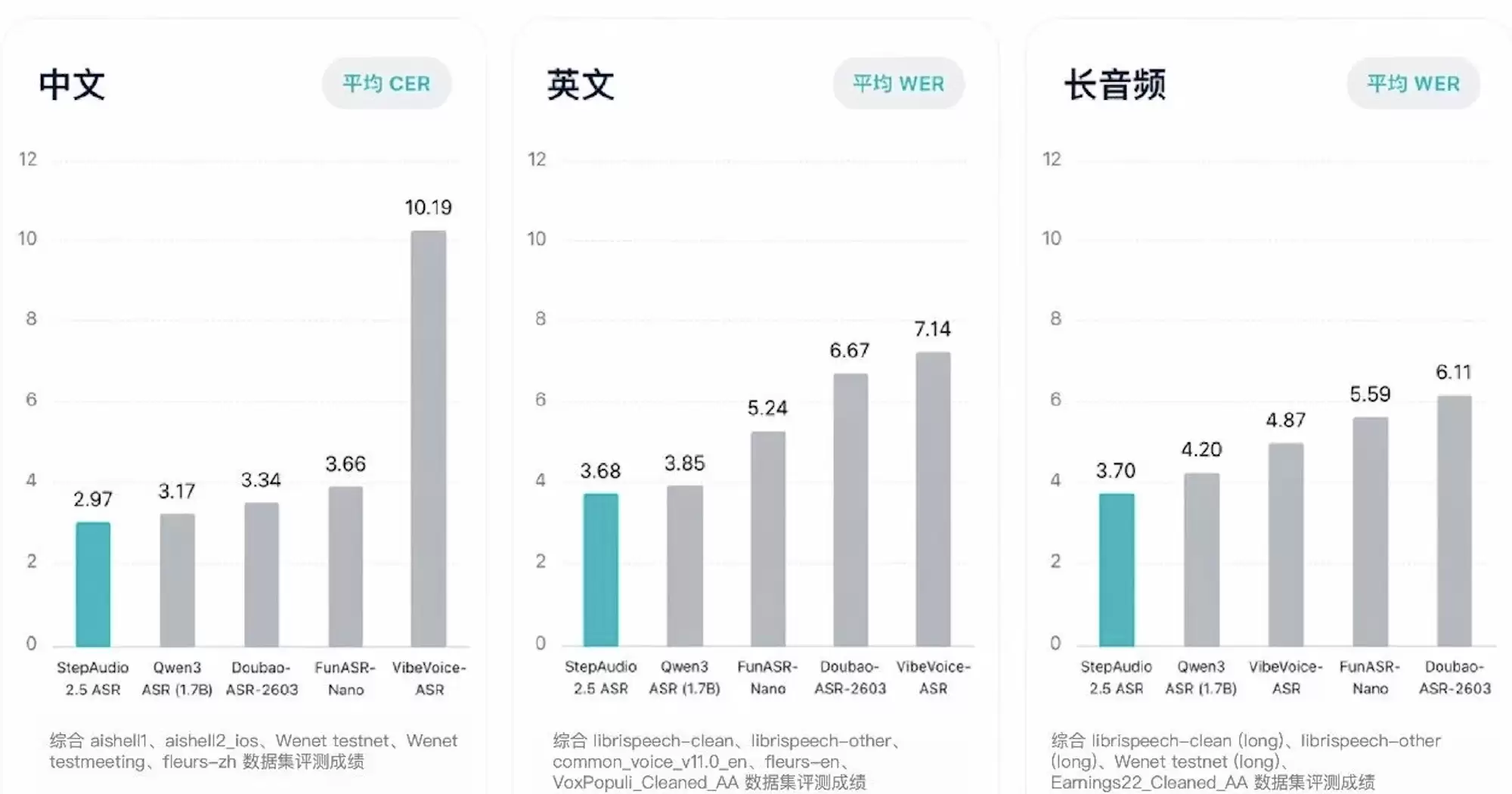
在推理效率的横向对比上,阶跃星辰官方数据显示,StepAudio 2.5 ASR的表现高于Qwen3 ASR(1.7B)、FunASR-Nano、Doubao-ASR-2603等模型。

长音频处理一直是语音识别行业的痛点。目前主流方案多采用先将音频切片、分段识别、最后再拼接的处理模式。但切割后的片段相互独立,容易造成上下文信息割裂,处理长内容时常常出现语义断层、信息遗忘等问题。
对此,StepAudio 2.5 ASR复用了LLM原生的32K上下文窗口能力,支持端到端一次性处理最长30分钟的连续音频,无需分段切割,全程保留完整的上下文关联。这很好地保障了长时段对话、会议、访谈等场景下的识别连贯性。
识别精度层面,该模型在多组权威公开数据集中表现稳定。在LibriSpeech clean/other等五组主流英文开源测试集里,其词错误率优于同期同类模型,能够以更低的算力消耗实现更高质量的转写效果。
针对30分钟满负荷长音频的专项测试显示,模型识别精度始终维持在行业顶尖水平,没有出现长文本识别中常见的精度逐级衰减问题,长时序内容识别的稳定性得到了显著提升。
结语:关键指标提升,真实场景仍是考场
整体来看,StepAudio 2.5 ASR的改进确实抓住了当前语音识别系统的关键:推理效率与长上下文建模能力。速度、成本、长度,这些硬指标上的提升有目共睹。
但话说回来,从实测情况看,模型在不同音频输入条件下的稳定性仍有提升空间。尤其是在面对复杂或非标准音频时,其适配能力如何,仍有待更多真实场景的锤炼和第三方评测的进一步验证。实验室里的高分,终究要在现实世界的考场里接受最终检验。
相关攻略

阶跃星辰发布StepAudio 2 5 ASR:推理提速400%,长音频处理迎来新突破 4月24日,阶跃星辰正式推出了新一代自动语音识别模型StepAudio 2 5 ASR。这款模型主要瞄准语音转写与长音频处理场景,在架构上玩了个新花样——引入了Multi-Token Prediction(多To

等等——高德也闯入具身智能赛道了? 一个国民级的导航应用,突然和机器人、机器狗这些“铁家伙”联系在了一起,这事儿乍一听确实让人有些意外。难道高德也开始跟风搞噱头了? 但深入了解后才发现,这并非噱头。高德不仅拿出了实打实的技术,其成果更是跻身全球第一梯队。 核心在于,高德发布了首个面向AGI的全栈具身

1月20日消息,今日,阶跃星辰宣布多模态模型 Step3-VL-10B 开源。据介绍,仅用 10B 参数量,Step3-VL-10B 在视觉感知、逻辑推理、数学竞赛以及通用对话等一系列基准测试中均达

金磊 发自 凹非寺量子位 | 公众号 QbitAI智谱华为,这个组合刚刚搞了波大的:开源新一代图像生成模型GLM-Image,是中国首个全程在国产芯片上完成训练的SOTA多模态模型!GLM-Imag

BookRAG 把“书”当书看:先还原目录树,再建实体关系图,最后让 AI 像人类翻书一样“闻味寻章”,在复杂文档问答任务上全面 SOTA。 香港中文大学最新作品论文地址:https: arxiv
热门专题







热门推荐

数字图像处理的多领域核心支撑技术:当高分辨率与复杂场景成为常态 如今,数字图像处理技术早已渗透到医学、遥感、工业乃至日常生活的方方面面,成为不可或缺的核心支撑。然而,随着图像分辨率飙升、场景复杂度加剧,传统的纯经典算法开始显得有些力不从心,效率与精度双双遭遇瓶颈。另一边,纯量子算法虽然凭借其天生的并

币安(Binance):官方安全访问与资产管理全指南 在数字资产的世界里,选择一家可靠的交易平台只是第一步,如何安全地“抵达”并管理它,才是守护资产真正的起点。作为全球领先的数字资产交易生态系统,币安为用户提供了涵盖现货、合约及理财的全方位金融服务。接下来的内容,将为你清晰地勾勒出访问币安官方网页的

摘要 眼下,企业数字化转型已进入深水区。对于预算在10万到20万区间的中高端企业而言,一个量身定制的高端官网,早已超越了“线上名片”的范畴。它更像是品牌数字资产的基石,既是塑造专业壁垒的阵地,也是全域流量的汇聚点和商业转化的核心枢纽。一个明显的趋势是:手握充足预算的企业决策者们——无论是创始人、总经

无聊的寒假作文600字一 光阴似箭,日月如梭。这话说得一点不假,五年级的学习生活转眼就溜之大吉了,可迎接我的,却是一个看似枯燥无味的暑假。 唉,当时我躺在床上翘着二郎腿,心里只剩下叹息。脑子里反复琢磨:在家呆着,既不能和朝夕相处的同学们一块儿玩耍,也看不到他们灿烂的笑容,更听不到那些欢快爽朗的笑声了

广交会火热开展,AI硬件与私有存储成焦点 这届广交会,风向很明确:AI硬件、智能设备、数字化解决方案,无疑是全场最核心的焦点。一个清晰的趋势正在浮现——随着数字化转型进入深水区,越来越多的中小企业开始重新审视自己的数据策略。他们逐渐意识到,过度依赖云端存储存在诸多掣肘。于是,数据本地存储、隐私自主可