MySQL函数索引:解决“索引列被函数操作后失效”的利器
你是否遇到过这样的场景:明明给字段建了索引,可查询时只要加个简单的函数操作——比如用DATE(create_time)提取日期,或者用UPPER(name)转换大小写——执行速度就瞬间变慢?用EXPLAIN一看,key字段显示为NULL,索引直接失效,查询被迫走向全表扫描。
来看一个典型的例子,create_time字段明明有索引,但下面这条SQL却慢得离谱:
-- 索引失效,全表扫描
SELECT * FROM orders WHERE DATE(create_time) = '2026-03-13';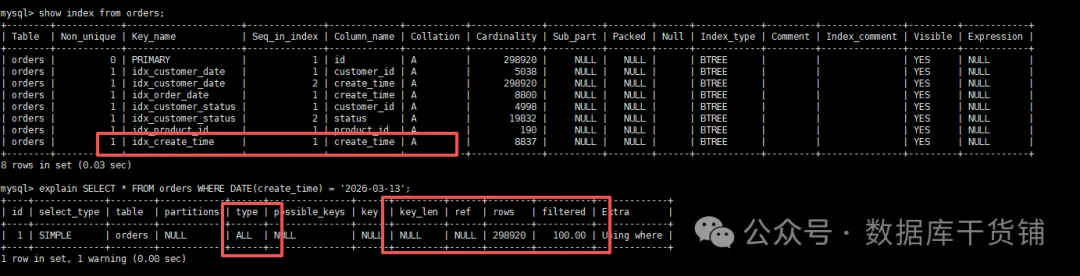
问题的根源其实很清晰:MySQL的普通索引是针对字段的原始值建立的。一旦在查询条件中对字段施加了函数操作,优化器就无法直接利用索引的有序性,只能退而求其次进行全表扫描。而解决这个痛点的关键,正是今天要深入探讨的MySQL函数索引。它并非什么高深莫测的新特性,却能直击要害,尤其在MySQL 8.0之后,其用法变得更加简洁,适用场景也更为广泛。
一、什么是MySQL函数索引
首先需要明确一个核心前提:普通索引是对“字段本身”建立索引。例如,给create_time字段建索引,MySQL会直接对字段里的原始日期值进行排序并构建B+树结构,查询时能快速定位。
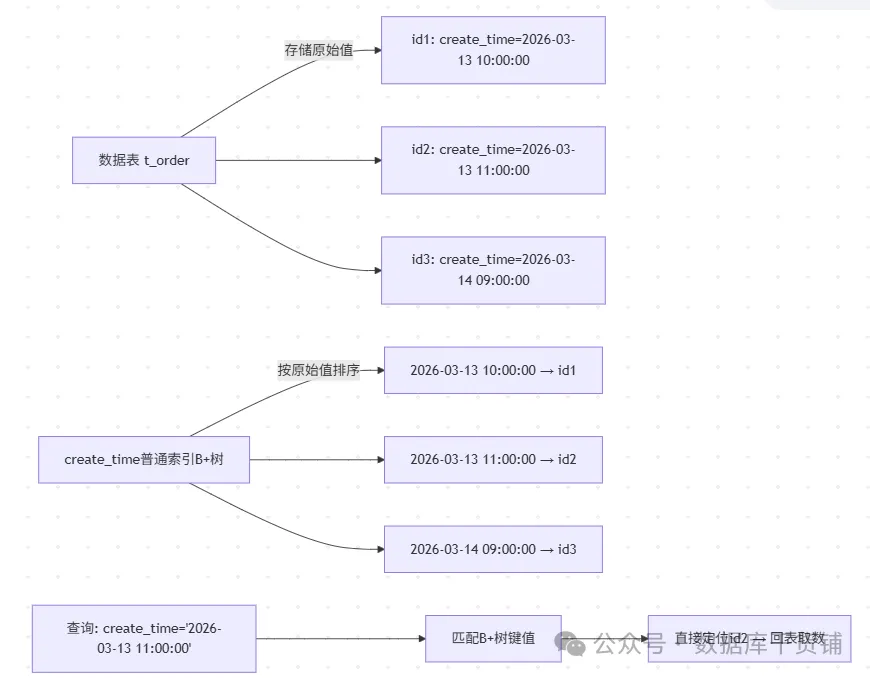
然而,当查询条件变为DATE(create_time)或LOWER(name)时,情况就不同了。函数操作改变了字段的原始形态,破坏了B+树基于原始值的有序性,优化器自然无法直接使用索引,全表扫描便成了无奈之选。
那么,函数索引(Functional Index)是如何破局的呢?简单来说,它是针对“函数处理后的结果”建立的索引。MySQL会预先计算“字段+函数”的结果,并将其存储为一个隐藏的虚拟列,然后对这个虚拟列建立索引。当查询命中时,直接匹配预先计算好的结果,省去了实时计算的成本,索引自然就能生效。
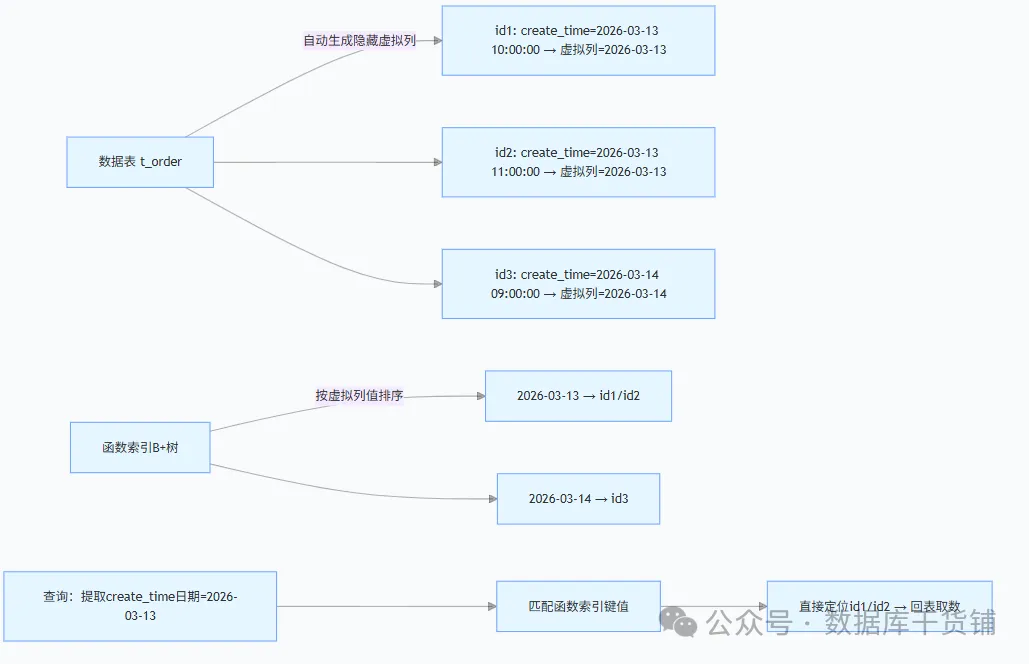
不妨用一个通俗的比喻来理解:普通索引是“给整个苹果贴标签”,而函数索引则是“先把苹果切成块,再给每一块贴标签”。查询时直接寻找对应切块的标签,效率自然更高。
这里有一个关键版本限制需要留意:MySQL从8.0.13版本开始,才正式支持直接创建函数索引。在此之前的版本,需要通过“创建虚拟列+在虚拟列上建普通索引”的方式来模拟实现,步骤相对繁琐。
二、函数索引的创建及使用
函数索引的核心用法并不复杂。下面结合三个高频场景,带你快速上手实操。
1. 基础语法(MySQL 8.0.13+)
创建函数索引的语法与普通索引类似,核心区别在于:函数表达式必须用双括号包裹,这是为了避免与普通列索引产生混淆。具体语法如下:
-- 通用语法
CREATE [UNIQUE] INDEX 索引名 ON 表名 ((函数(字段名)));
-- 示例:给create_time的DATE()结果建索引
CREATE INDEX idx_date_create_time ON orders ((DATE(create_time)));
-- 示例:给name的小写转换结果建唯一索引
CREATE UNIQUE INDEX idx_lower_name ON users ((LOWER(name)));请注意,双括号是必须项!如果少写一层括号,MySQL会将其识别为给普通列建索引,从而导致报错或创建失败。
2. 高频使用场景
函数索引的核心价值,就在于精准解决“因函数操作导致索引失效”的典型场景。以下三种情况最为常见。
(1) 场景1:日期字段的函数查询
需求:查询某一天的所有订单,通常使用DATE(create_time) = ‘日期’的写法,此时普通索引失效,创建对应的函数索引即可解决。
-- 1.无函数索引时全表扫描
mysql> explain SELECT * FROM orders WHERE DATE(create_time) = '2026-03-13';
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1| SIMPLE | orders |NULL |ALL|NULL |NULL|NULL |NULL|298920| 100.00|Usingwhere |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
-- 2.创建函数索引(针对DATE(create_time)
mysql> CREATE INDEX idx_date_create_time ON orders ((DATE(create_time)));
Query OK, 0 rows affected (2.67 sec)
Records: 0 Duplicates: 0 Warnings: 0
-- 3. 查询(直接命中索引)
mysql> explain SELECT * FROM orders WHERE DATE(create_time) = '2026-03-13';
+----+-------------+--------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | orders | NULL | ref | idx_date_create_time | idx_date_create_time | 4 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+----------------------+----------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)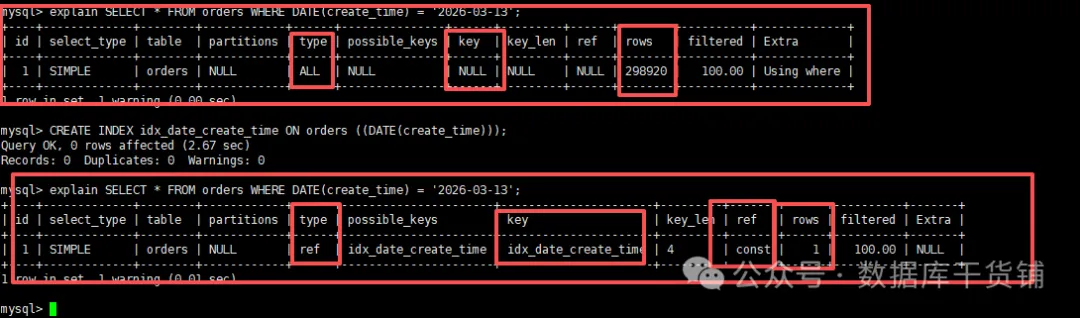
通过EXPLAIN验证:key字段显示为idx_date_create_time,且type字段为ref,这明确表示索引已生效,成功避免了全表扫描。
(2) 场景2:字符串字段的大小写不敏感查询
需求:查询用户名时忽略大小写(例如,将“ZhangSan”和“zhangsan”视为同一用户),常用LOWER(name) = ‘zhangsan’,此时普通索引失效。
-- 1. 创建函数索引(针对LOWER(name))
CREATE INDEX idx_lower_name ON users ((LOWER(name)));
-- 2. 查询(命中索引,忽略大小写)
SELECT * FROM users WHERE LOWER(name) = 'zhangsan';补充一点:如果业务上需要施加唯一性约束(例如,不允许重复的用户名,且忽略大小写),可以创建唯一函数索引,从而从数据库层面杜绝重复数据。
(3) 场景3:字符串截取查询
需求:查询手机号前3位为‘138’的用户,常用SUBSTRING(phone, 1, 3) = ‘138’,普通索引同样会失效,创建函数索引即可解决。
-- 1. 创建函数索引(针对SUBSTRING(phone, 1, 3))
CREATE INDEX idx_substr_phone ON users ((SUBSTRING(phone, 1, 3)));
-- 2. 查询(命中索引)
SELECT * FROM users WHERE SUBSTRING(phone, 1, 3) = '138';3. 旧版本兼容方案(MySQL 8.0之前)
如果你的MySQL版本低于8.0.13,无法直接创建函数索引,可以通过“虚拟列+普通索引”的组合来模拟实现。具体步骤如下:
-- 1. 给表添加虚拟列(存储函数计算结果)
ALTER TABLE orders ADD COLUMN date_create_time DATE GENERATED ALWAYS AS (DATE(create_time)) STORED;
-- 2. 给虚拟列建普通索引
CREATE INDEX idx_date_create_time ON orders (date_create_time);
-- 3. 查询(直接用虚拟列查询,命中索引)
SELECT * FROM orders WHERE date_create_time = '2026-03-13';关于虚拟列的更多细节,可以参考之前的文章《一文搞懂MySQL虚拟列用法、选型与避坑》。
需要特别注意:虚拟列的表达式必须与查询时使用的函数表达式完全一致,否则索引无法命中。此外,使用STORED关键字意味着虚拟列的值会被持久化存储,虽然会占用少量存储空间,但查询性能更优。
三、关键避坑:这五个错误千万别犯!
函数索引虽好,但若使用不当,不仅无法优化查询,反而会浪费存储空间、拖慢数据写入速度。下面这五个常见的“坑”,务必小心避开。
1. 坑一:函数不匹配,索引白创建
函数索引遵循“一对一”的严格匹配原则。创建时使用了什么函数,查询时就必须使用完全相同的函数,否则索引无法命中。
-- 错误示例:创建的是LOWER(name)索引,查询用UPPER(name)
CREATE INDEX idx_lower_name ON users ((LOWER(name)));
SELECT * FROM users WHERE UPPER(name) = 'ZHANGSAN'; -- 索引失效
-- 正确示例:函数完全匹配
SELECT * FROM users WHERE LOWER(name) = 'zhangsan'; -- 命中索引2. 坑二:用了非确定性函数,无法创建索引
函数索引仅支持确定性函数,即对于相同的输入,必须保证得到相同的输出。像NOW()(获取当前时间)、RAND()(生成随机数)这类非确定性函数,是无法用于创建函数索引的,系统会直接报错。
-- 错误示例:用NOW()创建函数索引,报错
mysql> CREATE INDEX idx_now ON orders ((NOW()));
ERROR 3758 (HY000): Expression of functional index 'idx_now' contains a disallowed function.
3. 坑三:过度使用,拖慢写入速度
函数索引与普通索引一样,需要占用额外的存储空间。更重要的是,每次执行INSERT或UPDATE操作时,MySQL都需要重新计算函数结果并更新索引。因此,索引建得越多,数据写入的速度就会越慢。
最佳实践是:只为那些高频出现的函数查询创建函数索引。对于低频查询,完全可以考虑通过改写SQL来避免使用函数,而不是盲目创建索引。例如,对于DATE(create_time)=‘2026-03-13’的查询,如果create_time字段本身有索引,将其改写为create_time >= ‘2026-03-13’ AND create_time < ‘2026-03-14’,往往是一种更灵活高效的解决方案。
4. 坑四:忽略数据量,小表用了反而更慢
如果表的数据量非常小(例如不足1000行),MySQL优化器经过成本估算后,可能会认为“全表扫描”比“走索引回表”更快。因此,即使创建了函数索引,也可能不会被使用。
建议:对于小表,无需创建函数索引。只有当表数据量较大(达到万级或以上)、且确实存在频繁的函数查询时,才值得考虑使用。
5. 坑五:混淆“函数索引”和“前缀索引”
这是两个容易混淆的概念。前缀索引是对“字段值的前N个字符”建立索引(例如name(10)),主要用于长字符串字段,目的是节省索引存储空间。而函数索引是对“函数计算结果”建立索引,两者适用场景截然不同。
举例来说,对于bio(个人简介)这类长文本字段,如果需要根据首字母进行查询,适合使用函数索引;如果只是根据前10个字符进行精确匹配,那么前缀索引可能是更高效的选择。
四、总结
最后,用三句话概括函数索引的核心要点,方便大家快速掌握并应用于实践:
核心作用:精准解决“索引列被函数操作后失效”的问题。其本质是对函数计算结果建立索引,通过预先计算来提升查询效率。
适用场景:日期函数查询、字符串大小写匹配、字符串截取等高频函数操作场景,且适用于数据量较大的表(万行以上)。
最佳实践:秉持“少而精”的原则,只为高频查询创建;确保创建与查询时的函数完全匹配;避免使用非确定性函数;并始终在写入性能与查询性能之间做好权衡。
说到底,MySQL索引优化的核心哲学,从来不是“越多越好”,而在于“精准匹配业务场景”。函数索引看似简单,但若能恰到好处地运用,足以解决许多开发中的实际性能痛点,尤其在报表生成、数据分析等复杂查询场景下,能带来显著的效率提升。




