SQL Server 列转行创新方法:独家利用 SysColumns 系统表实现
在 SQL Server 数据转换中,列转行操作常常让开发者感到棘手。本文分享一种高效且独特的实现思路,该方法巧妙运用了系统表 SysColumns,经过笔者实践验证,在常规方案之外提供了一种新颖的解决方案。下面我们将从基础的行转列讲起,逐步深入至核心的列转行技巧。
(一)SQL Server 行转列标准实现方法
行转列(PIVOT)是数据处理中的常见需求,其核心目标是将行数据中的特定值转换为结果集中的多个列。标准方法是结合动态 SQL 与 CASE WHEN 条件判断来实现。
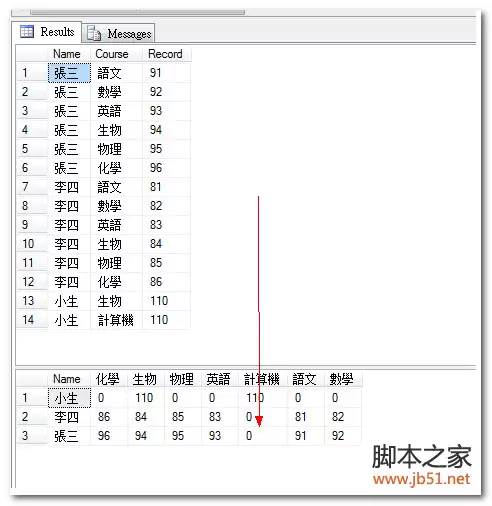
首先,我们通过一个直观的效果图来明确转换目标:
第一步:创建测试数据表
我们首先建立一个学生成绩表,用于后续的演示:
复制代码
代码如下: CREATE TABLE RowTest( [Name] [nvarchar](10) NULL,--學生姓名 [Course] [nvarchar](10) NULL,--課程科目 [Record] [int] NULL--考試分數 )
第二步:插入模拟数据
向表中添加结构化的测试数据,以便清晰展示转换过程:
复制代码
代码如下:
insert into RowTest values ('张三','语文','91')
insert into RowTest values ('张三','数学','92')
insert into RowTest values ('张三','英语','93')
insert into RowTest values ('张三','生物','94')
insert into RowTest values ('张三','物理','95')
insert into RowTest values ('张三','化学','96')
insert into RowTest values ('李四','语文','81')
insert into RowTest values ('李四','数学','82')
insert into RowTest values ('李四','英语','83')
insert into RowTest values ('李四','生物','84')
insert into RowTest values ('李四','物理','85')
insert into RowTest values ('李四','化学','86')
insert into RowTest values ('小生','语文','71')
insert into RowTest values ('小生','数学','72')
insert into RowTest values ('小生','英语','73')
insert into RowTest values ('小生','生物','74')
insert into RowTest values ('小生','物理','75')
insert into RowTest values ('小生','化学','76')
第三步:实现原理深度解析
行转列的本质是将“课程”字段中的不同取值动态地映射为结果集的列标题。技术实现上,通过 CASE WHEN 语句将对应课程的分数值填充到新生成的列中,最后使用 GROUP BY 按学生姓名进行聚合,实现一行显示所有成绩。
第四步:编写通用动态 SQL 脚本
为了适应课程科目可能动态变化的情况,采用动态 SQL 是更通用的解决方案:
复制代码
代码如下: declare @sql nvarchar(max) set @sql='select Name' select @sql=@sql+','+'isnull(max( case when Course='''+TCourse.Course+''' then Record end ),0) as ['+TCourse.Course+']' from (select distinct Course from RowTest)TCourse set @sql=@sql+' from RowTest group by Name order by Name' print @sql exec(@sql)
关键技术点说明:
此脚本首先获取所有不重复的课程名称,构成一个临时集合(TCourse)。随后通过字符串拼接循环,为每一门课程生成对应的 CASE WHEN 条件列,最终组装成完整的、可执行的查询语句,完美实现动态行转列。
第五步:扩展场景与边界测试
1. 处理重复数据: 假设为“小生”额外添加一条生物课成绩:
复制代码
代码如下:
insert into dbo.RowTest values ('小生','生物','110')
此时,若动态 SQL 中省略 MAX() 聚合函数,执行将会报错。原因在于同一学生同一课程出现多行记录时,必须通过聚合函数来确定最终显示哪一个数值。
2. 测试动态扩展性: 新增一门“计算机”课程数据:
复制代码
代码如下:
insert into dbo.RowTest values ('小生','計算機','110')
再次执行之前的动态 SQL,会发现结果集中自动增加了“计算机”列。对于未选修该课程的学生,其对应列值显示为 0。这充分证明了该方法的灵活性与可扩展性。
至此,SQL Server 行转列的通用实现方法已完整阐述。
(二)SQL Server 列转行独家创新方案
接下来重点探讨更具挑战性的列转行(UNPIVOT)操作。传统方法依赖多个 UNION ALL 语句,代码冗长且不易维护。笔者提出一种基于系统表的新思路,更为简洁高效。
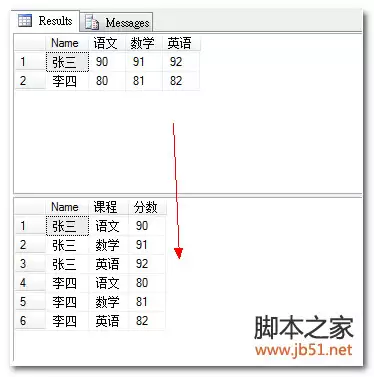
列转行的目标效果如下图所示:
第一步:创新思路揭秘
常见方案需要为每一列手动编写 UNION ALL 子句,列数增加时代码量同步增长。本文的创新方法核心在于:首先,动态获取目标表除主键(或姓名列)外的所有列名,这通过查询系统表 SysColumns 实现。然后,将原表与这个“列名结果集”进行关联,从而将一行数据“展开”成多行(每行对应一个列名)。最后,通过条件判断动态获取原表对应列的值。
第二步:构建列式存储测试表
创建一个典型的宽表结构,各科目成绩以独立列的形式存储:
复制代码
代码如下: create table CoulumTest ( Name nvarchar(10), 语文 int, 数学 int, 英语 int )
第三步:准备测试数据
向表中插入示例数据:
复制代码
代码如下: insert into CoulumTest values(N'张三',90,91,92) insert into CoulumTest values(N'李四',80,81,82)
第四步:核心实现代码解析
关键实现仅需一条查询语句,极大简化了操作:
复制代码
代码如下:
select CT.Name, Col.name as 课程,
(case when Col.name=N'语文' then CT.语文
when Col.name=N'数学' then CT.数学
when Col.name=N'英语' then CT.英语
end ) as 分数
from CoulumTest CT
left join (select name from SysColumns Where id=Object_Id('CoulumTest')) Col on Col.name <> 'Name'
这条语句的精妙之处在于:通过左连接系统表 SysColumns,获取当前表的所有列名,并过滤掉非转换列(如‘Name’)。然后,利用 CASE WHEN 语句,根据匹配到的列名,从原表对应列中取出数值。
当然,此方法仍有优化空间:目前的 CASE WHEN 需要显式列出每个列名。是否存在一种更通用的方式,能够直接根据 Col.name 动态引用 CT 表中的列,而无需硬编码条件分支?这作为一个开放性问题,留给读者进一步思考和探索,也欢迎更多数据库高手分享更优解。




