Claude强到不敢发的Mythos,被质疑用了字节Seed技术
Claude最强“神话”模型,可能用到来自字节的技术?
这条猜测直接冲上了热搜榜。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
这款被形容为“强到不敢公开发布”的Mythos模型,确实极大地刺激了人们对下一代大语言模型架构的想象空间。
社区讨论的焦点,正集中在它是否采用了“循环语言模型”(Looped Language Model)这一创新架构上。这个概念,恰恰源自字节跳动Seed团队与多所高校合作发表的一篇学术论文,连AI领域的泰斗Yoshua Bengio也参与了其中。

关键的线索,就藏在Anthropic官方公布的一组测试数据里。
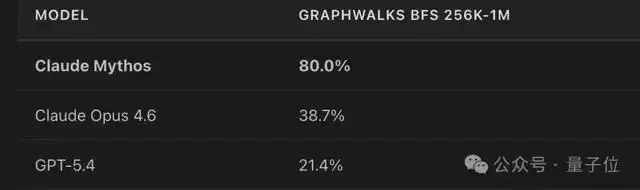
字节的论文明确指出,图搜索是循环算法相比标准RLVR(强化学习与值响应)具有巨大理论优势的领域之一。回过头来看Mythos,它正是在“广度搜索优先的图搜索测试”(GraphWalks BFS)这项任务中,表现出了对竞争对手GPT-5.4的碾压性优势。
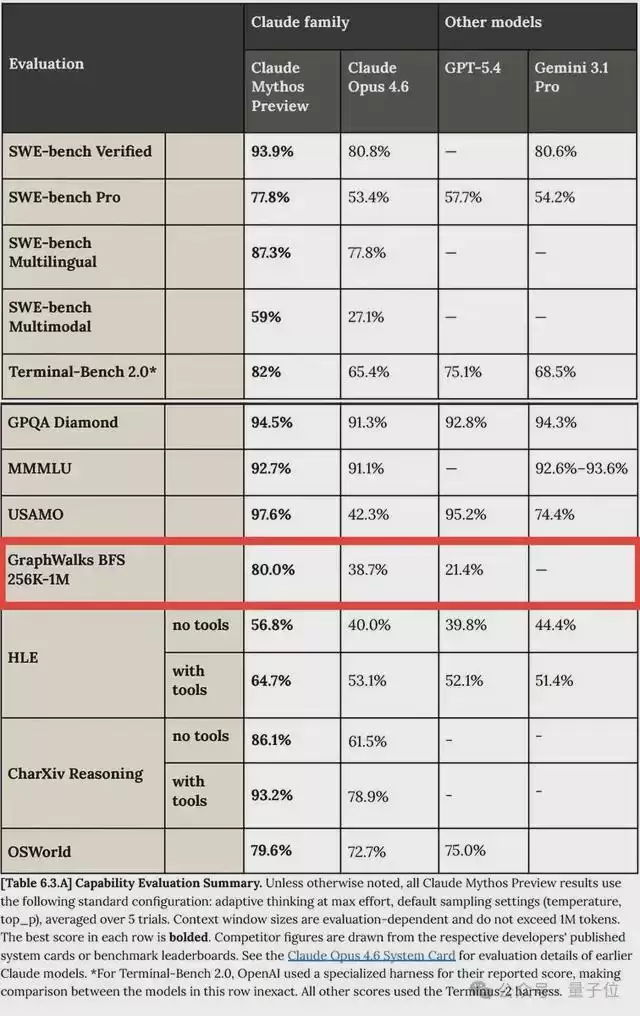
80%对21.4%,接近四倍的差距。值得注意的是,在其他类型的任务上,并没有出现如此异常的巨大分差。这似乎暗示,Mythos的这种进步很可能并非源于通用的“规模扩展法则”(Scaling Law),而是来自某种底层的架构创新。
循环语言模型:同一层“多转几圈”,小模型也能碾压大模型
GraphWalks BFS测试,本质上是给模型一个复杂的图结构,要求它执行广度优先搜索——从起点出发,一层一层地访问所有相邻节点。
标准的Transformer模型处理这类问题时,只能进行一次前向传播,从头走到尾,输出结果,其内部并没有“迭代”这个概念。而Mythos能在图遍历任务上拿到80%的高分,表明它的内部很可能在进行“反复计算”,对同一组信息来回处理了多遍。
那么,什么样的架构能够实现这种“反复计算”呢?
字节Seed团队在论文中提出的LoopLM(循环语言模型)提供了一个可能的答案。
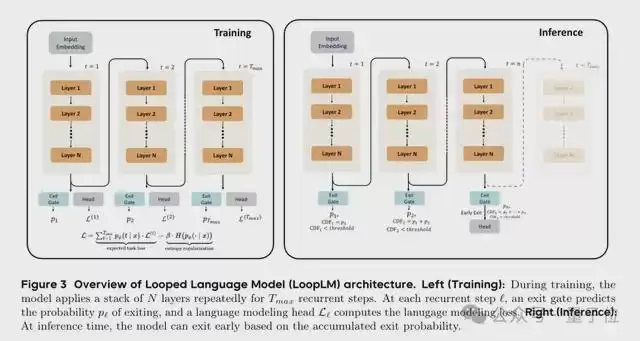
简单来说,LoopLM架构有三个核心特点:
第一,它不依赖生成冗长的“思维链”文本来进行思考,而是在模型的内部潜空间进行迭代,不会额外输出更多的token。
第二,它能根据问题难度自动调节“思考”步数:简单题少想几步,难题则多想几步。
第三,也是最重要的一点,它在预训练阶段学习的就不仅仅是“如何预测下一个token”,而是“如何在潜空间里进行思考”。
在实验中,研究团队训练了名为Ouro的系列循环语言模型,这些模型内置了循环思考机制。
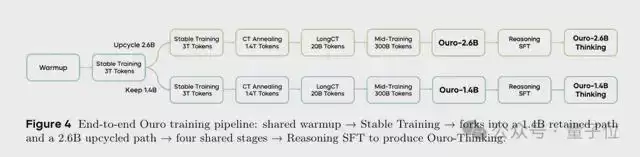
测试结果令人印象深刻:1.4B参数的Ouro模型,其性能可以对标约4B参数的传统模型。而2.8B参数的Ouro模型,能力则相当于8B到12B参数的传统模型。
循环模型的能力提升究竟从何而来?论文进一步分析了“知识存储”与“知识操作”的区别。
“知识存储”的容量本质上是有限的,大约每个参数2比特,无论采用什么架构,这个数字基本不变。循环机制本身并不会让模型“记住”更多的事实性知识。
但“知识操作”就完全不同了。将已知的事实组合起来进行多跳推理、执行程序、搜索图结构——这类能力会随着循环步数和训练数据量的增加而呈指数级增长。
换句话说,循环模型并没有给AI一个更大的静态知识库,但它让AI在现有知识库内部进行搜索、组合和推理的能力,提升了一个数量级。
三条线索指向循环模型架构
那么,Mythos究竟是不是采用了循环模型架构呢?除了GraphWalks测试这个最明显的迹象,社区还总结出了另外几条线索。

第一条线索,即前面详细讨论的广度优先图搜索测试结果。Mythos在该项上的分数不仅是GPT-5.4的四倍,相比其前代模型Opus-4.6的提升幅度也异常巨大。
第二条线索,涉及效率与速度的矛盾。Anthropic的报告指出,Mythos完成每个任务所使用的token数量仅为Opus-4.6的五分之一,但它的响应速度反而更慢(价格也贵了五倍!)。
这在标准Transformer的框架下很难解释:生成的token少,意味着解码步骤少,按理说应该更快才对。然而,循环模型恰好能解释这个矛盾:大量的推理计算并非发生在token生成层面,而是发生在内部的潜空间迭代中,计算量消耗在了“看不见的地方”。
第三条线索,是Mythos在网络安全领域的突出表现。在CyberGym测试中,Mythos拿到了83.1%的分数,而Opus-4.6为66.6%,领先了近17个百分点。此外,Mythos还被发现能找出上千个零日漏洞,主流操作系统和浏览器几乎无一幸免。
漏洞发现的本质,其实就是对程序的控制流图进行遍历,找到一条从用户输入点到危险函数的执行路径——这又是一个图的可达性问题。看,又回到了图遍历,而这恰恰是循环架构天生的强项。
当然,说了这么多,目前终归只是业界的分析和猜测。Anthropic官方没有公开任何关于Mythos底层架构的信息,并且很可能未来也不会公开。
但有一句话值得深思:Scaling Law(规模扩展法则)带来的改善是全面而均匀的,而架构创新则会在与其“归纳偏置”高度匹配的特定任务上,创造出异常尖锐的性能峰值。

循环Transformer的归纳偏置,正是迭代图算法。而Mythos表现出的那个异常尖峰,恰好就出现在图遍历任务上。
或许,Anthropic什么也没说,但测试数据已经替它说明了一切。
字节论文:
https://arxiv.org/abs/2510.25741
参考链接:
[1] https://x.com/ChrisHayduk/status/2042711699413926262
[2] https://aiia.ro/blog/claude-mythos-looped-language-model-theory
相关攻略

Discord接入:让OpenClaw成为你的社区智能管家 对于全球数亿的游戏玩家和社群爱好者来说,Discord几乎等同于线上“大本营”。那么,有没有可能让你精心搭建的Discord服务器也拥有一个聪明能干的AI助手呢?答案是完全可行。通过创建Discord Bot(机器人),你可以将OpenCl

Claude最强“神话”模型,可能用到来自字节的技术? 这条猜测直接冲上了热搜榜。 这款被形容为“强到不敢公开发布”的Mythos模型,确实极大地刺激了人们对下一代大语言模型架构的想象空间。 社区讨论的焦点,正集中在它是否采用了“循环语言模型”(Looped Language Model)这一创新架

国产大模型DeepSeek迎来重大更新:快速模式与专家模式上线 最新消息显示,国产AI大模型DeepSeek再次迎来重要升级。4月8日,用户在访问DeepSeek时发现,输入框上方新增了“快速模式”与“专家模式”两个选项。根据官方说明,快速模式专注于日常对话场景,响应速度快,同时支持图片和文件中的文
飞书接入指南:为你的团队嵌入一位AI同事 如果你身处国内互联网或科技行业,对飞书这款高效协作平台一定非常熟悉。如今,它已不仅是团队沟通工具,更成为众多企业的数字化工作中枢。那么,能否让团队成员在飞书内部,直接调用强大的AI智能助手来提升效率呢?答案是肯定的。本指南将手把手教你,如何将OpenClaw

面对复杂连续任务的长程规划,现有的生成式离线强化学习方法往往会暴露短板。它们生成的轨迹经常陷入局部合理但全局偏航的窘境。它们太关注眼前的每一步,却忘了最终的目的地。针对这一痛点,厦门大学和香港科技大
热门专题







热门推荐
![[标准版]深圳经济特区商品房预售合同书](https://static.youleyou.com//uploadfile/2026/0505/b9e1ed518d4db17ef4131ecaff8d7804.webp)
《[标准版]深圳经济特区商品房预售合同书》 本文发表于2026年04月13日,欢迎访问本站的合同范本频道(https: www liuxue86 com hetongfanben )。本站为您准备了大量实用的合同范本,例如您可能感兴趣的商品房买卖合同书、深圳经济特区相关内容,以及深圳经济特区30周

第1部分 合同背景 在正式进入细节之前,咱们不妨先聊聊这份合同本身。它可不只是一叠纸,而是你未来数年甚至数十年安居乐业的基石。理解它的框架和背景,是走好每一步的前提。 第2部分 房屋质量 房子结不结实,这是头等大事。这部分条款就是给你的房子做一次“全面体检”,从地基到屋顶,从主体结构到隐蔽工程,每一

合同的内容与条款解析 合同,这个看似简单的法律文书,其内涵却因具体情境而异。简单来说,它可以从两个层面来理解:作为一份法律文件,合同的内容就是那一系列白纸黑字的条款,它们像游戏规则一样,明确了各方的权利、义务和责任;而作为一种法律关系,合同的内容则直接体现为当事人所享有的债权和所需承担的债务。这两者

最新关于出租房屋合同范本 话说回来,一份清晰、规范的合同,是保障租赁双方权益的基石。今天,我们就来详细拆解一份标准的房屋租赁合同范本,看看其中有哪些关键条款需要你我共同关注。 首先,合同的订立双方必须明确: 出租方:____________(个人或单位),以下简称甲方; 承租方:__________

签订合同这事儿,本质上是为了给交易上一道“公平锁”。无论哪一方在合作中遇到波折,只要白纸黑字签了约,双方就都有了清晰的行为准则和法律依据。这不仅能让交易过程更顺畅,往往也是达成圆满合作的关键一步。下面为大家梳理了两份实用的合同范本,供各位在需要时参考查阅。更多相关信息,欢迎关注留学网合同范本频道:w