国产大模型DeepSeek迎来重大更新:快速模式与专家模式上线
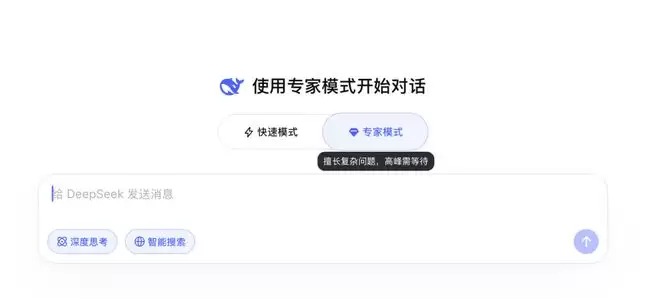
最新消息显示,国产AI大模型DeepSeek再次迎来重要升级。4月8日,用户在访问DeepSeek时发现,输入框上方新增了“快速模式”与“专家模式”两个选项。根据官方说明,快速模式专注于日常对话场景,响应速度快,同时支持图片和文件中的文字识别功能;而专家模式则专门设计用于处理复杂问题与专业任务。这是DeepSeek首次在正式页面中向公众明确提供这种分层服务模式,标志着其产品化进程进入新阶段。
这一重要更新进一步提升了业界对DeepSeek V4版本的期待。综合多家外媒报道与社区讨论分析,几乎可以确定DeepSeek极有可能在今年4月正式推出V4大模型,这将是国产大模型发展的又一里程碑。
服务异常背后的版本更新信号
实际上,此前的一些迹象已经预示了这次更新。回顾3月29日至31日,DeepSeek的服务连续三天出现不同程度的异常,波及网页对话、移动应用及API接口。三次故障分别持续了约1小时48分、10小时13分和1小时3分。最严重的一次发生在29日夜间10点,一直持续到次日早上7点,出现了长达8小时的大规模访问异常,许多用户遭遇了页面卡顿、反复提示“服务器繁忙”,甚至服务完全中断的情况。
行业观察者普遍将这次大规模服务异常与V4版本的更新部署联系起来。对于这种推测,DeepSeek内部人士并未直接证实,而是向媒体给出了意味深长的回应:“非常期待。”这一简短回应进一步加深了市场对即将发布新版本的预期。
技术论文与长文本能力测试早有铺垫
DeepSeek在技术层面的准备其实早已开始。今年1月12日,DeepSeek与北京大学合作发表了一篇题为《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》的学术论文,公司创始人梁文锋的名字位列作者之中。这篇论文的核心内容直指当前大语言模型普遍存在的“记忆力”短板,并提出了一套名为“条件记忆”的创新解决方案。
紧接着在2月13日,有消息透露DeepSeek的网页和App端正在内测全新的长文本模型结构,上下文支持能力高达1M(约100万字)。不过,当时的API服务仍维持在V3.2版本,仅支持128K上下文。这一动作曾让市场猜测,DeepSeek或许会复刻去年春节的“炸场”效应,在龙年春节再次发布重磅模型。
然而,尽管春节期间的AI市场竞争激烈,DeepSeek却保持了战略耐心,让外界的期待暂时落空,这反而为V4版本的发布积累了更多关注度。
V4版本的使命:在竞争深水区实现突破
那么,即将到来的DeepSeek V4究竟承载着怎样的期待?根据多家券商研究报告分析,DeepSeek V4的亮点将聚焦于“国产化突破”与“技术创新”。分析指出,作为去年凭借DS-V3/R1系列搅动全球AI产业链的重要参与者,DeepSeek的全新技术布局不仅意在推动国内AI产业链创新周期加速,更旨在从算法与工程层面实质性缩小中美大模型产业的技术差距。
不过,行业内部也有清醒认识。此次V4的发布对DeepSeek而言挑战不小。想要复刻去年春节那般现象级的轰动效应,技术难度远超以往。原因很明确:当下的国产大模型赛道早已不是蓝海市场,而是进入了各方巨头林立、竞争白热化的“深水区”。
竞争格局演变:从价格战转向价值竞争
就在同一天,4月8日,另一家AI巨头智谱正式发布了GLM-5.1模型。值得关注的是,在年内已经涨价超过80%的基础上,智谱GLM的定价再度上调了10%。调价后,其在编程场景的缓存命中Token价格已经接近国际头部厂商Anthropic旗下Claude Sonnet 4.6的水平。
这标志着一个关键转折点:国产大模型首次在核心应用场景实现了与海外领先产品的价格对标。回想一年前,国内厂商还在以“降价90%以上”的激烈策略争夺市场份额。如今,行业风向已然转变——国产模型不再单纯依赖价格优势,而是开始凭借性能提升带来的价值溢价去锚定国际基准。这无疑是一场从“价格战”到“价值战”的深刻演变。
性能数据也支撑了这一转变。评测数据显示,GLM-5.1在编程能力上继续保持领先,在SWE-bench Pro、Terminal-Bench、NL2Repo三大代码评测基准的综合平均分中取得了全球第三、国产第一、开源第一的成绩。此外,它还有一个显著特点:区别于当前主流模型以分钟级交互为主,GLM-5.1能够在单次任务中持续、自主地工作长达8小时。
技术路径分化:智能体与自我进化能力
竞争不止于性能与定价,技术路径也在不断分化。早在3月18日,MiniMax就发布了新一代Agent旗舰大模型M2.7,首次清晰地展示了“模型自我进化”的独特技术路线。该模型通过构建一套名为Agent Harness的体系,让模型自身深度参与到训练与优化流程中。据官方介绍,在部分研发场景下,该模型可承担30%至50%的工作量,并在内部评测集上实现了约30%的效果提升。
在核心能力上,M2.7在SWE-bench Pro中取得了56.22%的成绩,已接近国际一线水平;同时在VIBE-Pro、Terminal Bench2等更贴近真实工程的测试中表现突出,支持端到端的项目交付与复杂系统理解。在办公场景,其在GDPval-AA的ELO得分达到1495,为开源模型中最高,其Office文档处理与多轮编辑能力也得到了显著增强。
市场积极回应:资本认可技术突破
市场的反应是最直接的信号。截至4月8日港股午间收盘,智谱股价大涨14.06%,报收888.5港元,市值达到3961亿港元。MiniMax股价也上涨了6.9%,报收1015港元,市值维持在3183亿港元的高位。资本的这番“用脚投票”清晰地表明了市场对国产大模型技术突破与商业价值提升的认可与期待。
可以说,DeepSeek V4的即将登场并非一场孤立的发布,而是整个国产大模型产业进入新阶段的标志性事件之一。当厂商们纷纷告别低价厮杀,转向核心技术突破与价值深耕时,一场真正关乎未来产业格局的较量才刚刚拉开序幕。




