
作者 | 白铂 博士
白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家
引言
本篇是《大模型的第一性原理》系列解读文章的第二篇(点击回顾第一篇),我们将从信号处理的角度解读原论文[1]。重点探讨语义向量化背后的信号处理和信息论原理,并从时间序列的角度分析 Transformer 及其与 Granger 因果的关系。
我们首先提出一个观点:大模型的输入是 Token 的语义嵌入(也称为语义向量),其本质是把自然语言处理问题转换为信号处理问题。因此对于大模型而言,向量化非常关键,它和信号处理、信息论有非常深刻的联系。
尽管从语言学的角度看,语法和逻辑是人类语言现象的关键,然而本系列的《统计物理篇》已经指出:大模型并不考虑这些因素,而是从纯概率的角度出发建模自然语言。
从 Token 的维度看,这种纯粹的概率模型在计算上是非常困难的,因此人们发展出了概率图模型、消息传递算法等工具[2]。对于当前海量数据而言,这些方法的复杂度仍然过高,很难用于大规模训练,也难以建模语义非对称性和长程依赖性。但是,当 Token 被向量化之后,情况就发生了本质的变化,因为我们可以定义内积,并用内积来表示语义相关性,从而大幅度降低计算量。
基于内积,我们可以进一步定义距离、微分、低维流形等一系列相对容易数值计算的量。这样就可以通过反向传播算法来训练神经网络,将 Token 的向量化变成神经网络的输入、输出和参数化记忆[3][4]。实际上,许多研究也表明神经网络之所以能完成分类,正是因为同一类事物(如照片中的猫、狗等)在高维参数空间中会内聚成低维流形[5][6]。
顺便提及,我们在向量检索方面的研究取得了一定进展,所提出的近似最近邻向量检索算法,过去两年一直蝉联 ANNBenchemarks 榜单的第一名 。
语义嵌入 / 向量化
人们用向量来建模语义的想法最早出现于 Luhn 在 1953 年发表的论文中[8]。但直到 2013 年,Mikolov 等人才真正取得突破[9][10]。基于大量语料,他们成功地训练出了将 Token 转化成语义向量的神经网络模型。下面这个例子经常被用来表达最理想的语义向量化:
其中 s (⋅) 为一个词的向量化表示。然而遗憾的是,上述理想的语义向量化当前并未完全实现,但是语义向量之间的内积(或者归一化为余弦相似性)却可以表示 Token 层面的语义相关性。

对于大模型而言,语义向量空间就可以建模为一个概率-内积空间。许多研究认为语义向量空间应该是结构更复杂的低维流形,但余弦相似性和欧式距离的实际效果就已经足够好了。因此,我们认为用单位球面 S^(M-1) 来定义语义向量空间是在效果和复杂度之间的良好平衡。需要特别强调的是,语义向量空间中的每一个向量本身并没有语义,而这个向量与其它所有向量的内积(即相对关系)才代表了语义。这一点和信息论中的信源编码有本质的区别。经典的信源编码是对每一个信源符号的压缩,而语义向量的压缩则是在相对关系近似不变的前提下,对整个语义向量空间的降维
那么,如何衡量两个语义空间的距离,以控制语义向量空间降维带来的精度损失或者衡量两个不同自然语言的语义差异性就变得至关重要。当代著名的几何学家,2009 年阿贝尔奖获得者,Mikhael Gromov 为我们提供了数学工具,即Gromov-Wasserstein 距离[12]。它衡量了两个度量 - 概率空间之间的任意两点间度量的平均差异。该定义极大地拓展了最优传输理论中的 Wasserstein 距离的应用范围[13]。据此,我们定义语义向量空间距离如下:





Transformer 是非线性时变向量自回归时间序列
在本系列的第一篇《统计物理篇》中,我们详细探讨了 Transformer 的能量模型(Energy-based Model,EBM)形式。本篇我们从信号处理角度进一步讨论 Transformer 的本质。业界已经达成共识,Transformer 是一个自回归大语言模型。这是因为它基于输入 Token 序列和已经生成的 Token 序列来预测下一个 Token。事实上,从经典随机过程和时间序列分析的角度看,自回归模型有严格的数学定义,即用过去的随机变量的值的线性加权和来预测未来的随机变量[23]。

从数学形式上看,Attention 是一个非线性时变向量自回归时间序列

来预测下一个 Token 的向量表示。在《统计物理》篇中,我们已经指出 FFN 层对于预测下一个 Token 是很重要的,它被认为是大模型储存知识的位置。基于记忆容量的思路,Attention 模块输出的向量应该会激活 FFN 层中与之最匹配的记忆模式,从而作为下一个 Token 的向量表示。后续的操作需要在离散的词表中选择最有可能的那个 Token。在实际中可以设计多种采样策略来满足输出的要求,但背后的原理与通信接收机中的最大似然译码很类似。


因此,从时间序列的角度看,大模型输入的 Token 序列和输出的 Token 序列符合 Granger 因果推断的定义。这进一步印证了第一篇的结论:大模型推理的本质,是通过预测下一个 Token 这一看似简单的训练目标,进而实现逼近人类水平的 Granger 因果推断
信号处理与信息论
在引言中我们已经指出:大模型处理的是向量化后的 Token 序列,其本质是把传统基于概率的自然语言处理问题转换成了基于数值计算的信号处理问题。从本文的讨论中可以看到,这种从 Token 到其向量表示的转化,与信息论和信号处理之间的关系非常类似。
具体来说,Shannon 信息论是一个基于概率论的理论框架,旨在理解信息压缩、传输和存储的基本原理及其性能极限,但它并不关注工程中的具体实现方法和复杂度。信号处理将信息论中的抽象符号表示为 n 维实 / 复空间中的向量。这种表示使得数值计算方法能有效应用于感知、通信和存储系统的高效算法设计中。可以说,信号处理是信息论原理在特定计算架构下的具体实现。
更广泛地看,我们经常用下图来表达计算理论和信息论之间的关系。图的左边是 Turing 和他的计算理论,他关心用多少个步骤能完成特定的计算,因此时延(通常用时间复杂度来度量)是最关键的指标。图的右边是 Shannon 和他的信息论,他关心的是通信速率的上限或者数据压缩的下限,即存在性和可达性。此时,通常假设码长趋于无穷大,因而时延是被忽略的。那么在实践中就会发现,开发通信算法的瓶颈永远是算力不够,算法复杂度太高;而研究计算算法的瓶颈永远都是(访存 / 卡间 / 服务器间)通信带宽不够,或者缓存 / 内存空间太小。
我们注意到,尽管计算理论和信息论有本质的不同,但他们最基本的操作单位都是 BIT,因此我们可以肯定地说:BIT 是连接计算和通信这两大领域的桥梁
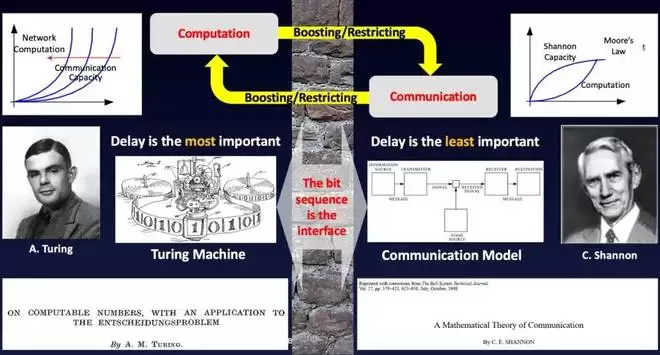
图:BIT 是连接计算理论和信息论的桥梁,是信息时代最伟大的发明。
正如 5G Polar 码发明人,2019 年香农奖得主,Erdal Arikan 教授参加我们的圆桌论坛中所指出的:BIT 是信息时代最伟大的发明。Shannon 在与 Weaver 合著的论文中也明确指出:信息论只解决了信息的可靠传输问题,即技术问题,而不考虑语义和语效[26]。但是人类已经进入了 AI 时代,信息论是否还能继续发挥其基础性作用?
我们将在本系列的第三篇《信息论篇》中看到,只要将核心概念从信息时代的 BIT 转换成 AI 时代的 TOKEN,Shannon 信息论就可以用来解释大模型背后的数学原理。
参考文献
1. B. Bai, "Forget BIT, it is all about TOKEN: Towards semantic information theory for LLMs," arXiv:2511.01202, Nov. 2025.
2. D. Koller and N. Friedman, Probabilistic Graphical Models: Principles and Techniques. Cambridge, MA, USA: The MIT Press, 2009.
3. G. Hinton, "Learning distributed representations of concepts," in Proc. 8th Annual Conference on Cognitive Science Society ’86, Amherst, MA, USA, Aug. 1986.
4. Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin, "A neural probabilistic language model," Journal of Machine Learning Research, vol. 3, no. 2, pp. 1137-1155, Feb. 2003.
5. S. Chung, D. Lee, and H. Sompolinsky, "Classification and geometry of general perceptual manifolds," Physical Review X, vol. 8, no. 3, p. 031003, Jul. 2018.
6. Y. Bahri, J. Kadmon, J. Pennington, S. Schoenholz, J. Sohl-Dickstein, and S. Ganguli, "Statistical mechanics of deep learning," Annual Review of Condensed Matter Physics, vol. 11, no. 3, pp. 501-528, Mar. 2020.
7. https://ann-benchmarks.com
8. H. Luhn, "A new method of recording and searching information," American Documentation, vol. 4, no. 1, pp. 14–16, Jan. 1953.
9. T. Mikolov, K. Chen, G. Corrado, and J. Dean, "Efficient estimation of word representations in vector space," arXiv: 1301.3781, 7 Sep. 2013.
10. T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, "Distributed representations of words and phrases and their compositionality," Proc. 27th Annual Conference on Neural Information Processing Systems '13, Lake Tahoe, NV, USA, Dec. 2013.
11. D. Jurafsky and J. Martin, Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition with Language Models, 3rd ed. Draft, 2025.
12. M. Gromov, Metric Structures for Riemannian and Non-Riemannian Spaces. Boston, MA, USA: Birkhäuser, 2007.
13. C. Villani, Optimal Transport: Old and New. New York, NY, USA: Springer, 2009.
14. D. Alvarez-Melis and T. Jaakkola, "Gromov-Wasserstein alignment of word embedding spaces," in Proc. ACL Conference on Empirical Methods in Natural Language Processing ’18, Brussels, Belgium, Oct. 2018, pp. 1881–1890.
15. T. Landauer, P. Foltz, and D. Laham, "An introduction to latent semantic analysis," Discourse Processes, vol. 25, no. 2-3, pp. 259-284, Jan. 1998.
16. W. Johnson, J. Lindenstrauss, and G. Schechtman, "Extensions of Lipschitz maps into Banach spaces," Israel Journal of Mathematics, vol. 54, no. 2, pp. 129-138, Jun. 1986.
17. A. Oord, Y. Li, and O. Vinyals, "Representation learning with contrastive predictive coding," arXiv: 1807.03748, Jan. 2019.
18. P. Elias, "Predictive coding - Part 1," IRE Transactions on Information Theory, vol. 1, no. 1, pp. 16-24, Mar. 1955.
19. P. Elias, "Predictive coding - Part 2," IRE Transactions on Information Theory, vol. 1, no. 1, pp. 24-33, Mar. 1955.
20. B. Poole, S. Ozair, A. Oord, A. Alemi, and G. Tucker, "On variational bounds of mutual information," in Proc. 36th International Conference on Machine Learning ’19, Long Beach, CA, USA, Jun. 2019, pp. 5171-5180.
21. J. Massey, "Causality, feedback and directed information," in Proc. IEEE International Symposium on Information Theory ’90, Waikiki, HI, USA, Nov. 1990.
22. S. Peng, Nonlinear Expectations and Stochastic Calculus under Uncertainty: with Robust CLT and G-Brownian Motion. Berlin, Germany: Springer, 2019.
23. H. Lütkepohl, New Introduction to Multiple Time Series Analysis. Berlin, Germany: Springer, 2007.
24. H. Ramsauer et al., "Hopfield networks is all you need," arXiv: 2008.02217, Apr. 2024.
25. Y. Xia et al., "ER-RAG: Enhance RAG with ER-based unified modeling of heterogeneous data sources," arXiv: 2504.06271, Mar. 2025.
26. W. Weaver and C. Shannon, "Recent contributions to the mathematical theory of communications," The Rockefeller Foundation, Sep. 1949.