DeepSeek挑战Transformer记忆?查表法重塑模型架构新思路

免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:LRST
【新智元导读】ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
近年来,随着大模型规模与知识密度的持续爆发,研究人员开始重新审视一个底层问题:模型的参数究竟该如何组织,才能最高效地承担「记忆」的功能?
在传统的Transformer架构中,前馈神经网络(FFN)的知识通常隐式地埋藏在up-projection等密集矩阵内 。这种通过输入进行动态激活的矩阵乘法,虽然保证了表达能力,却在参数的可寻址性、后期可编辑性以及系统计算效率上存在着天然的局限 。
为了突破这一瓶颈,学术界和工业界逐渐转向更离散、更结构化的参数组织路径。
近期DeepSeek推出的engram机制成功引爆了业内对「查表式记忆(lookup-based memory)」的关注 。但令人瞩目的是,早于engram问世约三个月前,一篇入选 ICLR 的论文就已经对该方向进行了极其系统的探索 。

项目主页: https://infini-ai-lab.github.io/STEM/
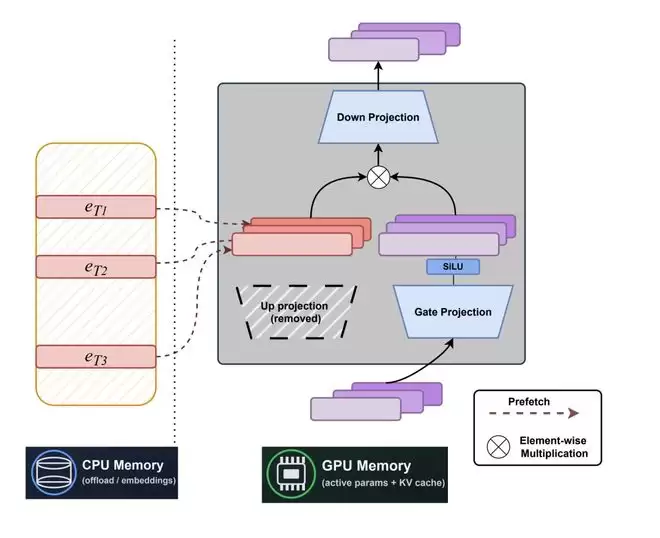
与传统的混合专家模型(MoE)在现有稀疏路由上做修补不同,STEM(Scaling Transformers with Embedding Modules)选择直接对 FFN 结构「动刀」:它摒弃了动态运行时的路由机制,将 up-projection 替换为按token索引的层级 embedding 表,以一种纯静态的方式重构了 Transformer 的记忆访问路径 。
从「算地址」到「查地址」
如果用「键值对记忆(key-value memory)」的视角来审视标准 Transformer,像 SwiGLU 这样的 FFN 结构,本质上是通过一次 up-projection 将输入映射到高维空间,从而生成一个能被 gate 调制的「地址向量」 。这一过程极其依赖输入相关的密集矩阵乘法,不仅计算昂贵,而且参数高度耦合 。
STEM 团队提出了一个灵魂拷问:如果 FFN 的核心作用只是「按token访问记忆」,我们真的需要每次都动态计算这些地址向量吗?
基于此,STEM给出了一种极致简单直接的解法:
彻底移除up-projection,不再动态计算地址向量 。
为模型的每一层单独维护一个按token索引的embedding表。
在前向传播时,直接根据token id 「查表」,提取对应的静态向量 作为原先的 。
完整保留gate与down-projection模块,用于对查表得到的向量进行上下文的压缩与调制 。
这一看似轻量的模块替换,实现了一个极其本质的架构跨越:模型的「记忆容量」终于与「单token的计算量」实现了彻底解耦。
连锁效应
四大维度的全面跃升
虽然仅仅替换了FFN的一个子模块,STEM 却在实验中展现出了惊人的全方位优势 :
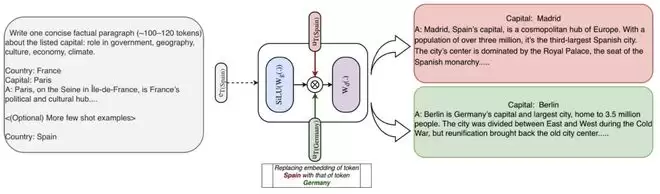
1. 即插即用的「知识编辑」
这是STEM最硬核的特性之一 。因为每一层的embedding都与特定token id强绑定,研究人员甚至不需要重新训练,只需替换特定token的STEM向量,就能直接修改模型输出的事实 。
例如,仅通过互换「Spain」与「Germany」的向量,模型在回答首都问题时就会发生相应的改变 。这为未来的模型内部机制理解与知识编辑打开了全新大门 。
2. 训练极度稳定(告别动态路由的烦恼)
与依赖运行时路由的MoE不同,STEM是一种静态稀疏架构 。由于每个token在每一层访问的 embedding 都是恒定确定的,它完美避开了MoE训练中令人头疼的负载倾斜(load skew)和损失突刺(loss spike)问题,且不需要任何all-to-all通信 。
3. 更宽广的「记忆空间」
从几何空间分布来看,STEM 的 embedding 表展现出了更大的角度散布(large angular spread) 。这意味着不同token 的向量更趋近于正交,大幅减少了参数间的相互干扰(cross-talk) 。在同等算力下,模型能塞下更多「可寻址的记忆槽位」 。
4. 计算与I/O双重减负
砍掉up-projection后,每一层都能省下庞大的矩阵乘法开销(约级别) 。更妙的是,庞大的embedding表完全可以离载(offload)到 CPU 内存中,配合异步预取(prefetch)和缓存策略高效运行 。
实验与落地
长上下文表现亮眼
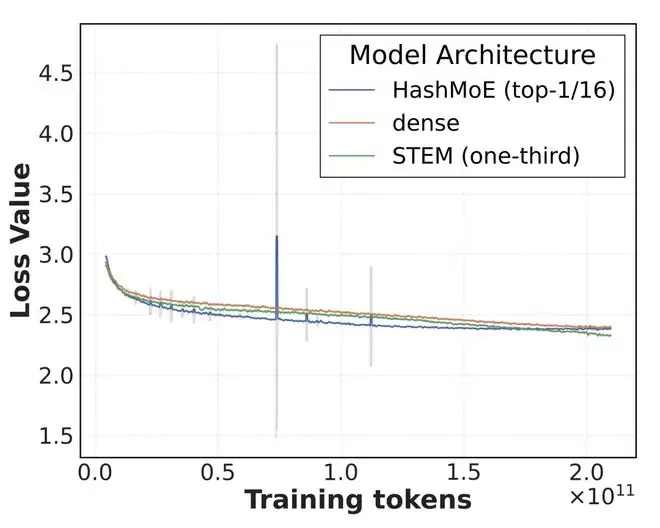
团队在350M和1B规模的模型上对 STEM 进行了严密的消融实验 。数据表明,STEM 相比于 dense 架构基线,整体平均性能提升了约3–4%,在部分知识密集型任务上,提升幅度甚至飙升至9–10% 。特别是在大海捞针(Needle-in-a-Haystack)和LongBench等长文本评测中,上下文越长,STEM的优势就越显著。
对于工程落地,论文也给出了避坑指南:
替换讲究位置:核心在于替换up-projection,如果盲目替换gate-projection,反而会破坏模型的上下文调制能力 。
优化存储与显存:embedding表可放在CPU,但在训练时需注意将梯度写回对应的优化器状态 。在追求极致性价比时,还可以采用「部分层替换」或混合变体策略来平衡显存压力 。
结语
STEM架构向我们清晰地传达了一个信号:在无脑堆叠算力和参数量之外,通过巧妙重构参数的「组织方式」,我们依然能够榨取巨大的性能红利。 在当前基座大模型越发庞大复杂的语境下,STEM这种简洁、优雅且工程友好的设计,无疑是下一代模型演进路线上的一座重要灯塔
作者介绍
论文第一作者Ranajoy Sadhukhan为卡内基梅隆大学(CMU)InfiniAI Lab 博士生,师从陈贝迪教授。该工作完成于其在 Meta AI 实习期间,实习导师包括刘泽春、曹晟(Rick Cao)与田渊栋等研究人员。
InfiniAI Lab 由陈贝迪教授创立,致力于模型、系统与硬件协同设计,研究高效且可扩展的 AI 算法与系统,重点方向包括长上下文多模态建模、突破传统 scaling laws 的新一代模型架构,以及基础模型的理解与推理能力增强,同时推动算法与系统层面的效率优化,以促进 AI 技术的普及化。
刘泽春为Meta AI 研究科学家,研究方向涵盖基座模型训练,大模型压缩、稀疏化与端侧部署优化,专注于模型高效推理与系统协同设计。
曹晟(Rick Cao)为 Meta AI 研究员,主要研究大模型系统优化与高效推理架构设计,关注大规模模型在真实系统环境中的部署与加速问题。
田渊栋为 Meta AI 资深研究科学家,长期从事强化学习与大模型研究,曾参与 AlphaZero 等强化学习系统研发,并关注基础模型的推理与决策能力。
参考资料:
https://infini-ai-lab.github.io/STEM/
热门专题







热门推荐

主流币与山寨币在市值、技术、共识和风险上差异显著。主流币市值巨大、流动性强,技术经过长期验证,拥有全球共识和明确应用场景,适合长期配置。山寨币则市值小、流动性差,技术基础薄弱且缺乏审计,共识脆弱且多依赖炒作,价格波动剧烈且归零风险高,属于高风险投机标的。

进行Bitget身份认证时,除了正确上传照片,证件本身的清晰度至关重要。模糊、反光或信息不全的图片会直接导致审核失败。此外,认证申请提交后的等待时间受平台审核队列、资料完整度及网络状况等多重因素影响,高峰期可能延长。建议用户确保在光线均匀环境下拍摄高清证件照,并耐心等待系统处理,以提升一次性通过率。

本文详细介绍了Bitget交易所在不同设备上的下载与访问方法。安卓用户可通过官方应用商店或APK文件安装,需注意权限设置。iPhone用户需切换至非中国大陆AppStore账户下载官方App。网页端则提供最直接的访问方式,无需安装,但务必核对网址安全性。文章还补充了常见问题与安全建议,帮助用户顺利完成平台使用前的准备工作。

对于初次接触Bitget的新用户,从注册到完成第一笔交易,平台提供了一条清晰的操作路径。关键在于完成账户注册与安全设置,包括身份验证和资金密码。随后,通过法币入金通道为账户注入启动资金,并熟悉现货交易界面的基本操作。最后,在模拟交易中实践后,即可尝试小额真实交易,完成从入门到实操的完整闭环。

对于初次接触Bitget这类专业交易平台的新用户来说,感到无从下手是普遍现象。关键在于熟悉核心功能区的布局,特别是资产总览、现货交易、合约交易、资金划转、订单管理和个人设置这六个关键页面。掌握它们的位置和基本逻辑,就能快速理清平台操作脉络,大幅提升使用效率,避免在基础操作上耗费过多时间。